Corrmotif Conc Analysis
Last updated: 2025-06-26
Checks: 6 1
Knit directory: CX5461_Project/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20250129) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version c34034d. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: 0.1 box.svg
Ignored: Rplot04.svg
Untracked files:
Untracked: 0.1 density.svg
Untracked: 0.1.emf
Untracked: 0.1.svg
Untracked: 0.5 box.svg
Untracked: 0.5 density.svg
Untracked: 0.5.svg
Untracked: Additional/
Untracked: Autosome factors.svg
Untracked: CX_5461_Pattern_Genes_24hr.csv
Untracked: CX_5461_Pattern_Genes_3hr.csv
Untracked: Cell viability box plot.svg
Untracked: DEG GO terms.svg
Untracked: DNA damage associated GO terms.svg
Untracked: DRC1.svg
Untracked: Figure 1.jpeg
Untracked: Figure 1.pdf
Untracked: Figure_CM_Purity.pdf
Untracked: G Quadruplex DEGs.svg
Untracked: PC2 Vs PC3 Autosome.svg
Untracked: PCA autosome.svg
Untracked: Rplot 18.svg
Untracked: Rplot.svg
Untracked: Rplot01.svg
Untracked: Rplot02.svg
Untracked: Rplot03.svg
Untracked: Rplot05.svg
Untracked: Rplot06.svg
Untracked: Rplot07.svg
Untracked: Rplot08.jpeg
Untracked: Rplot08.svg
Untracked: Rplot09.svg
Untracked: Rplot10.svg
Untracked: Rplot11.svg
Untracked: Rplot12.svg
Untracked: Rplot13.svg
Untracked: Rplot14.svg
Untracked: Rplot15.svg
Untracked: Rplot16.svg
Untracked: Rplot17.svg
Untracked: Rplot18.svg
Untracked: Rplot19.svg
Untracked: Rplot20.svg
Untracked: Rplot21.svg
Untracked: Rplot22.svg
Untracked: Rplot23.svg
Untracked: Rplot24.svg
Untracked: TOP2B.bed
Untracked: TS HPA (Violin).svg
Untracked: TS HPA.svg
Untracked: TS_HA.svg
Untracked: TS_HV.svg
Untracked: Violin HA.svg
Untracked: Violin HV (CX vs DOX).svg
Untracked: Violin HV.svg
Untracked: data/AF.csv
Untracked: data/AF_Mapped.csv
Untracked: data/AF_genes.csv
Untracked: data/Annotated_DOX_Gene_Table.csv
Untracked: data/BP/
Untracked: data/CAD_genes.csv
Untracked: data/Cardiotox.csv
Untracked: data/Cardiotox_mapped.csv
Untracked: data/Col_DEG_proportion_data.csv
Untracked: data/Col_DEGs.csv
Untracked: data/Corrmotif_GO/
Untracked: data/DOX_Vald.csv
Untracked: data/DOX_Vald_Mapped.csv
Untracked: data/DOX_alt.csv
Untracked: data/Entrez_Cardiotox.csv
Untracked: data/Entrez_Cardiotox_Mapped.csv
Untracked: data/GWAS.xlsx
Untracked: data/GWAS_SNPs.bed
Untracked: data/HF.csv
Untracked: data/HF_Mapped.csv
Untracked: data/HF_genes.csv
Untracked: data/Hypertension_genes.csv
Untracked: data/MI_genes.csv
Untracked: data/P53_Target_mapped.csv
Untracked: data/Sample_annotated.csv
Untracked: data/Samples.csv
Untracked: data/Samples.xlsx
Untracked: data/TOP2A.bed
Untracked: data/TOP2A_target.csv
Untracked: data/TOP2A_target_lit.csv
Untracked: data/TOP2A_target_lit_mapped.csv
Untracked: data/TOP2A_target_mapped.csv
Untracked: data/TOP2B.bed
Untracked: data/TOP2B_target.csv
Untracked: data/TOP2B_target_heatmap.csv
Untracked: data/TOP2B_target_heatmap_mapped.csv
Untracked: data/TOP2B_target_mapped.csv
Untracked: data/TS.csv
Untracked: data/TS_HPA.csv
Untracked: data/TS_HPA_mapped.csv
Untracked: data/Toptable_CX_0.1_24.csv
Untracked: data/Toptable_CX_0.1_3.csv
Untracked: data/Toptable_CX_0.1_48.csv
Untracked: data/Toptable_CX_0.5_24.csv
Untracked: data/Toptable_CX_0.5_3.csv
Untracked: data/Toptable_CX_0.5_48.csv
Untracked: data/Toptable_DOX_0.1_24.csv
Untracked: data/Toptable_DOX_0.1_3.csv
Untracked: data/Toptable_DOX_0.1_48.csv
Untracked: data/Toptable_DOX_0.5_24.csv
Untracked: data/Toptable_DOX_0.5_3.csv
Untracked: data/Toptable_DOX_0.5_48.csv
Untracked: data/count.tsv
Untracked: data/heatmap.csv
Untracked: data/ts_data_mapped
Untracked: results/
Untracked: run_bedtools.bat
Unstaged changes:
Deleted: analysis/Actox.Rmd
Modified: analysis/Corrmotif_Conc.Rmd
Modified: data/DEGs/Toptable_DOX_0.5_3.csv
Modified: data/DOX_0.5_48 (Combined).csv
Modified: data/Total_number_of_Mapped_reads_by_Individuals.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/Corrmotif_Conc.Rmd) and
HTML (docs/Corrmotif_Conc.html) files. If you’ve configured
a remote Git repository (see ?wflow_git_remote), click on
the hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c34034d | sayanpaul01 | 2025-06-26 | Commit |
| html | c34034d | sayanpaul01 | 2025-06-26 | Commit |
| Rmd | 044878a | sayanpaul01 | 2025-06-06 | Commit |
| html | 305a6c0 | sayanpaul01 | 2025-06-06 | Commit |
| Rmd | a77ea96 | sayanpaul01 | 2025-05-16 | Commit |
| html | a77ea96 | sayanpaul01 | 2025-05-16 | Commit |
| html | e29b0ca | sayanpaul01 | 2025-05-15 | Commit |
| Rmd | 01a423f | sayanpaul01 | 2025-05-15 | Commit |
| html | 01a423f | sayanpaul01 | 2025-05-15 | Commit |
| Rmd | 1661001 | sayanpaul01 | 2025-05-08 | Commit |
| html | 1661001 | sayanpaul01 | 2025-05-08 | Commit |
| Rmd | b9a2867 | sayanpaul01 | 2025-05-05 | Commit |
| html | b9a2867 | sayanpaul01 | 2025-05-05 | Commit |
| Rmd | 10ab0f3 | sayanpaul01 | 2025-05-05 | Commit |
| html | 10ab0f3 | sayanpaul01 | 2025-05-05 | Commit |
| Rmd | da5bc51 | sayanpaul01 | 2025-05-04 | Commit |
| html | da5bc51 | sayanpaul01 | 2025-05-04 | Commit |
| Rmd | 6f9e594 | sayanpaul01 | 2025-04-24 | Commit |
| html | 6f9e594 | sayanpaul01 | 2025-04-24 | Commit |
| Rmd | d6226a0 | sayanpaul01 | 2025-04-24 | Commit |
| html | d6226a0 | sayanpaul01 | 2025-04-24 | Commit |
| Rmd | 062a73a | sayanpaul01 | 2025-04-24 | Commit |
| html | 062a73a | sayanpaul01 | 2025-04-24 | Commit |
| html | 07b9670 | sayanpaul01 | 2025-04-21 | Commit |
| html | 9618a00 | sayanpaul01 | 2025-04-21 | Commit |
| html | 008117a | sayanpaul01 | 2025-04-14 | Build site. |
| html | 1433d37 | sayanpaul01 | 2025-04-14 | Commit |
| Rmd | 4bad905 | sayanpaul01 | 2025-04-14 | Commit |
| html | 4bad905 | sayanpaul01 | 2025-04-14 | Commit |
| Rmd | 6ef5f61 | sayanpaul01 | 2025-04-14 | Commit |
| html | 6ef5f61 | sayanpaul01 | 2025-04-14 | Commit |
| Rmd | d8a2f25 | sayanpaul01 | 2025-04-14 | Commit |
| html | d8a2f25 | sayanpaul01 | 2025-04-14 | Commit |
| Rmd | a568872 | sayanpaul01 | 2025-04-10 | Commit |
| html | a568872 | sayanpaul01 | 2025-04-10 | Commit |
| Rmd | 4e40091 | sayanpaul01 | 2025-04-07 | Commit |
| html | 4e40091 | sayanpaul01 | 2025-04-07 | Commit |
| Rmd | aab6b9f | sayanpaul01 | 2025-04-07 | Commit |
| html | aab6b9f | sayanpaul01 | 2025-04-07 | Commit |
| Rmd | 2990b21 | sayanpaul01 | 2025-03-10 | Commit |
| html | 2990b21 | sayanpaul01 | 2025-03-10 | Commit |
| Rmd | ef3a951 | sayanpaul01 | 2025-03-09 | Commit |
| html | ef3a951 | sayanpaul01 | 2025-03-09 | Commit |
| Rmd | 81247f6 | sayanpaul01 | 2025-03-06 | Commit |
| html | 81247f6 | sayanpaul01 | 2025-03-06 | Commit |
| Rmd | 96d0db1 | sayanpaul01 | 2025-03-05 | Commit |
| html | 96d0db1 | sayanpaul01 | 2025-03-05 | Commit |
| Rmd | 91a7ce4 | sayanpaul01 | 2025-03-03 | Commit |
| html | 91a7ce4 | sayanpaul01 | 2025-03-03 | Commit |
| Rmd | d9ff853 | sayanpaul01 | 2025-03-03 | Commit |
| html | d9ff853 | sayanpaul01 | 2025-03-03 | Commit |
| Rmd | 2de67e6 | sayanpaul01 | 2025-02-27 | Commit |
| html | 2de67e6 | sayanpaul01 | 2025-02-27 | Commit |
| Rmd | 41cd1be | sayanpaul01 | 2025-02-27 | Commit |
| html | 41cd1be | sayanpaul01 | 2025-02-27 | Commit |
| Rmd | f84821f | sayanpaul01 | 2025-02-26 | Commit |
| Rmd | b6e38a1 | sayanpaul01 | 2025-02-25 | Commit |
| html | b6e38a1 | sayanpaul01 | 2025-02-25 | Commit |
| Rmd | ce4b325 | sayanpaul01 | 2025-02-25 | Commit |
| html | ce4b325 | sayanpaul01 | 2025-02-25 | Commit |
📌 0.1 Micromolar
📌 Fit Limma Model Functions
## Fit limma model using code as it is found in the original cormotif code. It has
## only been modified to add names to the matrix of t values, as well as the
## limma fits
limmafit.default <- function(exprs,groupid,compid) {
limmafits <- list()
compnum <- nrow(compid)
genenum <- nrow(exprs)
limmat <- matrix(0,genenum,compnum)
limmas2 <- rep(0,compnum)
limmadf <- rep(0,compnum)
limmav0 <- rep(0,compnum)
limmag1num <- rep(0,compnum)
limmag2num <- rep(0,compnum)
rownames(limmat) <- rownames(exprs)
colnames(limmat) <- rownames(compid)
names(limmas2) <- rownames(compid)
names(limmadf) <- rownames(compid)
names(limmav0) <- rownames(compid)
names(limmag1num) <- rownames(compid)
names(limmag2num) <- rownames(compid)
for(i in 1:compnum) {
selid1 <- which(groupid == compid[i,1])
selid2 <- which(groupid == compid[i,2])
eset <- new("ExpressionSet", exprs=cbind(exprs[,selid1],exprs[,selid2]))
g1num <- length(selid1)
g2num <- length(selid2)
designmat <- cbind(base=rep(1,(g1num+g2num)), delta=c(rep(0,g1num),rep(1,g2num)))
fit <- lmFit(eset,designmat)
fit <- eBayes(fit)
limmat[,i] <- fit$t[,2]
limmas2[i] <- fit$s2.prior
limmadf[i] <- fit$df.prior
limmav0[i] <- fit$var.prior[2]
limmag1num[i] <- g1num
limmag2num[i] <- g2num
limmafits[[i]] <- fit
# log odds
# w<-sqrt(1+fit$var.prior[2]/(1/g1num+1/g2num))
# log(0.99)+dt(fit$t[1,2],g1num+g2num-2+fit$df.prior,log=TRUE)-log(0.01)-dt(fit$t[1,2]/w, g1num+g2num-2+fit$df.prior, log=TRUE)+log(w)
}
names(limmafits) <- rownames(compid)
limmacompnum<-nrow(compid)
result<-list(t = limmat,
v0 = limmav0,
df0 = limmadf,
s20 = limmas2,
g1num = limmag1num,
g2num = limmag2num,
compnum = limmacompnum,
fits = limmafits)
}
limmafit.counts <-
function (exprs, groupid, compid, norm.factor.method = "TMM", voom.normalize.method = "none")
{
limmafits <- list()
compnum <- nrow(compid)
genenum <- nrow(exprs)
limmat <- matrix(NA,genenum,compnum)
limmas2 <- rep(0,compnum)
limmadf <- rep(0,compnum)
limmav0 <- rep(0,compnum)
limmag1num <- rep(0,compnum)
limmag2num <- rep(0,compnum)
rownames(limmat) <- rownames(exprs)
colnames(limmat) <- rownames(compid)
names(limmas2) <- rownames(compid)
names(limmadf) <- rownames(compid)
names(limmav0) <- rownames(compid)
names(limmag1num) <- rownames(compid)
names(limmag2num) <- rownames(compid)
for (i in 1:compnum) {
message(paste("Running limma for comparision",i,"/",compnum))
selid1 <- which(groupid == compid[i, 1])
selid2 <- which(groupid == compid[i, 2])
# make a new count data frame
counts <- cbind(exprs[, selid1], exprs[, selid2])
# remove NAs
not.nas <- which(apply(counts, 1, function(x) !any(is.na(x))) == TRUE)
# runn voom/limma
d <- DGEList(counts[not.nas,])
d <- calcNormFactors(d, method = norm.factor.method)
g1num <- length(selid1)
g2num <- length(selid2)
designmat <- cbind(base = rep(1, (g1num + g2num)), delta = c(rep(0,
g1num), rep(1, g2num)))
y <- voom(d, designmat, normalize.method = voom.normalize.method)
fit <- lmFit(y, designmat)
fit <- eBayes(fit)
limmafits[[i]] <- fit
limmat[not.nas, i] <- fit$t[, 2]
limmas2[i] <- fit$s2.prior
limmadf[i] <- fit$df.prior
limmav0[i] <- fit$var.prior[2]
limmag1num[i] <- g1num
limmag2num[i] <- g2num
}
limmacompnum <- nrow(compid)
names(limmafits) <- rownames(compid)
result <- list(t = limmat,
v0 = limmav0,
df0 = limmadf,
s20 = limmas2,
g1num = limmag1num,
g2num = limmag2num,
compnum = limmacompnum,
fits = limmafits)
}
limmafit.list <-
function (fitlist, cmp.idx=2)
{
compnum <- length(fitlist)
genes <- c()
for (i in 1:compnum) genes <- unique(c(genes, rownames(fitlist[[i]])))
genenum <- length(genes)
limmat <- matrix(NA,genenum,compnum)
limmas2 <- rep(0,compnum)
limmadf <- rep(0,compnum)
limmav0 <- rep(0,compnum)
limmag1num <- rep(0,compnum)
limmag2num <- rep(0,compnum)
rownames(limmat) <- genes
colnames(limmat) <- names(fitlist)
names(limmas2) <- names(fitlist)
names(limmadf) <- names(fitlist)
names(limmav0) <- names(fitlist)
names(limmag1num) <- names(fitlist)
names(limmag2num) <- names(fitlist)
for (i in 1:compnum) {
this.t <- fitlist[[i]]$t[,cmp.idx]
limmat[names(this.t),i] <- this.t
limmas2[i] <- fitlist[[i]]$s2.prior
limmadf[i] <- fitlist[[i]]$df.prior
limmav0[i] <- fitlist[[i]]$var.prior[cmp.idx]
limmag1num[i] <- sum(fitlist[[i]]$design[,cmp.idx]==0)
limmag2num[i] <- sum(fitlist[[i]]$design[,cmp.idx]==1)
}
limmacompnum <- compnum
result <- list(t = limmat,
v0 = limmav0,
df0 = limmadf,
s20 = limmas2,
g1num = limmag1num,
g2num = limmag2num,
compnum = limmacompnum,
fits = limmafits)
}
## Rank genes based on statistics
generank<-function(x) {
xcol<-ncol(x)
xrow<-nrow(x)
result<-matrix(0,xrow,xcol)
z<-(1:1:xrow)
for(i in 1:xcol) {
y<-sort(x[,i],decreasing=TRUE,na.last=TRUE)
result[,i]<-match(x[,i],y)
result[,i]<-order(result[,i])
}
result
}
## Log-likelihood for moderated t under H0
modt.f0.loglike<-function(x,df) {
a<-dt(x, df, log=TRUE)
result<-as.vector(a)
flag<-which(is.na(result)==TRUE)
result[flag]<-0
result
}
## Log-likelihood for moderated t under H1
## param=c(df,g1num,g2num,v0)
modt.f1.loglike<-function(x,param) {
df<-param[1]
g1num<-param[2]
g2num<-param[3]
v0<-param[4]
w<-sqrt(1+v0/(1/g1num+1/g2num))
dt(x/w, df, log=TRUE)-log(w)
a<-dt(x/w, df, log=TRUE)-log(w)
result<-as.vector(a)
flag<-which(is.na(result)==TRUE)
result[flag]<-0
result
}
## Correlation Motif Fit
cmfit.X<-function(x, type, K=1, tol=1e-3, max.iter=100) {
## initialize
xrow <- nrow(x)
xcol <- ncol(x)
loglike0 <- list()
loglike1 <- list()
p <- rep(1, K)/K
q <- matrix(runif(K * xcol), K, xcol)
q[1, ] <- rep(0.01, xcol)
for (i in 1:xcol) {
f0 <- type[[i]][[1]]
f0param <- type[[i]][[2]]
f1 <- type[[i]][[3]]
f1param <- type[[i]][[4]]
loglike0[[i]] <- f0(x[, i], f0param)
loglike1[[i]] <- f1(x[, i], f1param)
}
condlike <- list()
for (i in 1:xcol) {
condlike[[i]] <- matrix(0, xrow, K)
}
loglike.old <- -1e+10
for (i.iter in 1:max.iter) {
if ((i.iter%%50) == 0) {
print(paste("We have run the first ", i.iter, " iterations for K=",
K, sep = ""))
}
err <- tol + 1
clustlike <- matrix(0, xrow, K)
#templike <- matrix(0, xrow, 2)
templike1 <- rep(0, xrow)
templike2 <- rep(0, xrow)
for (j in 1:K) {
for (i in 1:xcol) {
templike1 <- log(q[j, i]) + loglike1[[i]]
templike2 <- log(1 - q[j, i]) + loglike0[[i]]
tempmax <- Rfast::Pmax(templike1, templike2)
templike1 <- exp(templike1 - tempmax)
templike2 <- exp(templike2 - tempmax)
tempsum <- templike1 + templike2
clustlike[, j] <- clustlike[, j] + tempmax +
log(tempsum)
condlike[[i]][, j] <- templike1/tempsum
}
clustlike[, j] <- clustlike[, j] + log(p[j])
}
#tempmax <- apply(clustlike, 1, max)
tempmax <- Rfast::rowMaxs(clustlike, value=TRUE)
for (j in 1:K) {
clustlike[, j] <- exp(clustlike[, j] - tempmax)
}
#tempsum <- apply(clustlike, 1, sum)
tempsum <- Rfast::rowsums(clustlike)
for (j in 1:K) {
clustlike[, j] <- clustlike[, j]/tempsum
}
#p.new <- (apply(clustlike, 2, sum) + 1)/(xrow + K)
p.new <- (Rfast::colsums(clustlike) + 1)/(xrow + K)
q.new <- matrix(0, K, xcol)
for (j in 1:K) {
clustpsum <- sum(clustlike[, j])
for (i in 1:xcol) {
q.new[j, i] <- (sum(clustlike[, j] * condlike[[i]][,
j]) + 1)/(clustpsum + 2)
}
}
err.p <- max(abs(p.new - p)/p)
err.q <- max(abs(q.new - q)/q)
err <- max(err.p, err.q)
loglike.new <- (sum(tempmax + log(tempsum)) + sum(log(p.new)) +
sum(log(q.new) + log(1 - q.new)))/xrow
p <- p.new
q <- q.new
loglike.old <- loglike.new
if (err < tol) {
break
}
}
clustlike <- matrix(0, xrow, K)
for (j in 1:K) {
for (i in 1:xcol) {
templike1 <- log(q[j, i]) + loglike1[[i]]
templike2 <- log(1 - q[j, i]) + loglike0[[i]]
tempmax <- Rfast::Pmax(templike1, templike2)
templike1 <- exp(templike1 - tempmax)
templike2 <- exp(templike2 - tempmax)
tempsum <- templike1 + templike2
clustlike[, j] <- clustlike[, j] + tempmax + log(tempsum)
condlike[[i]][, j] <- templike1/tempsum
}
clustlike[, j] <- clustlike[, j] + log(p[j])
}
#tempmax <- apply(clustlike, 1, max)
tempmax <- Rfast::rowMaxs(clustlike, value=TRUE)
for (j in 1:K) {
clustlike[, j] <- exp(clustlike[, j] - tempmax)
}
#tempsum <- apply(clustlike, 1, sum)
tempsum <- Rfast::rowsums(clustlike)
for (j in 1:K) {
clustlike[, j] <- clustlike[, j]/tempsum
}
p.post <- matrix(0, xrow, xcol)
for (j in 1:K) {
for (i in 1:xcol) {
p.post[, i] <- p.post[, i] + clustlike[, j] * condlike[[i]][,
j]
}
}
loglike.old <- loglike.old - (sum(log(p)) + sum(log(q) +
log(1 - q)))/xrow
loglike.old <- loglike.old * xrow
result <- list(p.post = p.post, motif.prior = p, motif.q = q,
loglike = loglike.old, clustlike=clustlike, condlike=condlike)
}
## Fit using (0,0,...,0) and (1,1,...,1)
cmfitall<-function(x, type, tol=1e-3, max.iter=100) {
## initialize
xrow<-nrow(x)
xcol<-ncol(x)
loglike0<-list()
loglike1<-list()
p<-0.01
## compute loglikelihood
L0<-matrix(0,xrow,1)
L1<-matrix(0,xrow,1)
for(i in 1:xcol) {
f0<-type[[i]][[1]]
f0param<-type[[i]][[2]]
f1<-type[[i]][[3]]
f1param<-type[[i]][[4]]
loglike0[[i]]<-f0(x[,i],f0param)
loglike1[[i]]<-f1(x[,i],f1param)
L0<-L0+loglike0[[i]]
L1<-L1+loglike1[[i]]
}
## EM algorithm to get MLE of p and q
loglike.old <- -1e10
for(i.iter in 1:max.iter) {
if((i.iter%%50) == 0) {
print(paste("We have run the first ", i.iter, " iterations",sep=""))
}
err<-tol+1
## compute posterior cluster membership
clustlike<-matrix(0,xrow,2)
clustlike[,1]<-log(1-p)+L0
clustlike[,2]<-log(p)+L1
tempmax<-apply(clustlike,1,max)
for(j in 1:2) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
## update motif occurrence rate
for(j in 1:2) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.new<-(sum(clustlike[,2])+1)/(xrow+2)
## evaluate convergence
err<-abs(p.new-p)/p
## evaluate whether the log.likelihood increases
loglike.new<-(sum(tempmax+log(tempsum))+log(p.new)+log(1-p.new))/xrow
loglike.old<-loglike.new
p<-p.new
if(err<tol) {
break;
}
}
## compute posterior p
clustlike<-matrix(0,xrow,2)
clustlike[,1]<-log(1-p)+L0
clustlike[,2]<-log(p)+L1
tempmax<-apply(clustlike,1,max)
for(j in 1:2) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
for(j in 1:2) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.post<-matrix(0,xrow,xcol)
for(i in 1:xcol) {
p.post[,i]<-clustlike[,2]
}
## return
#calculate back loglikelihood
loglike.old<-loglike.old-(log(p)+log(1-p))/xrow
loglike.old<-loglike.old*xrow
result<-list(p.post=p.post, motif.prior=p, loglike=loglike.old)
}
## Fit each dataset separately
cmfitsep<-function(x, type, tol=1e-3, max.iter=100) {
## initialize
xrow<-nrow(x)
xcol<-ncol(x)
loglike0<-list()
loglike1<-list()
p<-0.01*rep(1,xcol)
loglike.final<-rep(0,xcol)
## compute loglikelihood
for(i in 1:xcol) {
f0<-type[[i]][[1]]
f0param<-type[[i]][[2]]
f1<-type[[i]][[3]]
f1param<-type[[i]][[4]]
loglike0[[i]]<-f0(x[,i],f0param)
loglike1[[i]]<-f1(x[,i],f1param)
}
p.post<-matrix(0,xrow,xcol)
## EM algorithm to get MLE of p
for(coli in 1:xcol) {
loglike.old <- -1e10
for(i.iter in 1:max.iter) {
if((i.iter%%50) == 0) {
print(paste("We have run the first ", i.iter, " iterations",sep=""))
}
err<-tol+1
## compute posterior cluster membership
clustlike<-matrix(0,xrow,2)
clustlike[,1]<-log(1-p[coli])+loglike0[[coli]]
clustlike[,2]<-log(p[coli])+loglike1[[coli]]
tempmax<-apply(clustlike,1,max)
for(j in 1:2) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
## evaluate whether the log.likelihood increases
loglike.new<-sum(tempmax+log(tempsum))/xrow
## update motif occurrence rate
for(j in 1:2) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.new<-(sum(clustlike[,2]))/(xrow)
## evaluate convergence
err<-abs(p.new-p[coli])/p[coli]
loglike.old<-loglike.new
p[coli]<-p.new
if(err<tol) {
break;
}
}
## compute posterior p
clustlike<-matrix(0,xrow,2)
clustlike[,1]<-log(1-p[coli])+loglike0[[coli]]
clustlike[,2]<-log(p[coli])+loglike1[[coli]]
tempmax<-apply(clustlike,1,max)
for(j in 1:2) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
for(j in 1:2) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.post[,coli]<-clustlike[,2]
loglike.final[coli]<-loglike.old
}
## return
loglike.final<-loglike.final*xrow
result<-list(p.post=p.post, motif.prior=p, loglike=loglike.final)
}
## Fit the full model
cmfitfull<-function(x, type, tol=1e-3, max.iter=100) {
## initialize
xrow<-nrow(x)
xcol<-ncol(x)
loglike0<-list()
loglike1<-list()
K<-2^xcol
p<-rep(1,K)/K
pattern<-rep(0,xcol)
patid<-matrix(0,K,xcol)
## compute loglikelihood
for(i in 1:xcol) {
f0<-type[[i]][[1]]
f0param<-type[[i]][[2]]
f1<-type[[i]][[3]]
f1param<-type[[i]][[4]]
loglike0[[i]]<-f0(x[,i],f0param)
loglike1[[i]]<-f1(x[,i],f1param)
}
L<-matrix(0,xrow,K)
for(i in 1:K)
{
patid[i,]<-pattern
for(j in 1:xcol) {
if(pattern[j] < 0.5) {
L[,i]<-L[,i]+loglike0[[j]]
} else {
L[,i]<-L[,i]+loglike1[[j]]
}
}
if(i < K) {
pattern[xcol]<-pattern[xcol]+1
j<-xcol
while(pattern[j] > 1) {
pattern[j]<-0
j<-j-1
pattern[j]<-pattern[j]+1
}
}
}
## EM algorithm to get MLE of p and q
loglike.old <- -1e10
for(i.iter in 1:max.iter) {
if((i.iter%%50) == 0) {
print(paste("We have run the first ", i.iter, " iterations",sep=""))
}
err<-tol+1
## compute posterior cluster membership
clustlike<-matrix(0,xrow,K)
for(j in 1:K) {
clustlike[,j]<-log(p[j])+L[,j]
}
tempmax<-apply(clustlike,1,max)
for(j in 1:K) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
## update motif occurrence rate
for(j in 1:K) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.new<-(apply(clustlike,2,sum)+1)/(xrow+K)
## evaluate convergence
err<-max(abs(p.new-p)/p)
## evaluate whether the log.likelihood increases
loglike.new<-(sum(tempmax+log(tempsum))+sum(log(p.new)))/xrow
loglike.old<-loglike.new
p<-p.new
if(err<tol) {
break;
}
}
## compute posterior p
clustlike<-matrix(0,xrow,K)
for(j in 1:K) {
clustlike[,j]<-log(p[j])+L[,j]
}
tempmax<-apply(clustlike,1,max)
for(j in 1:K) {
clustlike[,j]<-exp(clustlike[,j]-tempmax)
}
tempsum<-apply(clustlike,1,sum)
for(j in 1:K) {
clustlike[,j]<-clustlike[,j]/tempsum
}
p.post<-matrix(0,xrow,xcol)
for(j in 1:K) {
for(i in 1:xcol) {
if(patid[j,i] > 0.5) {
p.post[,i]<-p.post[,i]+clustlike[,j]
}
}
}
## return
#calculate back loglikelihood
loglike.old<-loglike.old-sum(log(p))/xrow
loglike.old<-loglike.old*xrow
result<-list(p.post=p.post, motif.prior=p, loglike=loglike.old)
}
generatetype<-function(limfitted)
{
jtype<-list()
df<-limfitted$g1num+limfitted$g2num-2+limfitted$df0
for(j in 1:limfitted$compnum)
{
jtype[[j]]<-list(f0=modt.f0.loglike, f0.param=df[j], f1=modt.f1.loglike, f1.param=c(df[j],limfitted$g1num[j],limfitted$g2num[j],limfitted$v0[j]))
}
jtype
}
cormotiffit <- function(exprs, groupid=NULL, compid=NULL, K=1, tol=1e-3,
max.iter=100, BIC=TRUE, norm.factor.method="TMM",
voom.normalize.method = "none", runtype=c("logCPM","counts","limmafits"), each=3)
{
# first I want to do some typechecking. Input can be either a normalized
# matrix, a count matrix, or a list of limma fits. Dispatch the correct
# limmafit accordingly.
# todo: add some typechecking here
limfitted <- list()
if (runtype=="counts") {
limfitted <- limmafit.counts(exprs,groupid,compid, norm.factor.method, voom.normalize.method)
} else if (runtype=="logCPM") {
limfitted <- limmafit.default(exprs,groupid,compid)
} else if (runtype=="limmafits") {
limfitted <- limmafit.list(exprs)
} else {
stop("runtype must be one of 'logCPM', 'counts', or 'limmafits'")
}
jtype<-generatetype(limfitted)
fitresult<-list()
ks <- rep(K, each = each)
fitresult <- bplapply(1:length(ks), function(i, x, type, ks, tol, max.iter) {
cmfit.X(x, type, K = ks[i], tol = tol, max.iter = max.iter)
}, x=limfitted$t, type=jtype, ks=ks, tol=tol, max.iter=max.iter)
best.fitresults <- list()
for (i in 1:length(K)) {
w.k <- which(ks==K[i])
this.bic <- c()
for (j in w.k) this.bic[j] <- -2 * fitresult[[j]]$loglike + (K[i] - 1 + K[i] * limfitted$compnum) * log(dim(limfitted$t)[1])
w.min <- which(this.bic == min(this.bic, na.rm = TRUE))[1]
best.fitresults[[i]] <- fitresult[[w.min]]
}
fitresult <- best.fitresults
bic <- rep(0, length(K))
aic <- rep(0, length(K))
loglike <- rep(0, length(K))
for (i in 1:length(K)) loglike[i] <- fitresult[[i]]$loglike
for (i in 1:length(K)) bic[i] <- -2 * fitresult[[i]]$loglike + (K[i] - 1 + K[i] * limfitted$compnum) * log(dim(limfitted$t)[1])
for (i in 1:length(K)) aic[i] <- -2 * fitresult[[i]]$loglike + 2 * (K[i] - 1 + K[i] * limfitted$compnum)
if(BIC==TRUE) {
bestflag=which(bic==min(bic))
}
else {
bestflag=which(aic==min(aic))
}
result<-list(bestmotif=fitresult[[bestflag]],bic=cbind(K,bic),
aic=cbind(K,aic),loglike=cbind(K,loglike), allmotifs=fitresult)
}
cormotiffitall<-function(exprs,groupid,compid, tol=1e-3, max.iter=100)
{
limfitted<-limmafit(exprs,groupid,compid)
jtype<-generatetype(limfitted)
fitresult<-cmfitall(limfitted$t,type=jtype,tol=1e-3,max.iter=max.iter)
}
cormotiffitsep<-function(exprs,groupid,compid, tol=1e-3, max.iter=100)
{
limfitted<-limmafit(exprs,groupid,compid)
jtype<-generatetype(limfitted)
fitresult<-cmfitsep(limfitted$t,type=jtype,tol=1e-3,max.iter=max.iter)
}
cormotiffitfull<-function(exprs,groupid,compid, tol=1e-3, max.iter=100)
{
limfitted<-limmafit(exprs,groupid,compid)
jtype<-generatetype(limfitted)
fitresult<-cmfitfull(limfitted$t,type=jtype,tol=1e-3,max.iter=max.iter)
}
plotIC<-function(fitted_cormotif)
{
oldpar<-par(mfrow=c(1,2))
plot(fitted_cormotif$bic[,1], fitted_cormotif$bic[,2], type="b",xlab="Motif Number", ylab="BIC", main="BIC")
plot(fitted_cormotif$aic[,1], fitted_cormotif$aic[,2], type="b",xlab="Motif Number", ylab="AIC", main="AIC")
}
plotMotif<-function(fitted_cormotif,title="")
{
layout(matrix(1:2,ncol=2))
u<-1:dim(fitted_cormotif$bestmotif$motif.q)[2]
v<-1:dim(fitted_cormotif$bestmotif$motif.q)[1]
image(u,v,t(fitted_cormotif$bestmotif$motif.q),
col=gray(seq(from=1,to=0,by=-0.1)),xlab="Study",yaxt = "n",
ylab="Corr. Motifs",main=paste(title,"pattern",sep=" "))
axis(2,at=1:length(v))
for(i in 1:(length(u)+1))
{
abline(v=(i-0.5))
}
for(i in 1:(length(v)+1))
{
abline(h=(i-0.5))
}
Ng=10000
if(is.null(fitted_cormotif$bestmotif$p.post)!=TRUE)
Ng=nrow(fitted_cormotif$bestmotif$p.post)
genecount=floor(fitted_cormotif$bestmotif$motif.p*Ng)
NK=nrow(fitted_cormotif$bestmotif$motif.q)
plot(0,0.7,pch=".",xlim=c(0,1.2),ylim=c(0.75,NK+0.25),
frame.plot=FALSE,axes=FALSE,xlab="No. of genes",ylab="", main=paste(title,"frequency",sep=" "))
segments(0,0.7,fitted_cormotif$bestmotif$motif.p[1],0.7)
rect(0,1:NK-0.3,fitted_cormotif$bestmotif$motif.p,1:NK+0.3,
col="dark grey")
mtext(1:NK,at=1:NK,side=2,cex=0.8)
text(fitted_cormotif$bestmotif$motif.p+0.15,1:NK,
labels=floor(fitted_cormotif$bestmotif$motif.p*Ng))
}📌 Load Required Libraries
library(Cormotif)
library(Rfast)
library(dplyr)
library(BiocParallel)
library(gprofiler2)
library(ggplot2)📌 Corrmotif Model 0.1 Micromolar
📌 Load Corrmotif Data
# Read the Corrmotif Results
Corrmotif <- read.csv("data/Corrmotif/CX5461.csv")
Corrmotif_df <- data.frame(Corrmotif)
rownames(Corrmotif_df) <- Corrmotif_df$Gene
# Filter for 0.1 Concentration Only
exprs.corrmotif <- as.matrix(Corrmotif_df[, grep("0.1", colnames(Corrmotif_df))])
# Read group and comparison IDs
groupid <- read.csv("data/Corrmotif/groupid.csv")
groupid_df <- data.frame(groupid[, grep("0.1", colnames(groupid))])
compid <- read.csv("data/Corrmotif/Compid.csv")
compid_df <- compid[compid$Cond1 %in% unique(as.numeric(groupid_df)) & compid$Cond2 %in% unique(as.numeric(groupid_df)), ]📌 Corrmotif Model 0.1 Micromolar (K=1:8)
📌 Fit Corrmotif Model (K=1:8) (0.1 Micromolar)
set.seed(11111)
# Fit Corrmotif Model (K = 1 to 8)
set.seed(11111)
motif.fitted_0.1 <- cormotiffit(
exprs = exprs.corrmotif,
groupid = groupid_df,
compid = compid_df,
K = 1:8,
max.iter = 1000,
BIC = TRUE,
runtype = "logCPM"
)
gene_prob_0.1 <- motif.fitted_0.1$bestmotif$p.post
rownames(gene_prob_0.1) <- rownames(Corrmotif_df)
motif_prob_0.1 <- motif.fitted_0.1$bestmotif$clustlike
rownames(motif_prob_0.1) <- rownames(gene_prob_0.1)
write.csv(motif_prob_0.1,"data/cormotif_probability_genelist_0.1.csv")📌 Plot motif (0.1 Micromolar)
cormotif_0.1 <- readRDS("data/Corrmotif/cormotif_0.1.RDS")
cormotif_0.1$bic K bic
[1,] 1 291696.5
[2,] 2 284585.3
[3,] 3 283482.9
[4,] 4 283551.8
[5,] 5 283620.7
[6,] 6 283689.6
[7,] 7 283758.5
[8,] 8 283827.4plotIC(cormotif_0.1)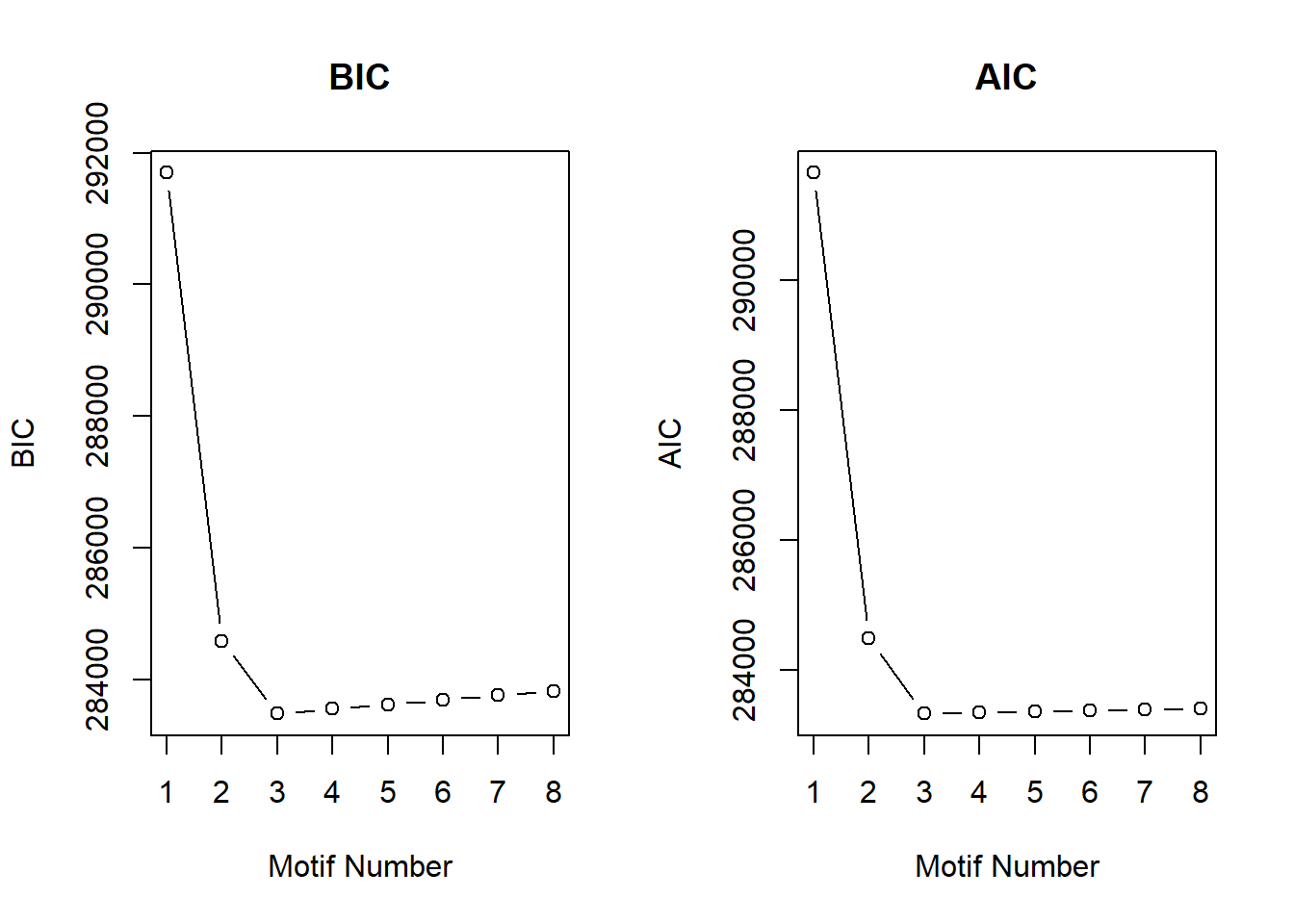
plotMotif(cormotif_0.1)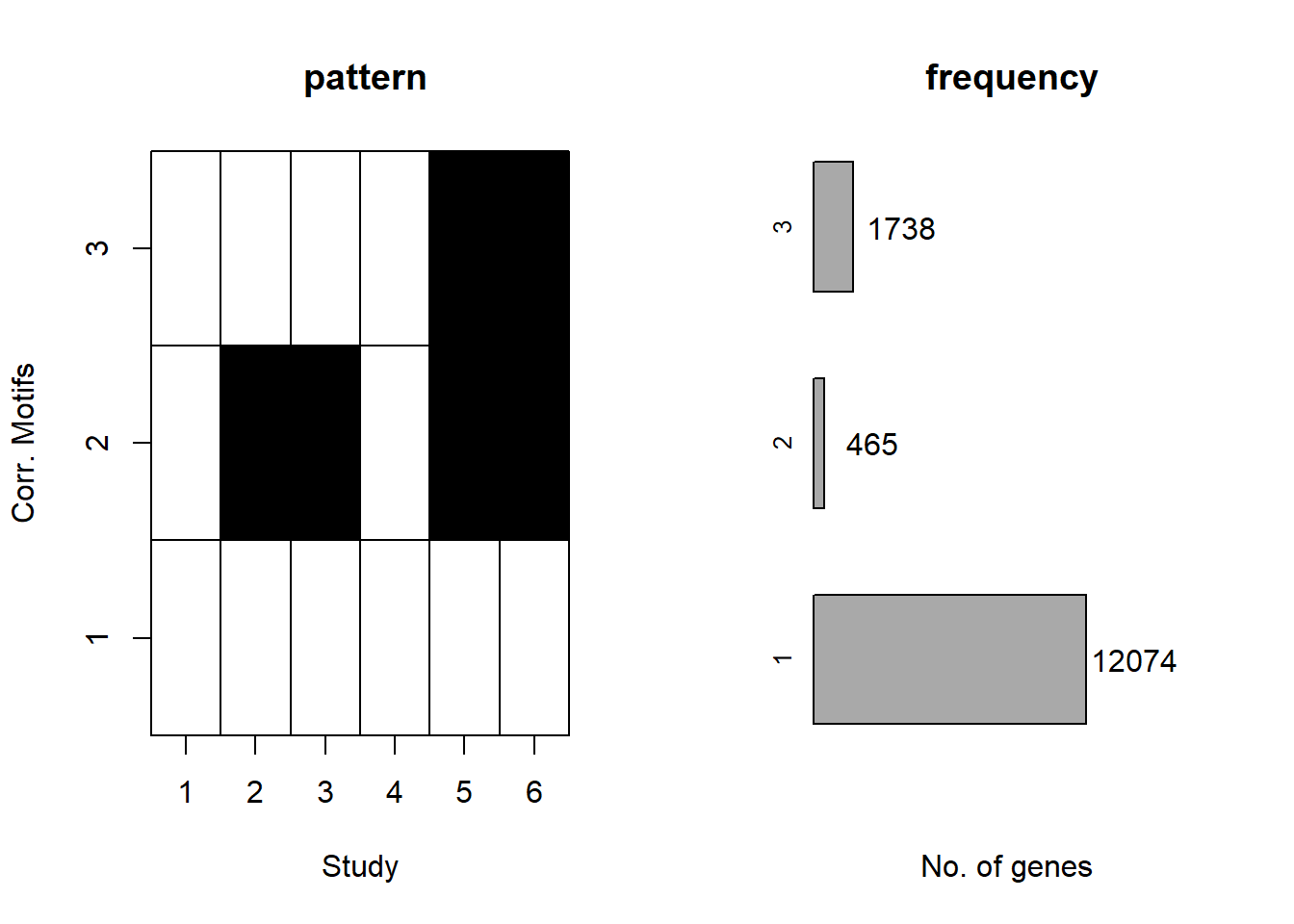
📌 Extract Gene Probabilities (0.1 Micromolar)
# Extract posterior probabilities for genes
gene_prob_tran_0.1 <- cormotif_0.1$bestmotif$p.post
rownames(gene_prob_tran_0.1) <- rownames(Corrmotif_df)
# Define gene probability groups
prob_1_0.1 <- rownames(gene_prob_tran_0.1[(gene_prob_tran_0.1[,1] <0.5 & gene_prob_tran_0.1[,2] <0.5 & gene_prob_tran_0.1[,3] <0.5 & gene_prob_tran_0.1[,4] <0.5 & gene_prob_tran_0.1[,5] < 0.5 & gene_prob_tran_0.1[,6]<0.5),])
length(prob_1_0.1)[1] 12308prob_2_0.1 <- rownames(gene_prob_tran_0.1[(gene_prob_tran_0.1[,1] <0.5 & gene_prob_tran_0.1[,2] >0.5 & gene_prob_tran_0.1[,3] >0.5 & gene_prob_tran_0.1[,4] <0.5 & gene_prob_tran_0.1[,5] > 0.5 & gene_prob_tran_0.1[,6]>0.5),])
length(prob_2_0.1)[1] 415prob_3_0.1 <- rownames(gene_prob_tran_0.1[(gene_prob_tran_0.1[,1] <0.5 & gene_prob_tran_0.1[,2] <0.5 & gene_prob_tran_0.1[,3] <0.5 & gene_prob_tran_0.1[,4] <0.5 & gene_prob_tran_0.1[,5] > 0.5 & gene_prob_tran_0.1[,6]>0.5),])
length(prob_3_0.1)[1] 1551📌 Distribution of Gene Clusters Identified by Corrmotif (0.1 micromolar)
# Load necessary library
library(ggplot2)
# Data
data <- data.frame(
Category = c("Non response (0.1 µM)", "CX-DOX mid-late response (0.1 µM)", "DOX only mid-late (0.1 µM)"),
Value = c(12308, 415, 1551)
)
# Define custom colors
custom_colors <- c("Non response (0.1 µM)" = "#FF9999",
"CX-DOX mid-late response (0.1 µM)" = "#66B2FF",
"DOX only mid-late (0.1 µM)" = "#99FF99")
# Create pie chart
ggplot(data, aes(x = "", y = Value, fill = Category)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
geom_text(aes(label = Value),
position = position_stack(vjust = 0.5),
size = 4, color = "black") +
labs(title = "Pie Chart (0.1 micromolar Corrmotif)", x = NULL, y = NULL) +
theme_void() +
scale_fill_manual(values = custom_colors)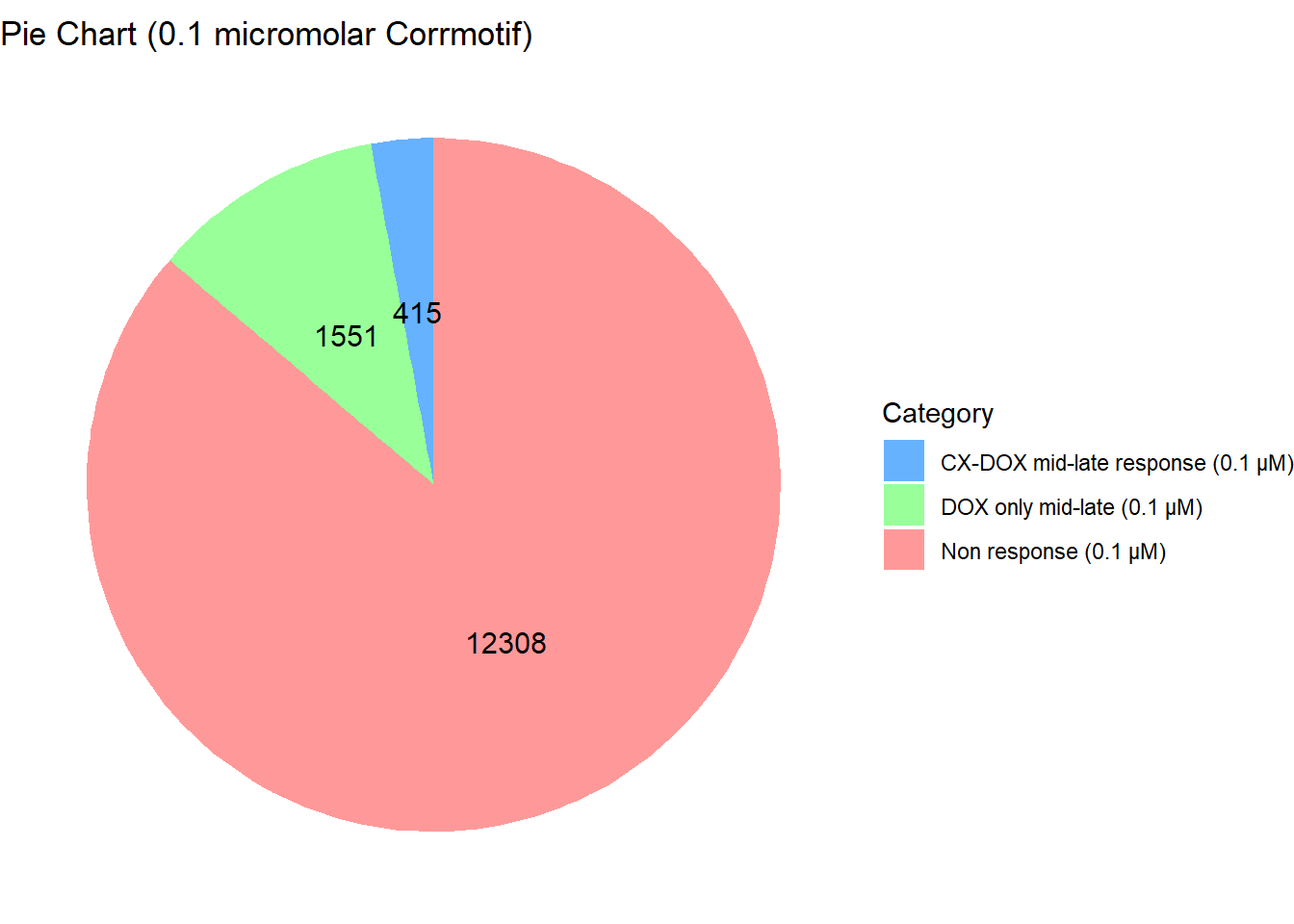
📌 Save Corr-motif datasets for Gene Ontology analysis (0.1 Micromolar)
write.csv(data.frame(Entrez_ID = prob_1_0.1), "data/prob_1_0.1.csv", row.names = FALSE)
write.csv(data.frame(Entrez_ID = prob_2_0.1), "data/prob_2_0.1.csv", row.names = FALSE)
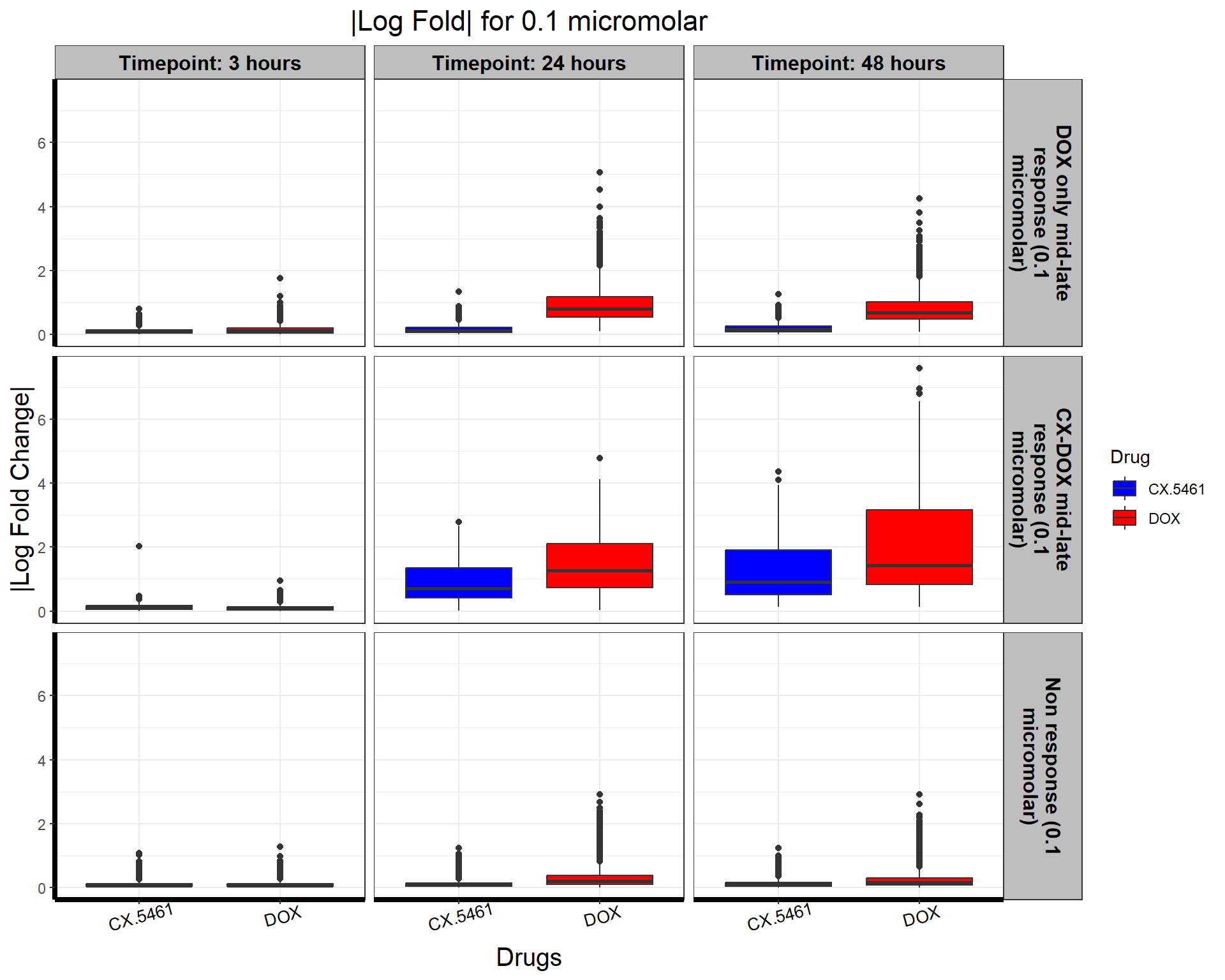
write.csv(data.frame(Entrez_ID = prob_3_0.1), "data/prob_3_0.1.csv", row.names = FALSE)📌 0.1 Micromolar abs logFC
# Load Required Libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# Load Datasets (Only 0.1 Micromolar)
CX_0.1_3 <- read.csv("data/DEGs/Toptable_CX_0.1_3.csv")
CX_0.1_24 <- read.csv("data/DEGs/Toptable_CX_0.1_24.csv")
CX_0.1_48 <- read.csv("data/DEGs/Toptable_CX_0.1_48.csv")
DOX_0.1_3 <- read.csv("data/DEGs/Toptable_DOX_0.1_3.csv")
DOX_0.1_24 <- read.csv("data/DEGs/Toptable_DOX_0.1_24.csv")
DOX_0.1_48 <- read.csv("data/DEGs/Toptable_DOX_0.1_48.csv")
# Combine All 0.1 Micromolar Datasets into a Single Dataframe
all_toptables_0.1 <- bind_rows(
CX_0.1_3 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 3 hours"),
CX_0.1_24 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 24 hours"),
CX_0.1_48 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 48 hours"),
DOX_0.1_3 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 3 hours"),
DOX_0.1_24 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 24 hours"),
DOX_0.1_48 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 48 hours")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.1$Entrez_ID <- as.character(all_toptables_0.1$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 micromolar)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response\n(0.1 micromolar)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response\n(0.1 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# Compute Absolute logFC
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(absFC = abs(logFC))
# Convert Factors for Proper Ordering (Reversed Order for Response Groups)
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(
Drug = factor(Drug, levels = c("CX.5461", "DOX")),
Timepoint = factor(Timepoint, levels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group,
levels = c(
"DOX only mid-late response\n(0.1 micromolar)",
"CX-DOX mid-late response\n(0.1 micromolar)",
"Non response\n(0.1 micromolar)" # Reversed Order
))
)
# **Plot the Boxplot with Faceted Labels Wrapping Correctly**
ggplot(all_toptables_0.1, aes(x = Drug, y = absFC, fill = Drug)) +
geom_boxplot() +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) + # Custom color palette
facet_grid(Response_Group ~ Timepoint, labeller = label_wrap_gen(width = 20)) + # Ensure Proper Wrapping
theme_bw() +
labs(
x = "Drugs",
y = "|Log Fold Change|",
title = "|Log Fold| for 0.1 micromolar"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.line = element_line(linewidth = 1.5),
strip.background = element_rect(fill = "gray"), # Gray background for facet labels
strip.text = element_text(size = 12, color = "black", face = "bold"), # Bold styling for facet labels
axis.text.x = element_text(size = 10, color = "black", angle = 15)
)
📌 0.1 Micromolar mean (Abs logFC) across timepoints
# Load Required Libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# Load Datasets (Only 0.1 Micromolar)
CX_0.1_3 <- read.csv("data/DEGs/Toptable_CX_0.1_3.csv")
CX_0.1_24 <- read.csv("data/DEGs/Toptable_CX_0.1_24.csv")
CX_0.1_48 <- read.csv("data/DEGs/Toptable_CX_0.1_48.csv")
DOX_0.1_3 <- read.csv("data/DEGs/Toptable_DOX_0.1_3.csv")
DOX_0.1_24 <- read.csv("data/DEGs/Toptable_DOX_0.1_24.csv")
DOX_0.1_48 <- read.csv("data/DEGs/Toptable_DOX_0.1_48.csv")
# Combine All 0.1 Micromolar Datasets into a Single Dataframe
all_toptables_0.1 <- bind_rows(
CX_0.1_3 %>% mutate(Drug = "CX.5461", Timepoint = "3"),
CX_0.1_24 %>% mutate(Drug = "CX.5461", Timepoint = "24"),
CX_0.1_48 %>% mutate(Drug = "CX.5461", Timepoint = "48"),
DOX_0.1_3 %>% mutate(Drug = "DOX", Timepoint = "3"),
DOX_0.1_24 %>% mutate(Drug = "DOX", Timepoint = "24"),
DOX_0.1_48 %>% mutate(Drug = "DOX", Timepoint = "48")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.1$Entrez_ID <- as.character(all_toptables_0.1$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 micromolar)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response\n(0.1 micromolar)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response\n(0.1 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# Compute Mean Absolute logFC for Line Plot
data_summary <- all_toptables_0.1 %>%
mutate(abs_logFC = abs(logFC)) %>% # Take absolute log fold change
group_by(Response_Group, Drug, Timepoint) %>%
dplyr::summarize(mean_abs_logFC = mean(abs_logFC, na.rm = TRUE), .groups = "drop") %>%
as.data.frame()
# **Ensure all timepoints exist in the summary**
timepoints_full <- expand.grid(
Response_Group = unique(all_toptables_0.1$Response_Group),
Drug = unique(all_toptables_0.1$Drug),
Timepoint = c("3", "24", "48")
)
# **Merge to keep missing timepoints**
data_summary <- full_join(timepoints_full, data_summary, by = c("Response_Group", "Drug", "Timepoint"))
# **Replace NA mean_abs_logFC with 0 if no genes were present**
data_summary$mean_abs_logFC[is.na(data_summary$mean_abs_logFC)] <- 0
# Convert Factors for Proper Ordering (Reversed Order for Response Groups)
data_summary <- data_summary %>%
mutate(
Timepoint = factor(Timepoint, levels = c("3", "24", "48"), labels = c("3 hours", "24 hours", "48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX only mid-late response\n(0.1 micromolar)",
"CX-DOX mid-late response\n(0.1 micromolar)",
"Non response\n(0.1 micromolar)" # Reversed Order
))
)
# Define custom drug palette
drug_palette <- c("CX.5461" = "blue", "DOX" = "red")
# **Plot the Line Plot for Absolute logFC**
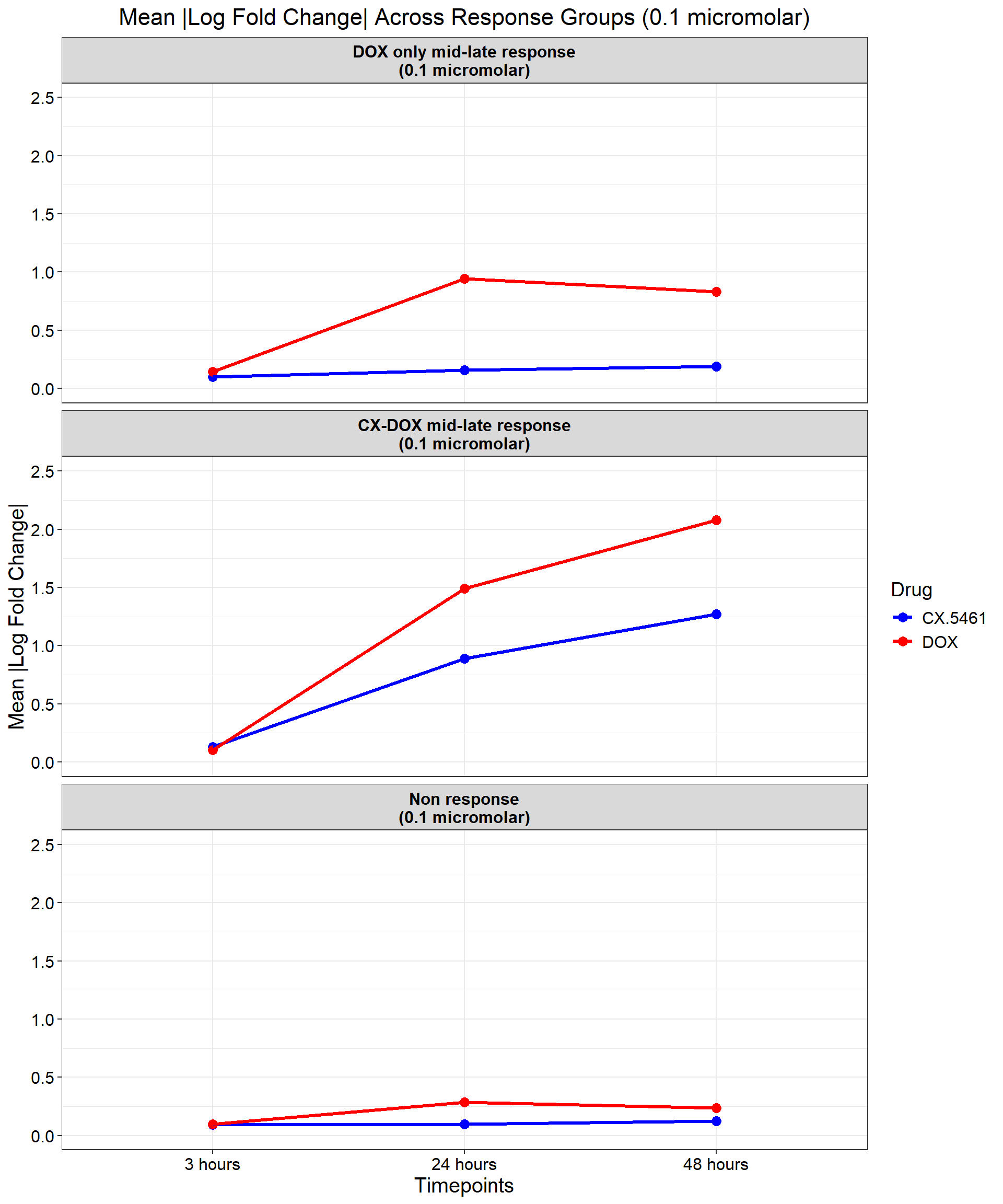
ggplot(data_summary, aes(x = Timepoint, y = mean_abs_logFC, group = Drug, color = Drug)) +
geom_point(size = 3) +
geom_line(size = 1.2) +
scale_color_manual(values = drug_palette) +
ylim(0, 2.5) + # Adjust the Y-axis for better visualization
facet_wrap(~ Response_Group, ncol = 1) + # Facet by Response Group (Reversed Order)
theme_bw() +
labs(
x = "Timepoints",
y = "Mean |Log Fold Change|",
title = "Mean |Log Fold Change| Across Response Groups (0.1 micromolar)",
color = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text = element_text(size = 12, color = "black"),
strip.text = element_text(size = 12, color = "black", face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)
📌 0.1 Micromolar logFC
# Load required libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# Load Datasets (Only 0.1 Micromolar)
CX_0.1_3 <- read.csv("data/DEGs/Toptable_CX_0.1_3.csv")
CX_0.1_24 <- read.csv("data/DEGs/Toptable_CX_0.1_24.csv")
CX_0.1_48 <- read.csv("data/DEGs/Toptable_CX_0.1_48.csv")
DOX_0.1_3 <- read.csv("data/DEGs/Toptable_DOX_0.1_3.csv")
DOX_0.1_24 <- read.csv("data/DEGs/Toptable_DOX_0.1_24.csv")
DOX_0.1_48 <- read.csv("data/DEGs/Toptable_DOX_0.1_48.csv")
# Combine All 0.1 Micromolar Datasets into a Single Dataframe
all_toptables_0.1 <- bind_rows(
CX_0.1_3 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 3 hours"),
CX_0.1_24 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 24 hours"),
CX_0.1_48 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 48 hours"),
DOX_0.1_3 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 3 hours"),
DOX_0.1_24 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 24 hours"),
DOX_0.1_48 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 48 hours")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.1$Entrez_ID <- as.character(all_toptables_0.1$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 micromolar)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response\n(0.1 micromolar)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response\n(0.1 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# Convert factors to ensure correct ordering (Reversed Order for Response Groups)
all_toptables_0.1 <- all_toptables_0.1 %>%
mutate(
Timepoint = factor(Timepoint, levels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX only mid-late response\n(0.1 micromolar)",
"CX-DOX mid-late response\n(0.1 micromolar)",
"Non response\n(0.1 micromolar)" # Reversed Order
))
)
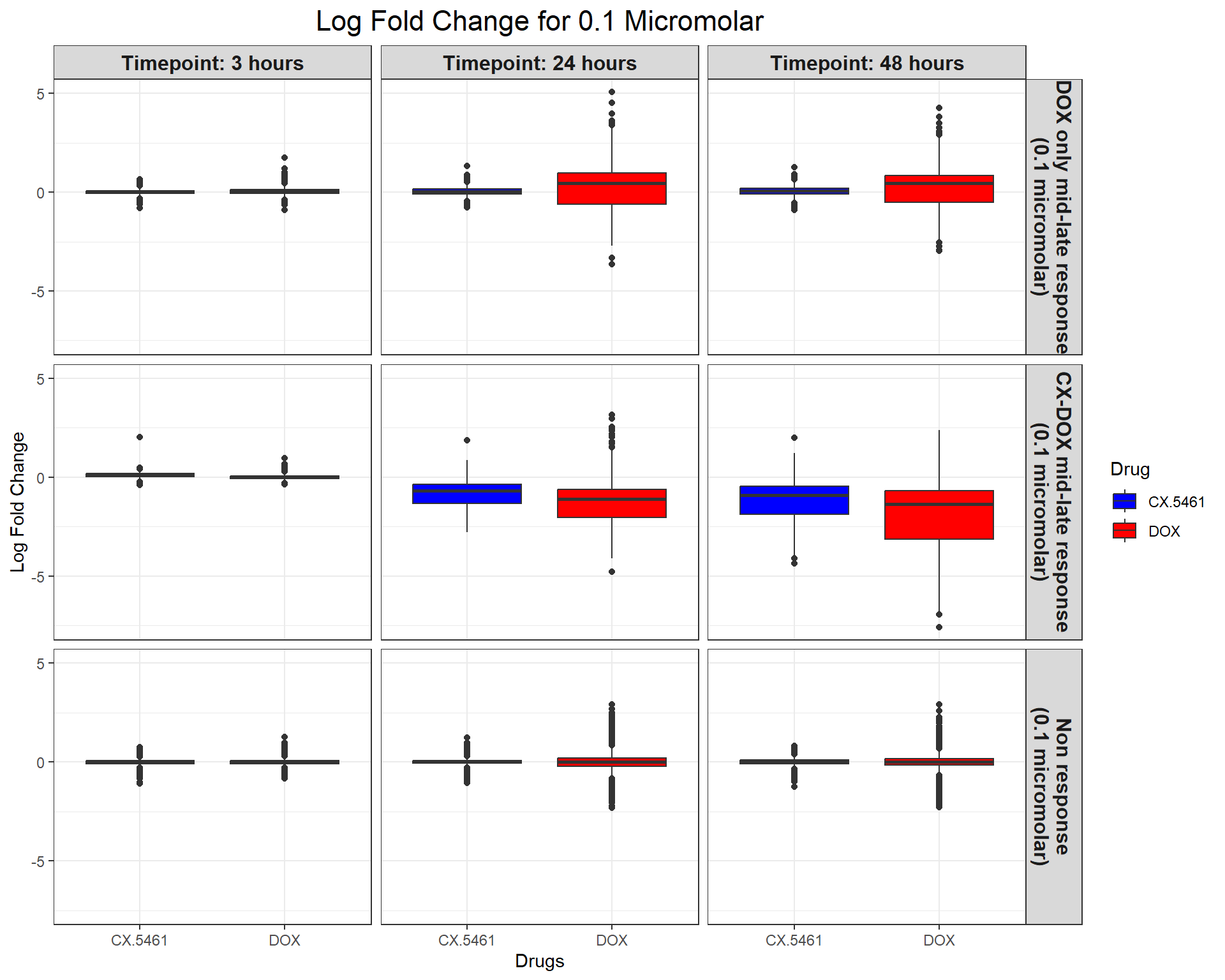
# **Plot the Boxplot**
ggplot(all_toptables_0.1, aes(x = Drug, y = logFC, fill = Drug)) +
geom_boxplot() +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) +
facet_grid(Response_Group ~ Timepoint) +
theme_bw() +
labs(x = "Drugs", y = "Log Fold Change", title = "Log Fold Change for 0.1 Micromolar") +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
strip.text = element_text(size = 12, face = "bold")
)
📌 0.1 Micromolar mean logFC across timepoints
# Compute Mean logFC for Line Plot
data_summary <- all_toptables_0.1 %>%
group_by(Response_Group, Drug, Timepoint) %>%
dplyr::summarize(mean_logFC = mean(logFC, na.rm = TRUE), .groups = "drop") %>%
as.data.frame()
# Convert factors to ensure correct ordering (Reversed Order for Response Groups)
data_summary <- data_summary %>%
mutate(
Timepoint = factor(Timepoint, levels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX only mid-late response\n(0.1 micromolar)",
"CX-DOX mid-late response\n(0.1 micromolar)",
"Non response\n(0.1 micromolar)" # Reversed Order
))
)
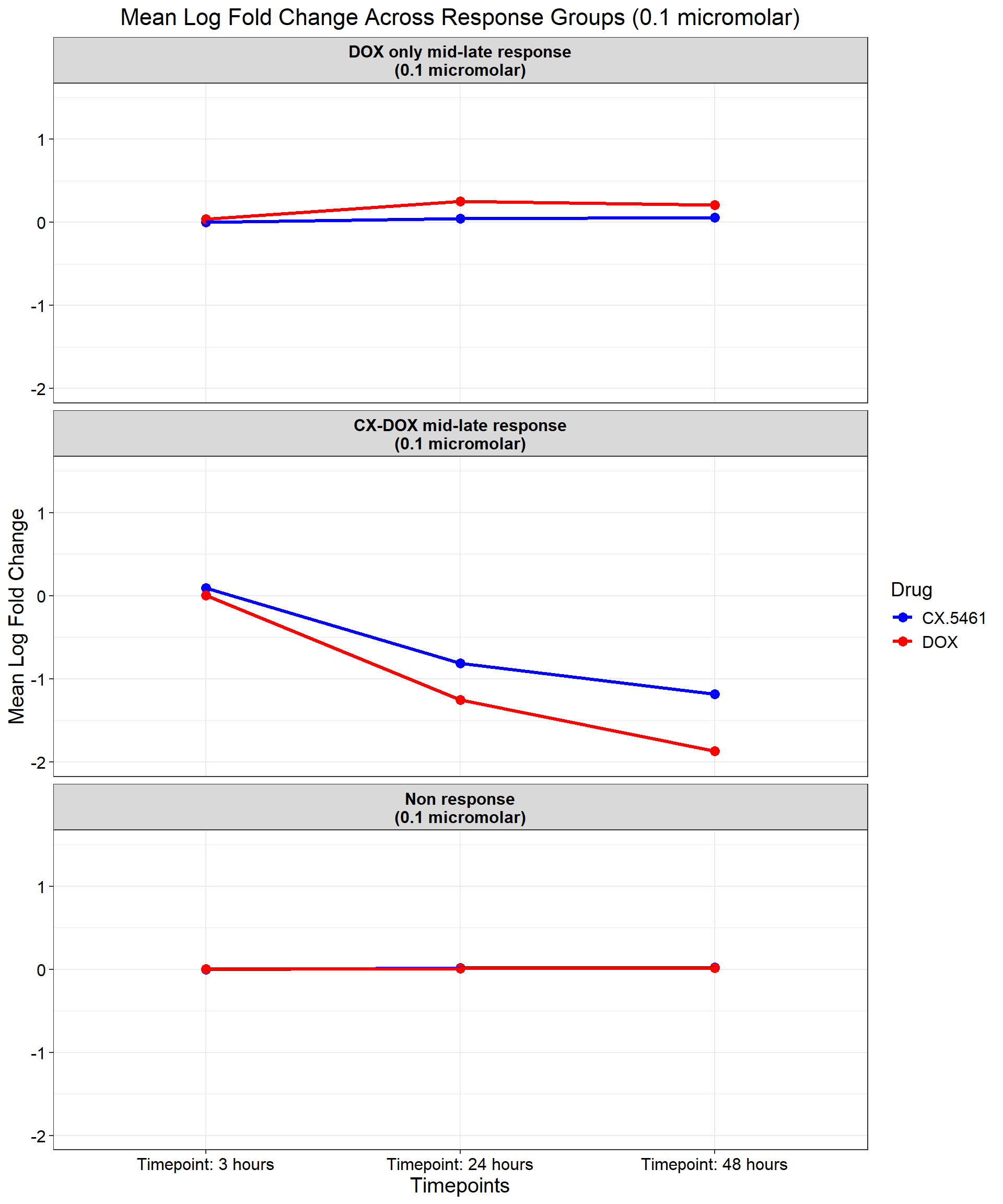
# **Plot the Line Plot**
ggplot(data_summary, aes(x = Timepoint, y = mean_logFC, group = Drug, color = Drug)) +
geom_point(size = 3) +
geom_line(size = 1.2) +
scale_color_manual(values = c("CX.5461" = "blue", "DOX" = "red")) +
ylim(-2, 1.5) + # Adjust the Y-axis for better visualization
facet_wrap(~ Response_Group, ncol = 1) + # Facet by Response Group (Reversed Order)
theme_bw() +
labs(
x = "Timepoints",
y = "Mean Log Fold Change",
title = "Mean Log Fold Change Across Response Groups (0.1 micromolar)",
color = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text = element_text(size = 12, color = "black"),
strip.text = element_text(size = 12, color = "black", face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)
📌 Corrmotif Model 0.5 Micromolar
📌 Load Corrmotif Data
# Read the Corrmotif Results
Corrmotif <- read.csv("data/Corrmotif/CX5461.csv")
Corrmotif_df <- data.frame(Corrmotif)
rownames(Corrmotif_df) <- Corrmotif_df$Gene
# Filter for 0.5 Concentration Only
exprs.corrmotif <- as.matrix(Corrmotif_df[, grep("0.5", colnames(Corrmotif_df))])
# Read group and comparison IDs
groupid <- read.csv("data/Corrmotif/groupid.csv")
groupid_df <- data.frame(groupid[, grep("0.5", colnames(groupid))])
compid <- read.csv("data/Corrmotif/Compid.csv")
compid_df <- compid[compid$Cond1 %in% unique(as.numeric(groupid_df)) & compid$Cond2 %in% unique(as.numeric(groupid_df)), ]📌 Corrmotif Model 0.5 Micromolar (K=1:8)
📌 Fit Corrmotif Model (K=1:8) (0.5 Micromolar)
# Fit Corrmotif Model (K = 1 to 8)
set.seed(11111)
motif.fitted_0.5 <- cormotiffit(
exprs = exprs.corrmotif,
groupid = groupid_df,
compid = compid_df,
K = 1:8,
max.iter = 1000,
BIC = TRUE,
runtype = "logCPM"
)
gene_prob_0.5 <- motif.fitted_0.5$bestmotif$p.post
rownames(gene_prob_0.5) <- rownames(Corrmotif_df)
motif_prob_0.5 <- motif.fitted_0.5$bestmotif$clustlike
rownames(motif_prob_0.5) <- rownames(gene_prob_0.5)
write.csv(motif_prob_0.5,"data/cormotif_probability_genelist_0.5.csv")📌 Plot motif (0.5 Micromolar)
cormotif_0.5 <- readRDS("data/Corrmotif/cormotif_0.5.RDS")
cormotif_0.5$bic K bic
[1,] 1 352140.7
[2,] 2 346785.8
[3,] 3 344812.9
[4,] 4 344860.1
[5,] 5 344751.9
[6,] 6 344820.8
[7,] 7 344889.7
[8,] 8 344966.6plotIC(cormotif_0.5)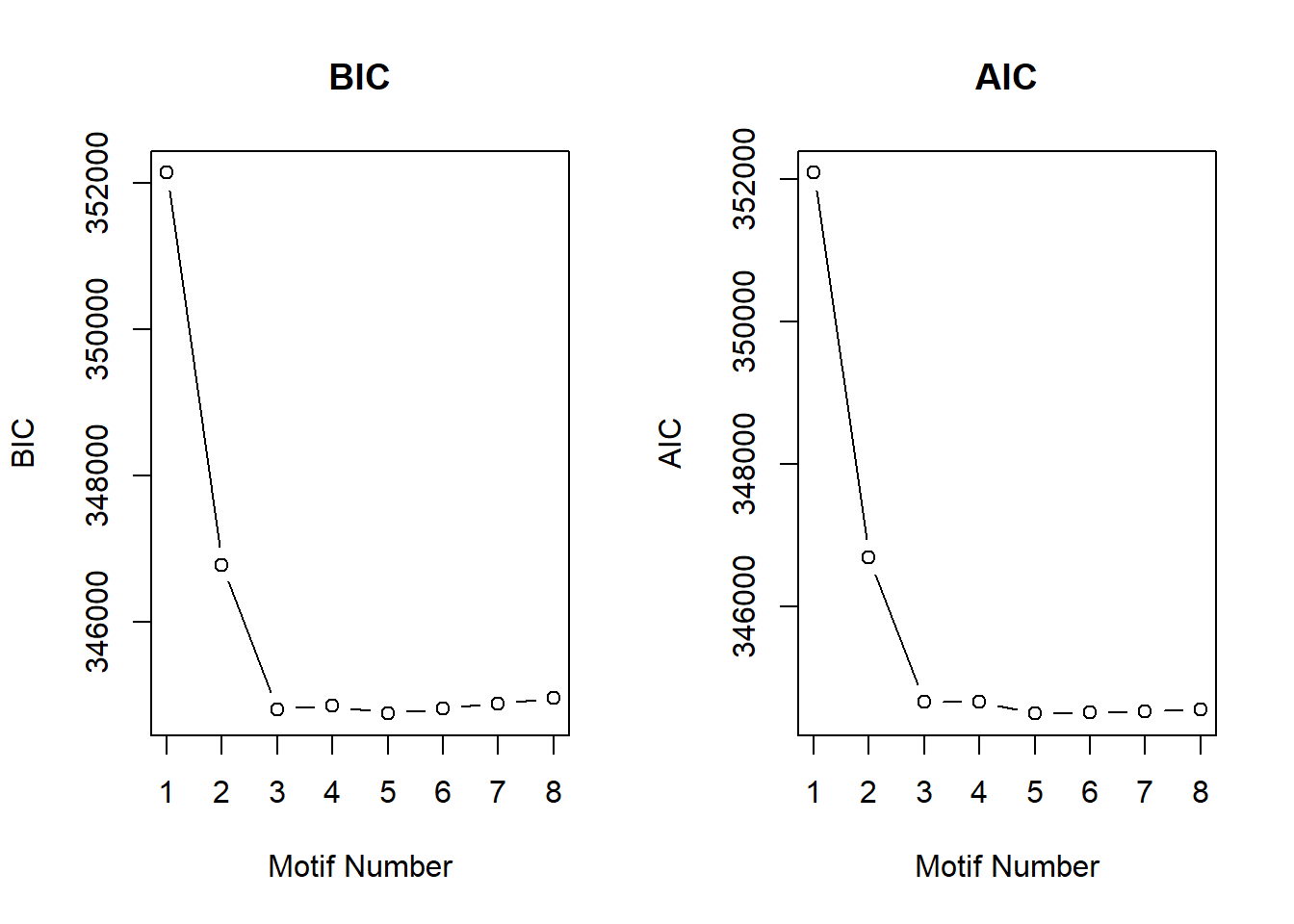
plotMotif(cormotif_0.5)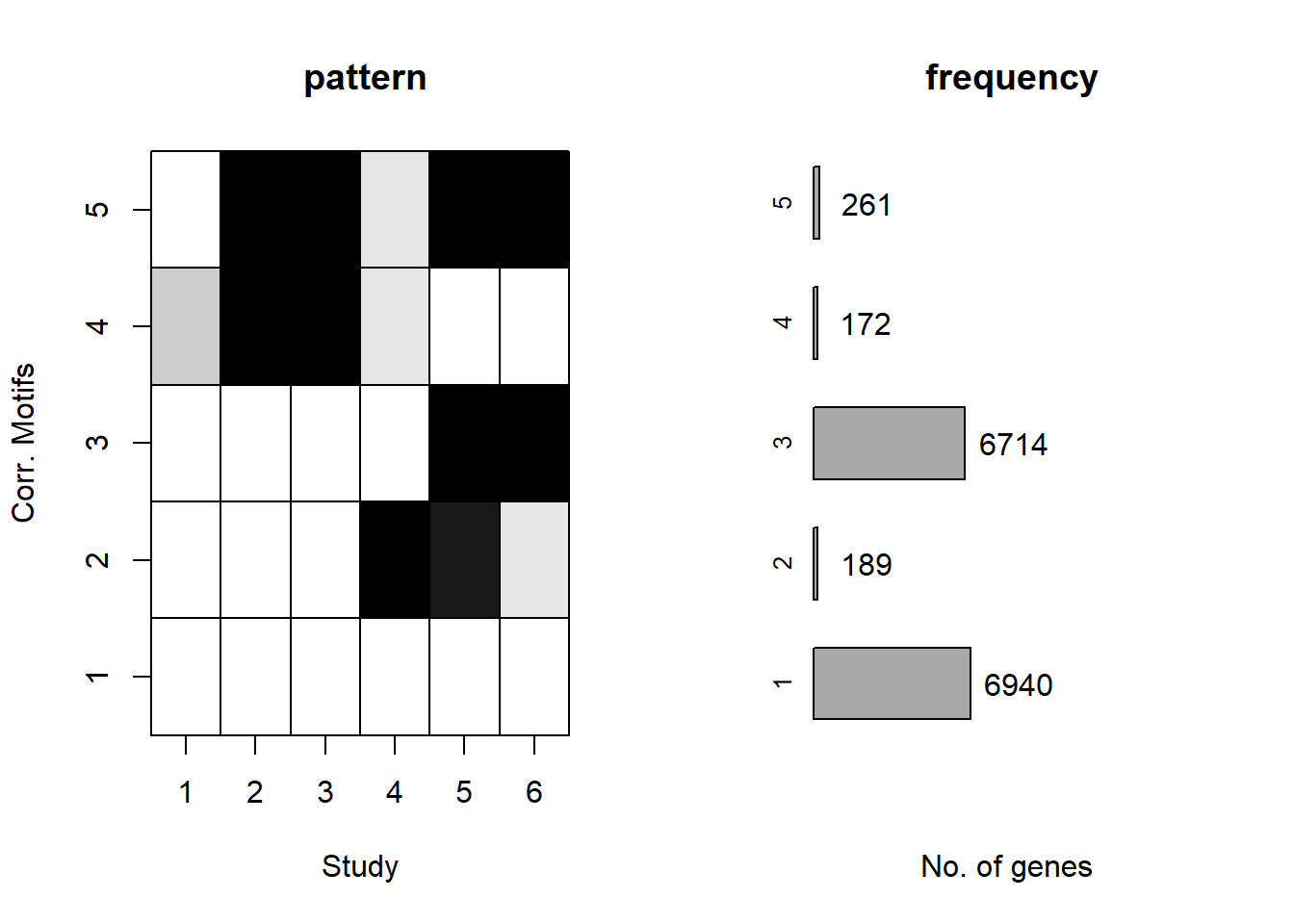
📌 Extract Gene Probabilities (0.5 Micromolar)
# Extract posterior probabilities for genes
gene_prob_tran_0.5 <- cormotif_0.5$bestmotif$p.post
rownames(gene_prob_tran_0.5) <- rownames(Corrmotif_df)
# Define gene probability groups
prob_1_0.5 <- rownames(gene_prob_tran_0.5[(gene_prob_tran_0.5[,1] <0.5 & gene_prob_tran_0.5[,2] <0.5 & gene_prob_tran_0.5[,3] <0.5 & gene_prob_tran_0.5[,4] <0.5 & gene_prob_tran_0.5[,5] < 0.5 & gene_prob_tran_0.5[,6]<0.5),])
length(prob_1_0.5)[1] 7134prob_2_0.5 <- rownames(gene_prob_tran_0.5[(gene_prob_tran_0.5[,1] <0.5 & gene_prob_tran_0.5[,2] <0.5 & gene_prob_tran_0.5[,3] <0.5 & gene_prob_tran_0.5[,4] >0.5 & gene_prob_tran_0.5[,5] > 0.5 & gene_prob_tran_0.5[,6]>=0.02),])
length(prob_2_0.5)[1] 179prob_3_0.5 <- rownames(gene_prob_tran_0.5[(gene_prob_tran_0.5[,1] <0.5 & gene_prob_tran_0.5[,2] <0.5 & gene_prob_tran_0.5[,3] <0.5 & gene_prob_tran_0.5[,4] <0.5 & gene_prob_tran_0.5[,5] > 0.5 & gene_prob_tran_0.5[,6]>0.5),])
length(prob_3_0.5)[1] 6450prob_4_0.5 <- rownames(gene_prob_tran_0.5[(gene_prob_tran_0.5[,1] >= 0.1 & gene_prob_tran_0.5[,2] > 0.5 & gene_prob_tran_0.5[,3] > 0.5 & gene_prob_tran_0.5[,4] >= 0.02 & gene_prob_tran_0.5[,5] < 0.5 & gene_prob_tran_0.5[,6] < 0.5),])
length(prob_4_0.5)[1] 142prob_5_0.5 <- rownames(gene_prob_tran_0.5[(gene_prob_tran_0.5[,1] <0.5 & gene_prob_tran_0.5[,2] >0.5 & gene_prob_tran_0.5[,3] >0.5 & gene_prob_tran_0.5[,4] >=0.02 & gene_prob_tran_0.5[,4] <0.5 & gene_prob_tran_0.5[,5] > 0.5 & gene_prob_tran_0.5[,6]>0.5),])
length(prob_5_0.5)[1] 221📌 Distribution of Gene Clusters Identified by Corrmotif (0.5 micromolar)
# Load necessary library
library(ggplot2)
# Data
data <- data.frame(
Category = c("Non response (0.5)", "DOX-specific response (0.5 µM)", "DOX only mid-late response (0.5 µM)", "CX + DOX (early) response (0.5 µM)", "DOX + CX (mid-late) response (0.5 µM)"),
Value = c(7134,179,6450,142,221)
)
# Add values to category names (to be displayed in the legend)
data$Category <- paste0(data$Category, " (", data$Value, ")")
# Define custom colors with updated category names
custom_colors <- setNames(
c("#FF9999", "#FF66CC", "#66B2FF", "#99FF99", "#FFD700"),
data$Category # Ensures color names match updated categories
)
# Create pie chart without number labels inside
ggplot(data, aes(x = "", y = Value, fill = Category)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
labs(title = "Pie Chart (0.5 micromolar Corrmotif)", x = NULL, y = NULL) +
theme_void() +
scale_fill_manual(values = custom_colors)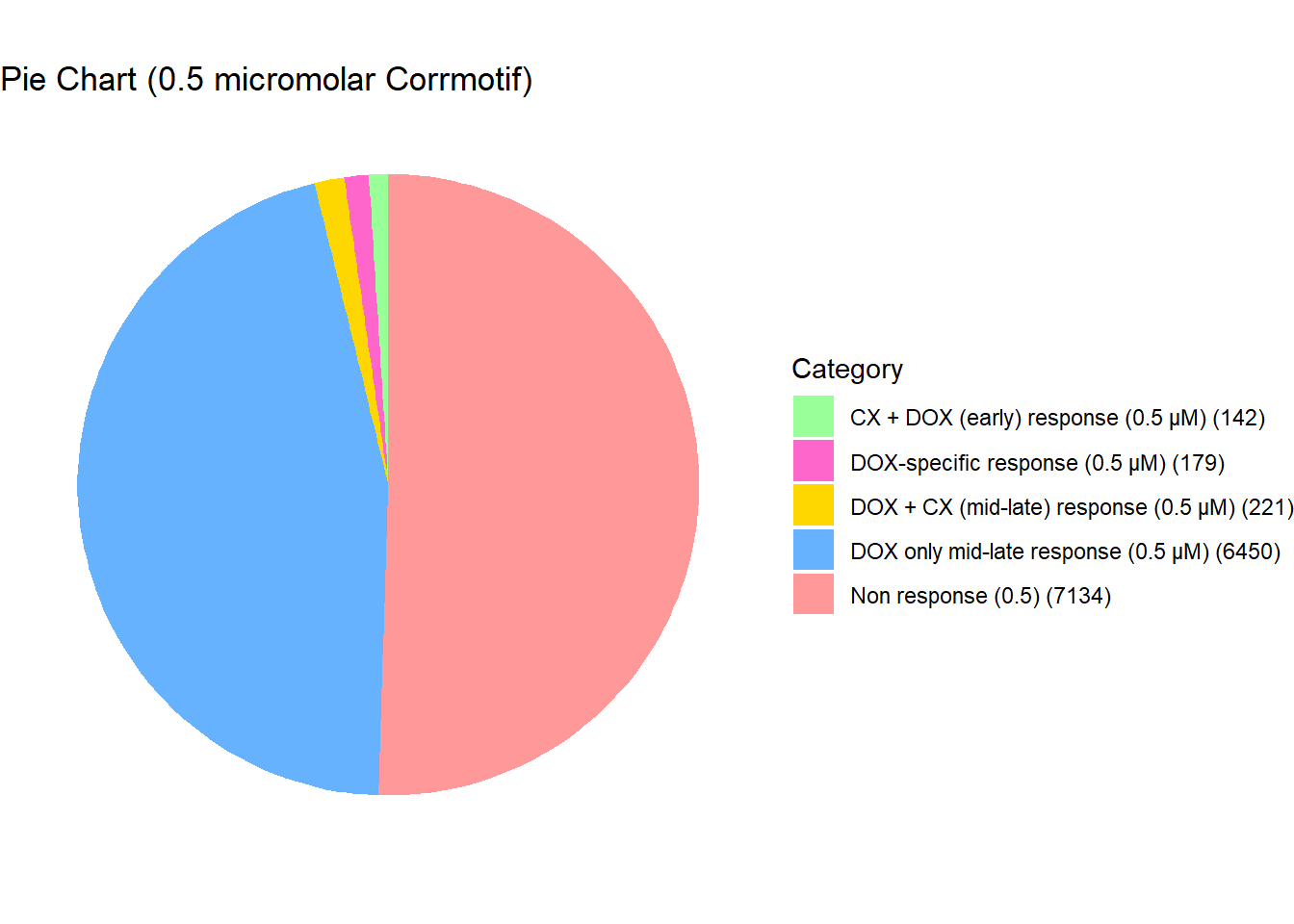
📌 Combined pie charts for concentrations
# Load necessary libraries
library(ggplot2)
library(dplyr)
# Data for 0.1 µM
data_0.1 <- data.frame(
Category = c("Non response", "CX-DOX mid-late response", "DOX only mid-late"),
Value = c(12308, 415, 1551),
Concentration = "0.1 µM"
)
# Data for 0.5 µM
data_0.5 <- data.frame(
Category = c("Non response", "DOX specific response", "DOX only mid-late response",
"CX + DOX (early) response", "DOX + CX (mid-late) response"),
Value = c(7134, 179, 6450, 142, 221),
Concentration = "0.5 µM"
)
# Combine both datasets
combined_data <- bind_rows(data_0.1, data_0.5)
# Add values to category names (for legend only)
combined_data$Category_Legend <- paste0(combined_data$Category, " (", combined_data$Value, ")")
# Define custom colors for updated categories
custom_colors <- c(
"Non response (12308)" = "#FF9999",
"CX-DOX mid-late response (415)" = "#66B2FF",
"DOX only mid-late (1551)" = "#99FF99",
"Non response (7134)" = "#FF9999",
"DOX specific response (179)" = "#FF66CC",
"DOX only mid-late response (6450)" = "#99FF99",
"CX + DOX (early) response (142)" = "#FFD700",
"DOX + CX (mid-late) response (221)" = "#8A2BE2"
)
# Ensure categories appear in a specific order
combined_data$Category_Legend <- factor(combined_data$Category_Legend, levels = names(custom_colors))
# Create faceted pie charts without numbers inside the slices
pie_chart <- ggplot(combined_data, aes(x = "", y = Value, fill = Category_Legend)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
facet_wrap(~ Concentration) + # Facet by concentration (side-by-side)
labs(title = "Corrmotif Pie Charts for 0.1 µM and 0.5 µM", x = NULL, y = NULL, fill = "Category") +
theme_void() +
theme(
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.5), # Adds box around facets
strip.background = element_rect(fill = "white", color = "black", linewidth = 1), # Box for facet titles
strip.text = element_text(size = 12, face = "bold", color = "black"),
legend.title = element_text(size = 12, face = "bold"), # Bold legend title
legend.text = element_text(size = 10) # Adjust legend text size
) +
scale_fill_manual(values = custom_colors)
# Display the plot
print(pie_chart)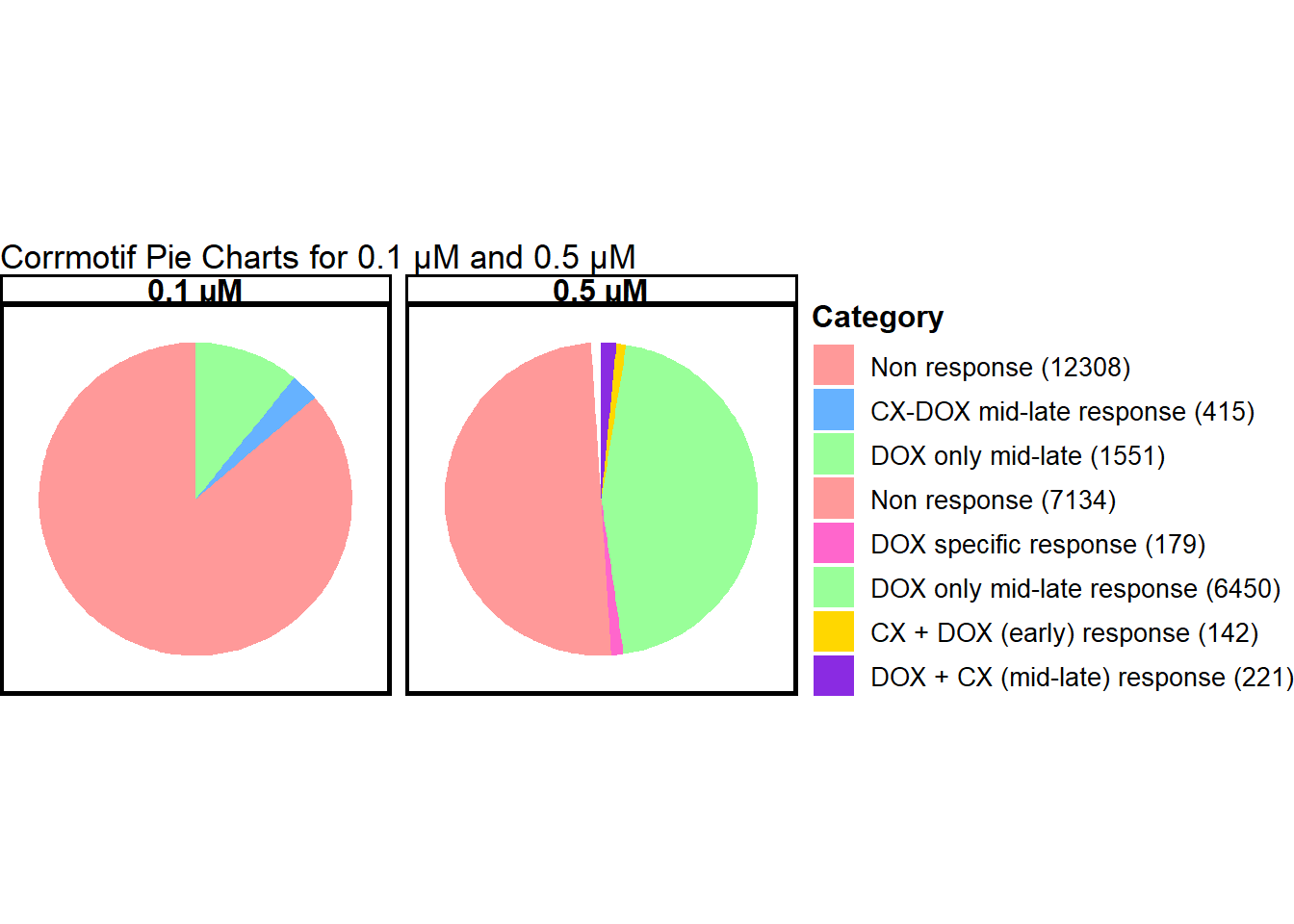
📌 Save Corr-motif datasets for Gene Ontology analysis (0.5 Micromolar)
write.csv(data.frame(Entrez_ID = prob_1_0.5), "data/prob_1_0.5.csv", row.names = FALSE)
write.csv(data.frame(Entrez_ID = prob_2_0.5), "data/prob_2_0.5.csv", row.names = FALSE)
write.csv(data.frame(Entrez_ID = prob_3_0.5), "data/prob_3_0.5.csv", row.names = FALSE)
write.csv(data.frame(Entrez_ID = prob_4_0.5), "data/prob_4_0.5.csv", row.names = FALSE)
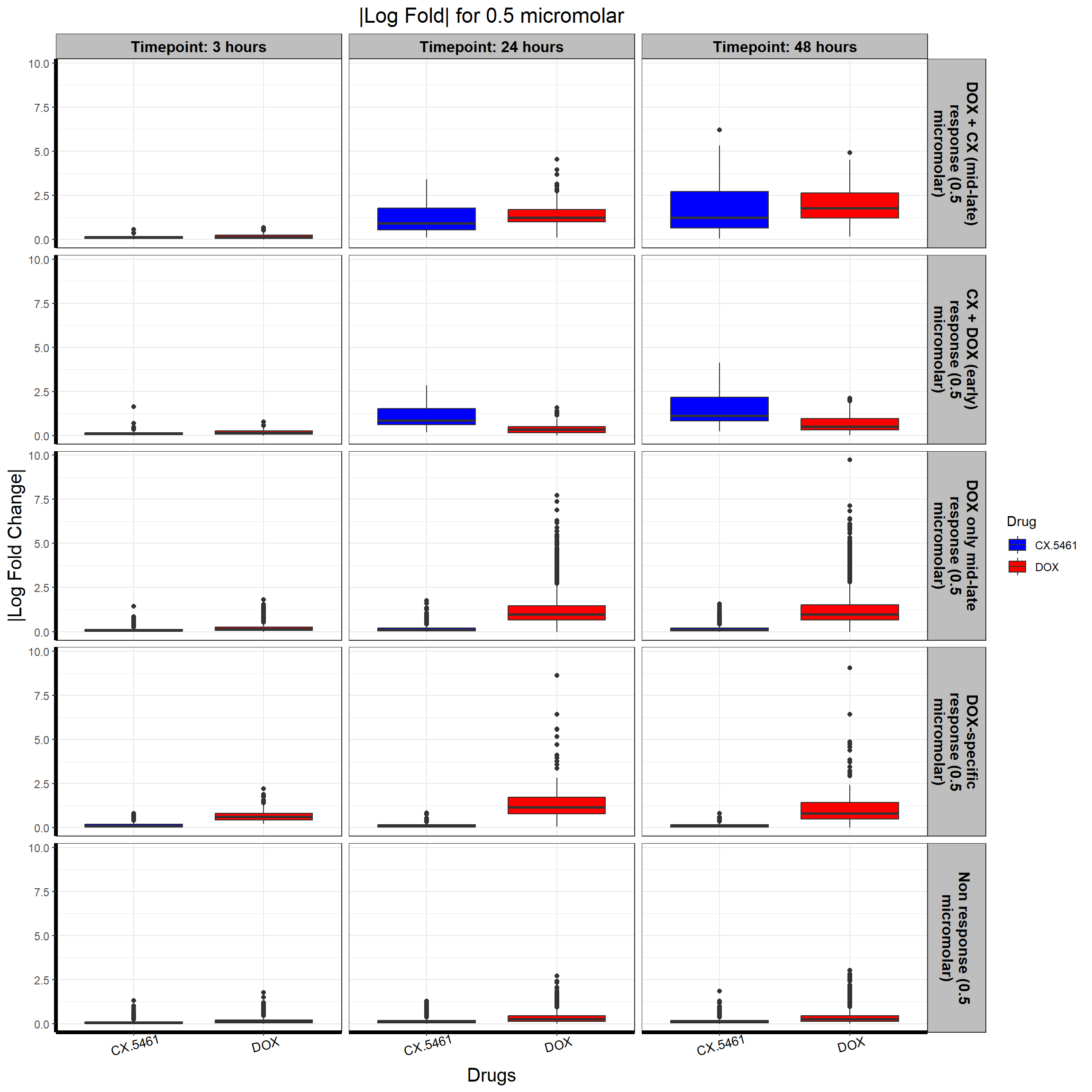
write.csv(data.frame(Entrez_ID = prob_5_0.5), "data/prob_5_0.5.csv", row.names = FALSE)📌 0.5 Micromolar abs logFC
# Load Response Groups from CSV Files
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# Load Datasets (Only 0.5 Micromolar)
CX_0.5_3 <- read.csv("data/DEGs/Toptable_CX_0.5_3.csv")
CX_0.5_24 <- read.csv("data/DEGs/Toptable_CX_0.5_24.csv")
CX_0.5_48 <- read.csv("data/DEGs/Toptable_CX_0.5_48.csv")
DOX_0.5_3 <- read.csv("data/DEGs/Toptable_DOX_0.5_3.csv")
DOX_0.5_24 <- read.csv("data/DEGs/Toptable_DOX_0.5_24.csv")
DOX_0.5_48 <- read.csv("data/DEGs/Toptable_DOX_0.5_48.csv")
# Convert datasets to DataFrames
Toptable_CX_0.5_3_df <- data.frame(CX_0.5_3)
Toptable_CX_0.5_24_df <- data.frame(CX_0.5_24)
Toptable_CX_0.5_48_df <- data.frame(CX_0.5_48)
Toptable_DOX_0.5_3_df <- data.frame(DOX_0.5_3)
Toptable_DOX_0.5_24_df <- data.frame(DOX_0.5_24)
Toptable_DOX_0.5_48_df <- data.frame(DOX_0.5_48)
# Combine All 0.5 Micromolar Datasets into a Single Dataframe
all_toptables_0.5 <- bind_rows(
Toptable_CX_0.5_3_df %>% mutate(Drug = "CX.5461", Timepoint = "3"),
Toptable_CX_0.5_24_df %>% mutate(Drug = "CX.5461", Timepoint = "24"),
Toptable_CX_0.5_48_df %>% mutate(Drug = "CX.5461", Timepoint = "48"),
Toptable_DOX_0.5_3_df %>% mutate(Drug = "DOX", Timepoint = "3"),
Toptable_DOX_0.5_24_df %>% mutate(Drug = "DOX", Timepoint = "24"),
Toptable_DOX_0.5_48_df %>% mutate(Drug = "DOX", Timepoint = "48")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.5$Entrez_ID <- as.character(all_toptables_0.5$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 micromolar)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response\n(0.5 micromolar)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response\n(0.5 micromolar)",
Entrez_ID %in% prob_4_0.5 ~ "CX + DOX (early) response\n(0.5 micromolar)",
Entrez_ID %in% prob_5_0.5 ~ "DOX + CX (mid-late) response\n(0.5 micromolar)",
TRUE ~ NA_character_
)
)
# Remove NA Values (Genes Not in Response Groups)
all_toptables_0.5 <- all_toptables_0.5 %>% filter(!is.na(Response_Group))
# Compute Absolute logFC
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(absFC = abs(logFC))
# Convert Factors for Proper Ordering (Reversed Order for Response Groups)
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Drug = factor(Drug, levels = c("CX.5461", "DOX")),
Timepoint = factor(Timepoint, levels = c("3", "24", "48"),
labels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group,
levels = c("DOX + CX (mid-late) response\n(0.5 micromolar)",
"CX + DOX (early) response\n(0.5 micromolar)",
"DOX only mid-late response\n(0.5 micromolar)",
"DOX-specific response\n(0.5 micromolar)",
"Non response\n(0.5 micromolar)")) # Reversed Order
)
# **Plot the Boxplot with Faceted Labels Wrapping Correctly**
ggplot(all_toptables_0.5, aes(x = Drug, y = absFC, fill = Drug)) +
geom_boxplot() +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) + # Custom color palette
facet_grid(Response_Group ~ Timepoint, labeller = label_wrap_gen(width = 20)) + # Ensure Proper Wrapping
theme_bw() +
labs(
x = "Drugs",
y = "|Log Fold Change|",
title = "|Log Fold| for 0.5 micromolar"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.line = element_line(linewidth = 1.5),
strip.background = element_rect(fill = "gray"), # Gray background for facet labels
strip.text = element_text(size = 12, color = "black", face = "bold"), # Bold styling for facet labels
axis.text.x = element_text(size = 10, color = "black", angle = 15)
)
📌 0.5 Micromolar mean (Abs logFC) across timepoints
# Load required libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# Load Datasets (Only 0.5 Micromolar)
CX_0.5_3 <- read.csv("data/DEGs/Toptable_CX_0.5_3.csv")
CX_0.5_24 <- read.csv("data/DEGs/Toptable_CX_0.5_24.csv")
CX_0.5_48 <- read.csv("data/DEGs/Toptable_CX_0.5_48.csv")
DOX_0.5_3 <- read.csv("data/DEGs/Toptable_DOX_0.5_3.csv")
DOX_0.5_24 <- read.csv("data/DEGs/Toptable_DOX_0.5_24.csv")
DOX_0.5_48 <- read.csv("data/DEGs/Toptable_DOX_0.5_48.csv")
# Combine All 0.5 Micromolar Datasets into a Single Dataframe
all_toptables_0.5 <- bind_rows(
CX_0.5_3 %>% mutate(Drug = "CX.5461", Timepoint = "3"),
CX_0.5_24 %>% mutate(Drug = "CX.5461", Timepoint = "24"),
CX_0.5_48 %>% mutate(Drug = "CX.5461", Timepoint = "48"),
DOX_0.5_3 %>% mutate(Drug = "DOX", Timepoint = "3"),
DOX_0.5_24 %>% mutate(Drug = "DOX", Timepoint = "24"),
DOX_0.5_48 %>% mutate(Drug = "DOX", Timepoint = "48")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.5$Entrez_ID <- as.character(all_toptables_0.5$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 micromolar)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response\n(0.5 micromolar)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response\n(0.5 micromolar)",
Entrez_ID %in% prob_4_0.5 ~ "CX + DOX (early) response\n(0.5 micromolar)",
Entrez_ID %in% prob_5_0.5 ~ "DOX + CX (mid-late) response\n(0.5 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) # Remove NA values
# Compute Mean Absolute logFC for Line Plot
data_summary <- all_toptables_0.5 %>%
mutate(abs_logFC = abs(logFC)) %>%
group_by(Response_Group, Drug, Timepoint) %>%
dplyr::summarize(mean_abs_logFC = mean(abs_logFC, na.rm = TRUE), .groups = "drop") %>%
as.data.frame()
# **Ensure all timepoints exist in the summary**
timepoints_full <- expand.grid(
Response_Group = unique(all_toptables_0.5$Response_Group),
Drug = unique(all_toptables_0.5$Drug),
Timepoint = c("3", "24", "48")
)
# **Merge to keep missing timepoints**
data_summary <- full_join(timepoints_full, data_summary, by = c("Response_Group", "Drug", "Timepoint"))
# **Replace NA mean_abs_logFC with 0 if no genes were present**
data_summary$mean_abs_logFC[is.na(data_summary$mean_abs_logFC)] <- 0
# Convert Factors for Proper Ordering (Reversed Order for Response Groups)
data_summary <- data_summary %>%
mutate(
Timepoint = factor(Timepoint, levels = c("3", "24", "48"), labels = c("3 hours", "24 hours", "48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX + CX (mid-late) response\n(0.5 micromolar)",
"CX + DOX (early) response\n(0.5 micromolar)",
"DOX only mid-late response\n(0.5 micromolar)",
"DOX-specific response\n(0.5 micromolar)",
"Non response\n(0.5 micromolar)" # Reversed order
))
)
# Define custom drug palette
drug_palette <- c("CX.5461" = "blue", "DOX" = "red")
# **Plot the Line Plot for Mean Absolute logFC**
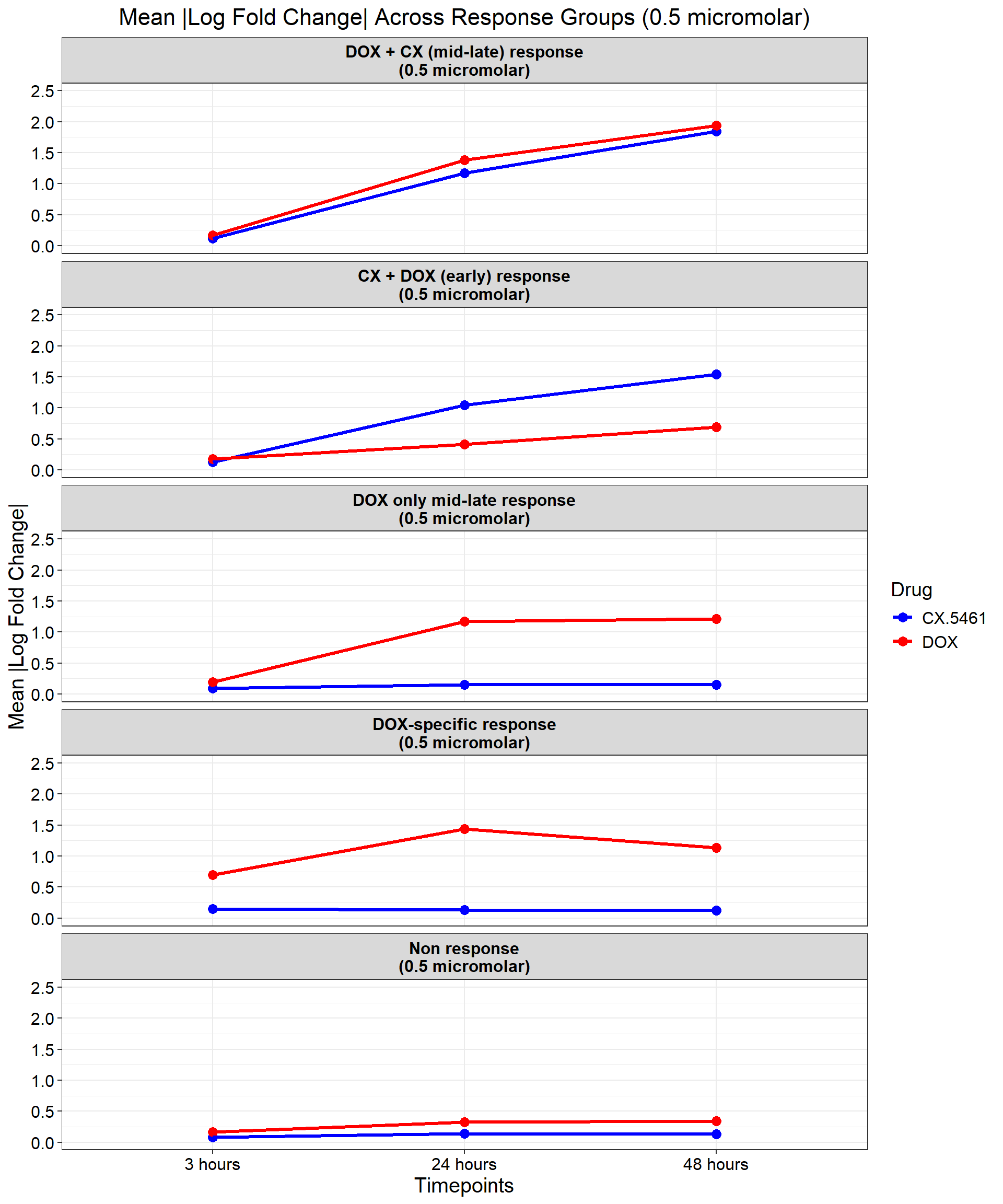
ggplot(data_summary, aes(x = Timepoint, y = mean_abs_logFC, group = Drug, color = Drug)) +
geom_point(size = 3) +
geom_line(size = 1.2) +
scale_color_manual(values = drug_palette) +
ylim(0, 2.5) + # Adjust the Y-axis for better visualization
facet_wrap(~ Response_Group, ncol = 1) + # Facet by Response Group (Reversed Order)
theme_bw() +
labs(
x = "Timepoints",
y = "Mean |Log Fold Change|",
title = "Mean |Log Fold Change| Across Response Groups (0.5 micromolar)",
color = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text = element_text(size = 12, color = "black"),
strip.text = element_text(size = 12, color = "black", face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)
📌 0.5 Micromolar logFC
# Load required libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# Load Datasets (Only 0.5 Micromolar)
CX_0.5_3 <- read.csv("data/DEGs/Toptable_CX_0.5_3.csv")
CX_0.5_24 <- read.csv("data/DEGs/Toptable_CX_0.5_24.csv")
CX_0.5_48 <- read.csv("data/DEGs/Toptable_CX_0.5_48.csv")
DOX_0.5_3 <- read.csv("data/DEGs/Toptable_DOX_0.5_3.csv")
DOX_0.5_24 <- read.csv("data/DEGs/Toptable_DOX_0.5_24.csv")
DOX_0.5_48 <- read.csv("data/DEGs/Toptable_DOX_0.5_48.csv")
# Combine All 0.5 Micromolar Datasets into a Single Dataframe
all_toptables_0.5 <- bind_rows(
CX_0.5_3 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 3 hours"),
CX_0.5_24 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 24 hours"),
CX_0.5_48 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 48 hours"),
DOX_0.5_3 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 3 hours"),
DOX_0.5_24 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 24 hours"),
DOX_0.5_48 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 48 hours")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.5$Entrez_ID <- as.character(all_toptables_0.5$Entrez_ID)
# Assign Response Groups
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 micromolar)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response\n(0.5 micromolar)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response\n(0.5 micromolar)",
Entrez_ID %in% prob_4_0.5 ~ "CX + DOX (early) response\n(0.5 micromolar)",
Entrez_ID %in% prob_5_0.5 ~ "DOX + CX (mid-late) response\n(0.5 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# Convert factors to ensure correct ordering (Reversed Order for Response Groups)
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Timepoint = factor(Timepoint, levels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX + CX (mid-late) response\n(0.5 micromolar)",
"CX + DOX (early) response\n(0.5 micromolar)",
"DOX only mid-late response\n(0.5 micromolar)",
"DOX-specific response\n(0.5 micromolar)",
"Non response\n(0.5 micromolar)" # Reversed Order
))
)
# **Plot the Boxplot**
ggplot(all_toptables_0.5, aes(x = Drug, y = logFC, fill = Drug)) +
geom_boxplot() +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) +
facet_grid(Response_Group ~ Timepoint) +
theme_bw() +
labs(x = "Drugs", y = "Log Fold Change", title = "Log Fold Change for 0.5 Micromolar") +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
strip.text = element_text(size = 12, face = "bold")
)
📌 0.5 Micromolar mean logFC across timepoints
# Load Required Libraries
library(dplyr)
library(ggplot2)
# Load Response Groups from CSV Files
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# Load Datasets (Only 0.5 Micromolar)
CX_0.5_3 <- read.csv("data/DEGs/Toptable_CX_0.5_3.csv")
CX_0.5_24 <- read.csv("data/DEGs/Toptable_CX_0.5_24.csv")
CX_0.5_48 <- read.csv("data/DEGs/Toptable_CX_0.5_48.csv")
DOX_0.5_3 <- read.csv("data/DEGs/Toptable_DOX_0.5_3.csv")
DOX_0.5_24 <- read.csv("data/DEGs/Toptable_DOX_0.5_24.csv")
DOX_0.5_48 <- read.csv("data/DEGs/Toptable_DOX_0.5_48.csv")
# Combine All 0.5 Micromolar Datasets into a Single Dataframe
all_toptables_0.5 <- bind_rows(
CX_0.5_3 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 3 hours"),
CX_0.5_24 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 24 hours"),
CX_0.5_48 %>% mutate(Drug = "CX.5461", Timepoint = "Timepoint: 48 hours"),
DOX_0.5_3 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 3 hours"),
DOX_0.5_24 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 24 hours"),
DOX_0.5_48 %>% mutate(Drug = "DOX", Timepoint = "Timepoint: 48 hours")
)
# Convert `Entrez_ID` to Character to Avoid `%in%` Issues
all_toptables_0.5$Entrez_ID <- as.character(all_toptables_0.5$Entrez_ID)
# Assign Response Groups with Line Breaks for Better Plotting
all_toptables_0.5 <- all_toptables_0.5 %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 micromolar)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response\n(0.5 micromolar)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response\n(0.5 micromolar)",
Entrez_ID %in% prob_4_0.5 ~ "CX + DOX (early) response\n(0.5 micromolar)",
Entrez_ID %in% prob_5_0.5 ~ "DOX + CX (mid-late) response\n(0.5 micromolar)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# Compute Mean logFC for Line Plot
data_summary_0.5 <- all_toptables_0.5 %>%
group_by(Response_Group, Drug, Timepoint) %>%
dplyr::summarize(mean_logFC = mean(logFC, na.rm = TRUE), .groups = "drop") %>%
as.data.frame()
# **Ensure all timepoints exist in the summary**
timepoints_full <- expand.grid(
Response_Group = unique(all_toptables_0.5$Response_Group),
Drug = unique(all_toptables_0.5$Drug),
Timepoint = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")
)
# **Merge to keep missing timepoints**
data_summary_0.5 <- full_join(timepoints_full, data_summary_0.5, by = c("Response_Group", "Drug", "Timepoint"))
# **Replace NA mean_logFC with 0 if no genes were present**
data_summary_0.5$mean_logFC[is.na(data_summary_0.5$mean_logFC)] <- 0
# Convert Factors for Proper Ordering (Reversed Order for Response Groups)
data_summary_0.5 <- data_summary_0.5 %>%
mutate(
Timepoint = factor(Timepoint, levels = c("Timepoint: 3 hours", "Timepoint: 24 hours", "Timepoint: 48 hours")),
Response_Group = factor(Response_Group, levels = c(
"DOX + CX (mid-late) response\n(0.5 micromolar)",
"CX + DOX (early) response\n(0.5 micromolar)",
"DOX only mid-late response\n(0.5 micromolar)",
"DOX-specific response\n(0.5 micromolar)",
"Non response\n(0.5 micromolar)" # Reversed Order
))
)
# Define custom drug palette
drug_palette <- c("CX.5461" = "blue", "DOX" = "red")
# **Plot the Line Plot for Mean logFC**
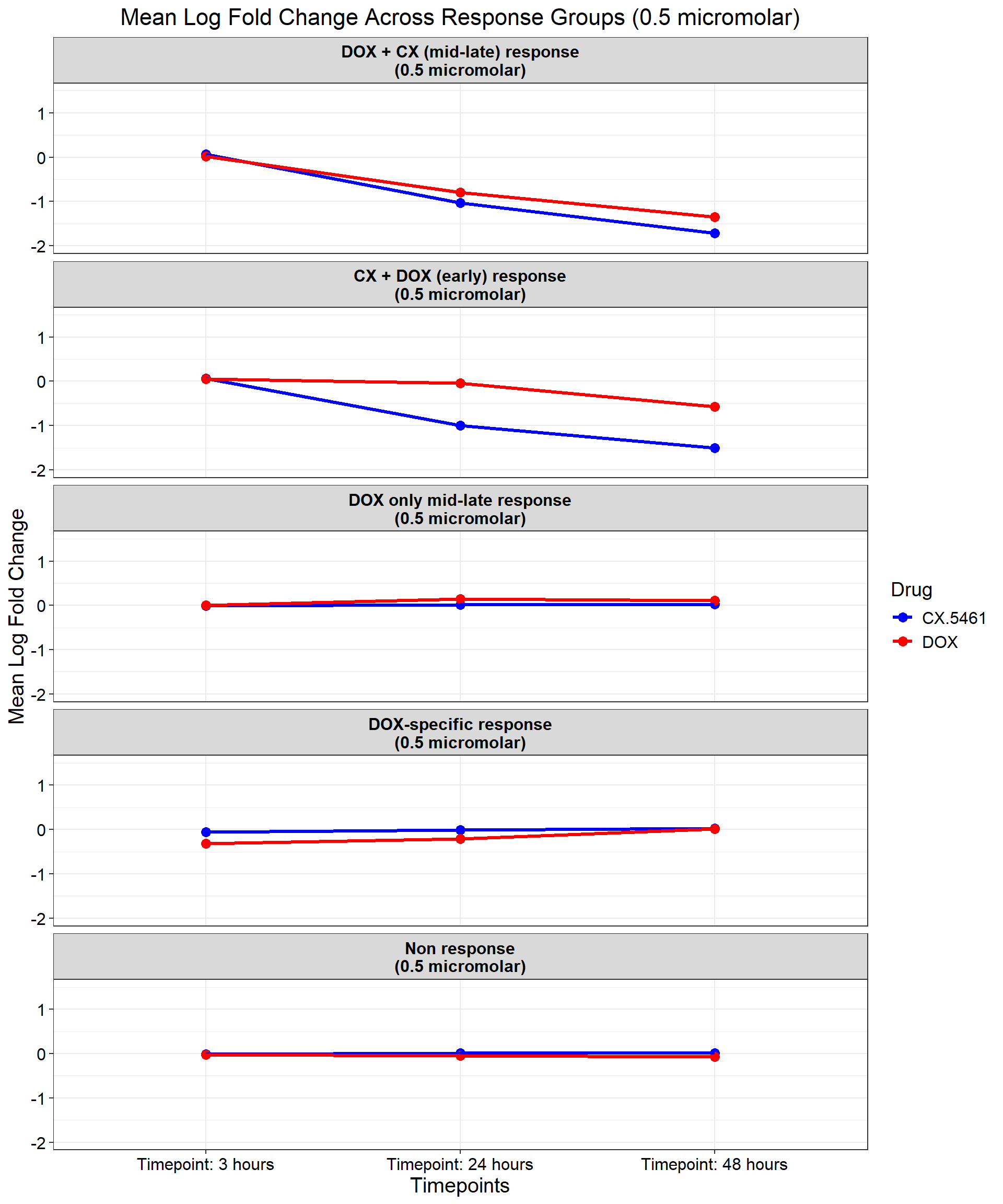
ggplot(data_summary_0.5, aes(x = Timepoint, y = mean_logFC, group = Drug, color = Drug)) +
geom_point(size = 3) +
geom_line(size = 1.2) +
scale_color_manual(values = drug_palette) +
ylim(-2, 1.5) + # Adjust the Y-axis for better visualization
facet_wrap(~ Response_Group, ncol = 1) + # Facet by Response Group (Reversed Order)
theme_bw() +
labs(
x = "Timepoints",
y = "Mean Log Fold Change",
title = "Mean Log Fold Change Across Response Groups (0.5 micromolar)",
color = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text = element_text(size = 12, color = "black"),
strip.text = element_text(size = 12, color = "black", face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)
📌 Proportion of DNA Damage Repair Genes (0.1 micromolar) (MD Anderson dataset)
# Load necessary libraries
library(dplyr)
library(ggplot2)
library(tidyr)Warning: package 'tidyr' was built under R version 4.3.3library(org.Hs.eg.db)Warning: package 'AnnotationDbi' was built under R version 4.3.2Warning: package 'IRanges' was built under R version 4.3.1Warning: package 'S4Vectors' was built under R version 4.3.2# **🔹 Read DNA Damage Repair Gene List**
DNA_damage <- read.csv("data/DNA_Damage.csv", stringsAsFactors = FALSE)
# Convert gene symbols to Entrez IDs
DNA_damage <- DNA_damage %>%
mutate(Entrez_ID = mapIds(org.Hs.eg.db,
keys = DNA_damage$Symbol,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"))
DNA_damage_genes <- na.omit(DNA_damage$Entrez_ID)
# **🔹 Load Corrmotif Groups for 0.1 Concentration**
prob_groups_0.1 <- list(
"Non Response (0.1)" = read.csv("data/prob_1_0.1.csv")$Entrez_ID,
"CX_DOX mid-late (0.1)" = read.csv("data/prob_2_0.1.csv")$Entrez_ID,
"DOX only mid-late (0.1)"= read.csv("data/prob_3_0.1.csv")$Entrez_ID
)
# **🔹 Create Dataframe for Corrmotif Groups**
corrmotif_df_0.1 <- bind_rows(
lapply(prob_groups_0.1, function(ids) {
data.frame(Entrez_ID = ids)
}),
.id = "Response_Group"
)
# **🔹 Match Entrez_IDs with DNA Damage Repair Genes**
corrmotif_df_0.1 <- corrmotif_df_0.1 %>%
mutate(DNA_Damage = ifelse(Entrez_ID %in% DNA_damage_genes, "Yes", "No"))
# **🔹 Count DNA Damage Repair Genes in Each Response Group**
proportion_data <- corrmotif_df_0.1 %>%
group_by(Response_Group, DNA_Damage) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Response_Group) %>%
mutate(Percentage = (Count / sum(Count)) * 100)
# **🔹 Ensure "Yes" is at the Bottom and "No" at the Top**
proportion_data$DNA_Damage <- factor(proportion_data$DNA_Damage, levels = c("Yes", "No"))
# **🔹 Set Order of Response Groups for X-axis**
response_order <- c("Non Response (0.1)", "CX_DOX mid-late (0.1)","DOX only mid-late (0.1)")
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = response_order)
# **🔹 Perform Chi-Square Tests for "DOX only mid-late (0.1)" and "CX_DOX mid-late (0.1)" vs "Non Response (0.1)"**
non_response_counts <- proportion_data %>%
filter(Response_Group == "Non Response (0.1)") %>%
dplyr::select(DNA_Damage, Count) %>%
{setNames(.$Count, .$DNA_Damage)} # Convert to named vector
chi_results <- proportion_data %>%
filter(Response_Group %in% c("CX_DOX mid-late (0.1)","DOX only mid-late (0.1)")) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[DNA_Damage %in% c("Yes", "No")]
if (!"Yes" %in% DNA_Damage) group_counts <- c(group_counts, 0)
if (!"No" %in% DNA_Damage) group_counts <- c(0, group_counts)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
non_response_counts["Yes"], non_response_counts["No"]
), nrow = 2, byrow = TRUE)
# Perform chi-square test if all values are valid
if (all(contingency_table >= 0 & is.finite(contingency_table))) {
chisq.test(contingency_table)$p.value
} else {
NA
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
# **🔹 Merge Chi-Square Results into Proportion Data**
proportion_data <- proportion_data %>%
left_join(chi_results %>% dplyr::select(Response_Group, Significance), by = "Response_Group")
# **🔹 Set Star Position Uniform Across Groups at 105%**
star_positions <- data.frame(
Response_Group = c("CX_DOX mid-late (0.1)", "DOX only mid-late (0.1)"),
y_pos = 105, # Fixed at 105% of Y-axis
Significance = chi_results$Significance
)
# **🔹 Generate Proportion Plot with Chi-Square Stars**
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = DNA_Damage)) +
geom_bar(stat = "identity", position = "stack") + # Stacked bars
geom_text(
data = star_positions,
aes(x = Response_Group, y = y_pos, label = Significance), # Place stars at fixed 105%
inherit.aes = FALSE,
size = 6, color = "black", fontface = "bold", vjust = 0 # Keeps stars aligned
) +
scale_y_continuous(labels = scales::percent_format(scale = 1), limits = c(0, 110)) + # Fixed Y-axis to 100%
scale_fill_manual(values = c("Yes" = "#e41a1c", "No" = "#377eb8")) + # Yes (Red), No (Blue)
labs(
title = "Proportion of DNA Damage Repair Genes in\n0.1 Corrmotif Response Groups",
x = "Response Groups (0.1 Concentration)",
y = "Percentage",
fill = "DNA Damage Repair"
) +
theme_minimal() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text.x = element_text(size = 10, angle = 45, hjust = 1),
legend.title = element_blank(),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
strip.background = element_blank(),
strip.text = element_text(size = 12, face = "bold")
)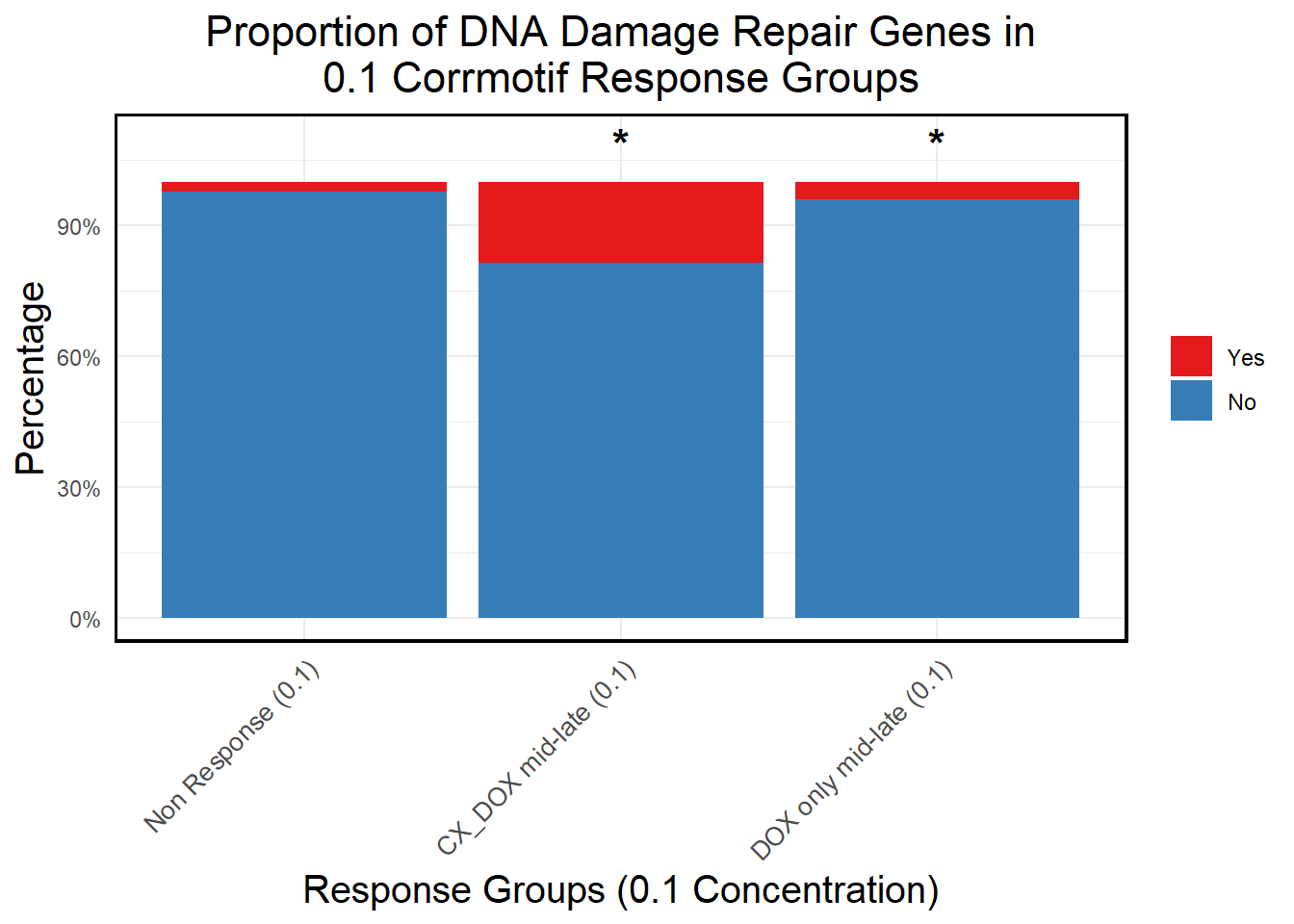
📌 Proportion of DNA Damage Repair Genes (0.5 micromolar) (MD Anderson dataset)
# Load necessary libraries
library(dplyr)
library(ggplot2)
library(tidyr)
library(org.Hs.eg.db)
# **🔹 Read DNA Damage Repair Gene List**
DNA_damage <- read.csv("data/DNA_Damage.csv", stringsAsFactors = FALSE)
# Convert gene symbols to Entrez IDs
DNA_damage <- DNA_damage %>%
mutate(Entrez_ID = mapIds(org.Hs.eg.db,
keys = DNA_damage$Symbol,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"))
DNA_damage_genes <- na.omit(DNA_damage$Entrez_ID)
# **🔹 Load Corrmotif Groups for 0.5 Concentration**
prob_groups_0.5 <- list(
"Non Response (0.5)" = read.csv("data/prob_1_0.5.csv")$Entrez_ID,
"DOX-specific response (0.5)" = read.csv("data/prob_2_0.5.csv")$Entrez_ID,
"DOX only mid-late response (0.5)" = read.csv("data/prob_3_0.5.csv")$Entrez_ID,
"CX DOX (early) response (0.5)" = read.csv("data/prob_4_0.5.csv")$Entrez_ID,
"DOX + CX (mid-late) response (0.5)" = read.csv("data/prob_5_0.5.csv")$Entrez_ID
)
# **🔹 Create Dataframe for Corrmotif Groups**
corrmotif_df_0.5 <- bind_rows(
lapply(prob_groups_0.5, function(ids) {
data.frame(Entrez_ID = ids)
}),
.id = "Response_Group"
)
# **🔹 Match Entrez_IDs with DNA Damage Repair Genes**
corrmotif_df_0.5 <- corrmotif_df_0.5 %>%
mutate(DNA_Damage = ifelse(Entrez_ID %in% DNA_damage_genes, "Yes", "No"))
# **🔹 Count DNA Damage Repair Genes in Each Response Group**
proportion_data <- corrmotif_df_0.5 %>%
group_by(Response_Group, DNA_Damage) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Response_Group) %>%
mutate(Percentage = (Count / sum(Count)) * 100)
# **🔹 Ensure "Yes" is at the Bottom and "No" at the Top**
proportion_data$DNA_Damage <- factor(proportion_data$DNA_Damage, levels = c("Yes", "No"))
# **🔹 Set Order of Response Groups for X-axis**
response_order <- c("Non Response (0.5)", "DOX-specific response (0.5)", "DOX only mid-late response (0.5)",
"CX DOX (early) response (0.5)", "DOX + CX (mid-late) response (0.5)")
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = response_order)
# **🔹 Perform Chi-Square Tests for Each Response Group vs Non-Response**
non_response_counts <- proportion_data %>%
filter(Response_Group == "Non Response (0.5)") %>%
dplyr::select(DNA_Damage, Count) %>%
{setNames(.$Count, .$DNA_Damage)} # Convert to named vector
# **Comparing Each Group Against "Non Response (0.5)"**
chi_results <- proportion_data %>%
filter(Response_Group %in% c("DOX-specific response (0.5)", "DOX only mid-late response (0.5)",
"CX DOX (early) response (0.5)", "DOX + CX (mid-late) response (0.5)")) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[DNA_Damage %in% c("Yes", "No")]
if (!"Yes" %in% DNA_Damage) group_counts <- c(group_counts, 0)
if (!"No" %in% DNA_Damage) group_counts <- c(0, group_counts)
contingency_table <- matrix(c(
group_counts[1], group_counts[2], # Response group counts
non_response_counts["Yes"], non_response_counts["No"] # Non-response counts
), nrow = 2, byrow = TRUE)
# Perform chi-square test if all values are valid
if (all(contingency_table >= 0 & is.finite(contingency_table))) {
chisq.test(contingency_table)$p.value
} else {
NA
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
# **🔹 Merge Chi-Square Results into Proportion Data**
proportion_data <- proportion_data %>%
left_join(chi_results %>% dplyr::select(Response_Group, Significance), by = "Response_Group")
# **🔹 Set Star Position Uniform Across Groups at 105%**
star_positions <- data.frame(
Response_Group = c("DOX-specific response (0.5)", "DOX only mid-late response (0.5)",
"CX DOX (early) response (0.5)", "DOX + CX (mid-late) response (0.5)"),
y_pos = 105, # Fixed at 105% of Y-axis
Significance = chi_results$Significance
)
# **🔹 Generate Proportion Plot with Chi-Square Stars**
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = DNA_Damage)) +
geom_bar(stat = "identity", position = "stack") + # Stacked bars
geom_text(
data = star_positions,
aes(x = Response_Group, y = y_pos, label = Significance), # Place stars at fixed 105%
inherit.aes = FALSE,
size = 6, color = "black", fontface = "bold", vjust = 0 # Keeps stars aligned
) +
scale_y_continuous(labels = scales::percent_format(scale = 1), limits = c(0, 110)) + # **Y-axis now limited to 110% for visibility**
scale_fill_manual(values = c("Yes" = "#e41a1c", "No" = "#377eb8")) + # Yes (Red), No (Blue)
labs(
title = "Proportion of DNA Damage Repair Genes in\n0.5 Corrmotif Response Groups",
x = "Response Groups (0.5 Concentration)",
y = "Percentage",
fill = "DNA Damage Repair Genes"
) +
theme_minimal() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.text.x = element_text(size = 10, angle = 45, hjust = 1),
legend.title = element_blank(),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
strip.background = element_blank(),
strip.text = element_text(size = 12, face = "bold")
)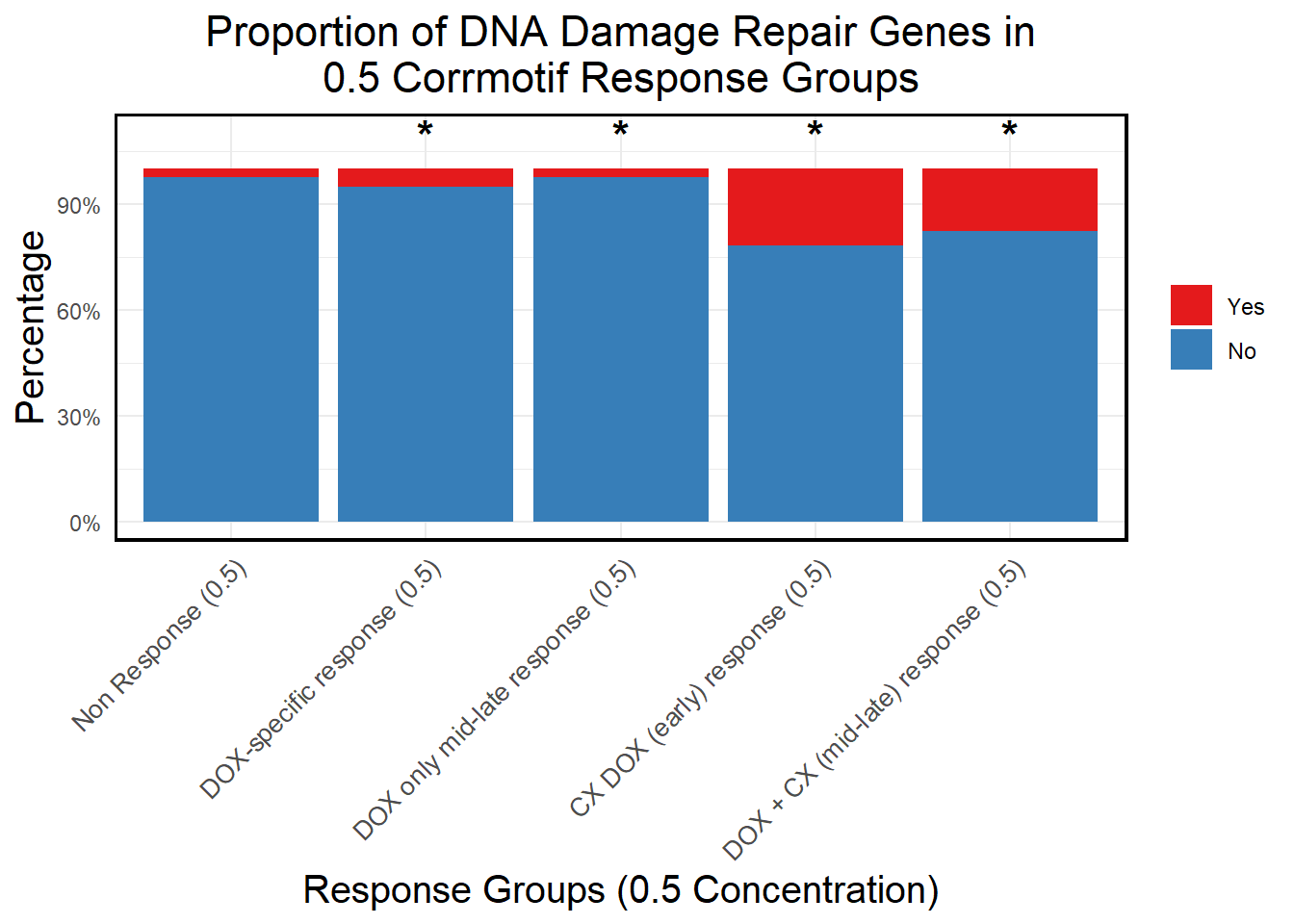
📌 Proportion of DNA Damage Repair Genes (Combined) (MD Anderson dataset)
# Load Required Libraries
library(dplyr)
library(ggplot2)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load DNA Damage Genes -----------------
DNA_damage <- read.csv("data/DNA_Damage.csv", stringsAsFactors = FALSE)
DNA_damage$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = DNA_damage$Symbol,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
dna_damage_ids <- na.omit(DNA_damage$Entrez_ID)
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% dna_damage_ids, "Yes", "No"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% dna_damage_ids, "Yes", "No"),
Concentration = "0.5 µM"
)
# ----------------- Combine All -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Set Order: "Yes" at bottom -----------------
proportion_data$Category <- factor(proportion_data$Category, levels = c("Yes", "No"))
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
dplyr::select(Category, Count) %>%
{setNames(.$Count, .$Category)}
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("Yes", "No")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["Yes"], ref_counts["No"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Perform tests
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
proportion_data <- proportion_data %>%
left_join(chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Positions -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(Significance == "*") %>%
mutate(y_pos = 105)
# ----------------- Stack Order -----------------
proportion_data <- proportion_data %>%
arrange(Concentration, Response_Group, Category)
# ----------------- Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5, color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c("Yes" = "#e41a1c", "No" = "#377eb8")) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "DNA Damage Gene Proportions Across\nCormotif Clusters (0.1 and 0.5 µM)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "DNA Damage Gene"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)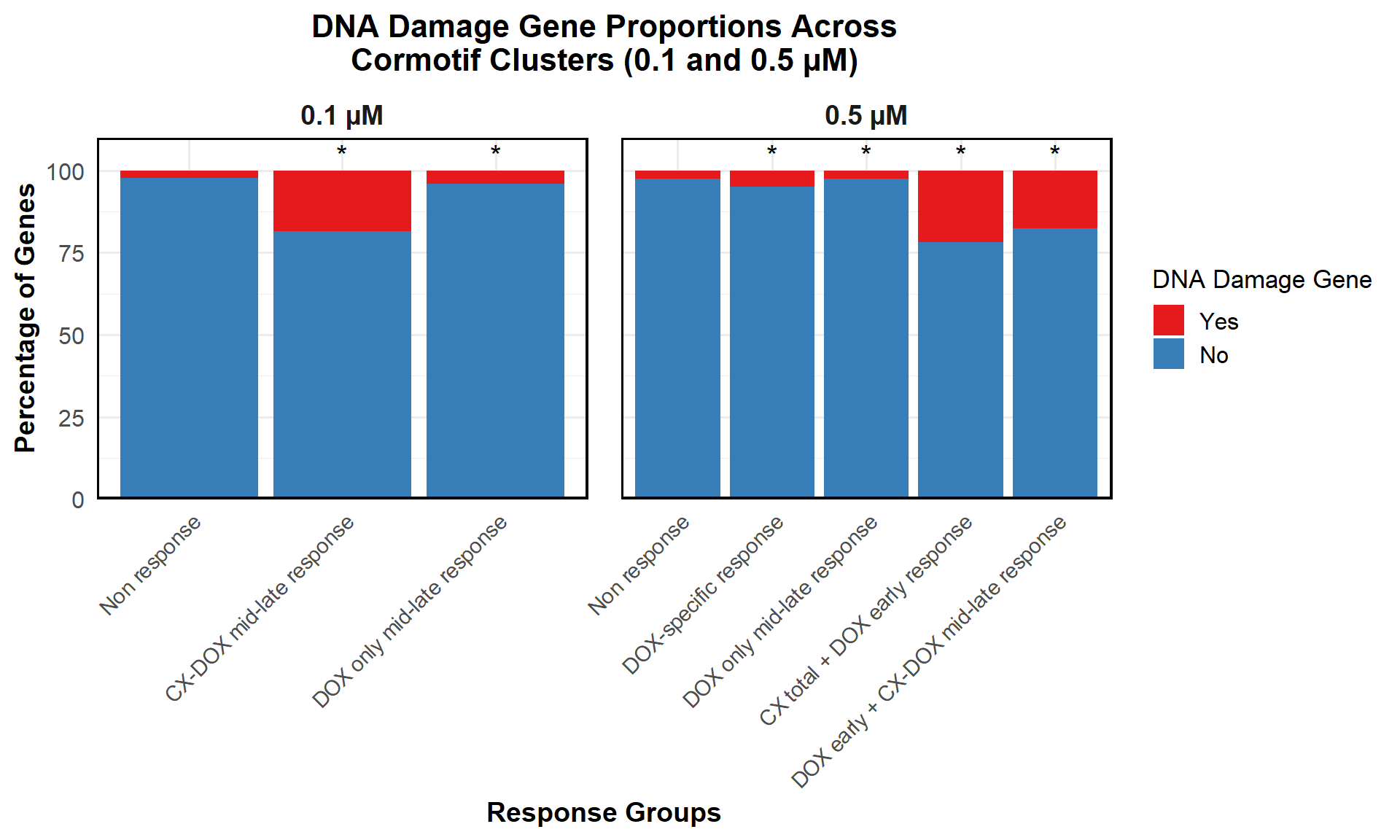
📌 Proportion of DNA Damage Response Genes (Molecular signature dataset)
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DDR Entrez IDs -----------------
ddr_entrez_ids <- as.character(c(
10111, 1017, 1019, 1020, 1021, 1026, 1027, 10912, 11011, 1111,
11200, 1385, 1643, 1647, 1869, 207, 2177, 25, 27113, 27244,
3014, 317, 355, 4193, 4292, 4361, 4609, 4616, 4683, 472, 50484,
5366, 5371, 54205, 545, 55367, 5591, 581, 5810, 5883, 5884,
5888, 5893, 5925, 595, 5981, 6118, 637, 672, 7157, 7799,
8243, 836, 841, 84126, 842, 8795, 891, 894, 896, 898,
9133, 9134, 983, 9874, 993, 995, 5916
))
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% ddr_entrez_ids, "DDR Genes", "Non-DDR Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% ddr_entrez_ids, "DDR Genes", "Non-DDR Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("DDR Genes", "Non-DDR Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["DDR Genes"], ref_counts["Non-DDR Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 1: `Response_Group = "CX-DOX mid-late response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")Warning: There were 2 warnings in `summarise()`.
The first warning was:
ℹ In argument: `p_value = { ... }`.
ℹ In group 1: `Response_Group = "CX total + DOX early response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrect
ℹ Run `dplyr::last_dplyr_warnings()` to see the 1 remaining warning.chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"DDR Genes" = "#E41A1C",
"Non-DDR Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "DNA Damage Response Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)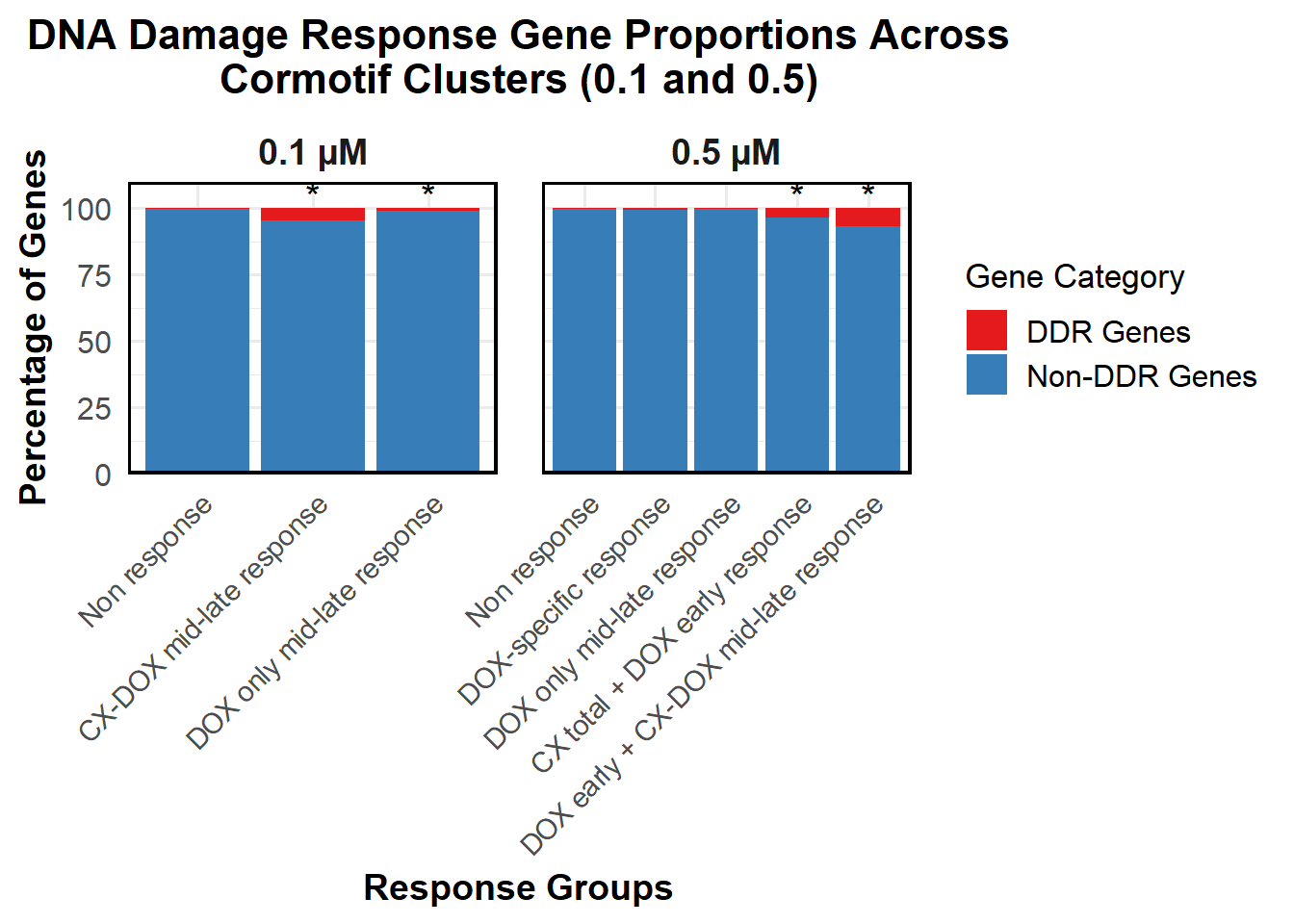
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DNA damage response genes across corrmotifs (Molecular signature dataset) (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)Warning: package 'tidyverse' was built under R version 4.3.2Warning: package 'readr' was built under R version 4.3.3Warning: package 'purrr' was built under R version 4.3.3Warning: package 'stringr' was built under R version 4.3.2Warning: package 'lubridate' was built under R version 4.3.3library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DDR Entrez IDs -----------------
entrez_ids <- c(
10111, 1017, 1019, 1020, 1021, 1026, 1027, 10912, 11011, 1111,
11200, 1385, 1643, 1647, 1869, 207, 2177, 25, 27113, 27244,
3014, 317, 355, 4193, 4292, 4361, 4609, 4616, 4683, 472, 50484,
5366, 5371, 54205, 545, 55367, 5591, 581, 5810, 5883, 5884,
5888, 5893, 5925, 595, 5981, 6118, 637, 672, 7157, 7799,
8243, 836, 841, 84126, 842, 8795, 891, 894, 896, 898,
9133, 9134, 983, 9874, 993, 995, 5916
)
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% as.character(entrez_ids)) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% as.character(entrez_ids)) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(
logFC = mean(logFC, na.rm = TRUE),
.groups = "drop"
)
# ----------------- Merge with CorMotif DDR Genes -----------------
ddr_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
ddr_logfc$Response_Group <- factor(ddr_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
star_df <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- ddr_logfc$logFC[ddr_logfc$Group == resp_group]
control_vals <- ddr_logfc$logFC[ddr_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
if (pval < 0.05) {
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
TRUE ~ "*"
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(Group = resp_group, y_pos = y_pos, label = label, P_Value = signif(pval, 4)))
}
}
return(NULL)
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- star_df %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(ddr_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of DDR Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)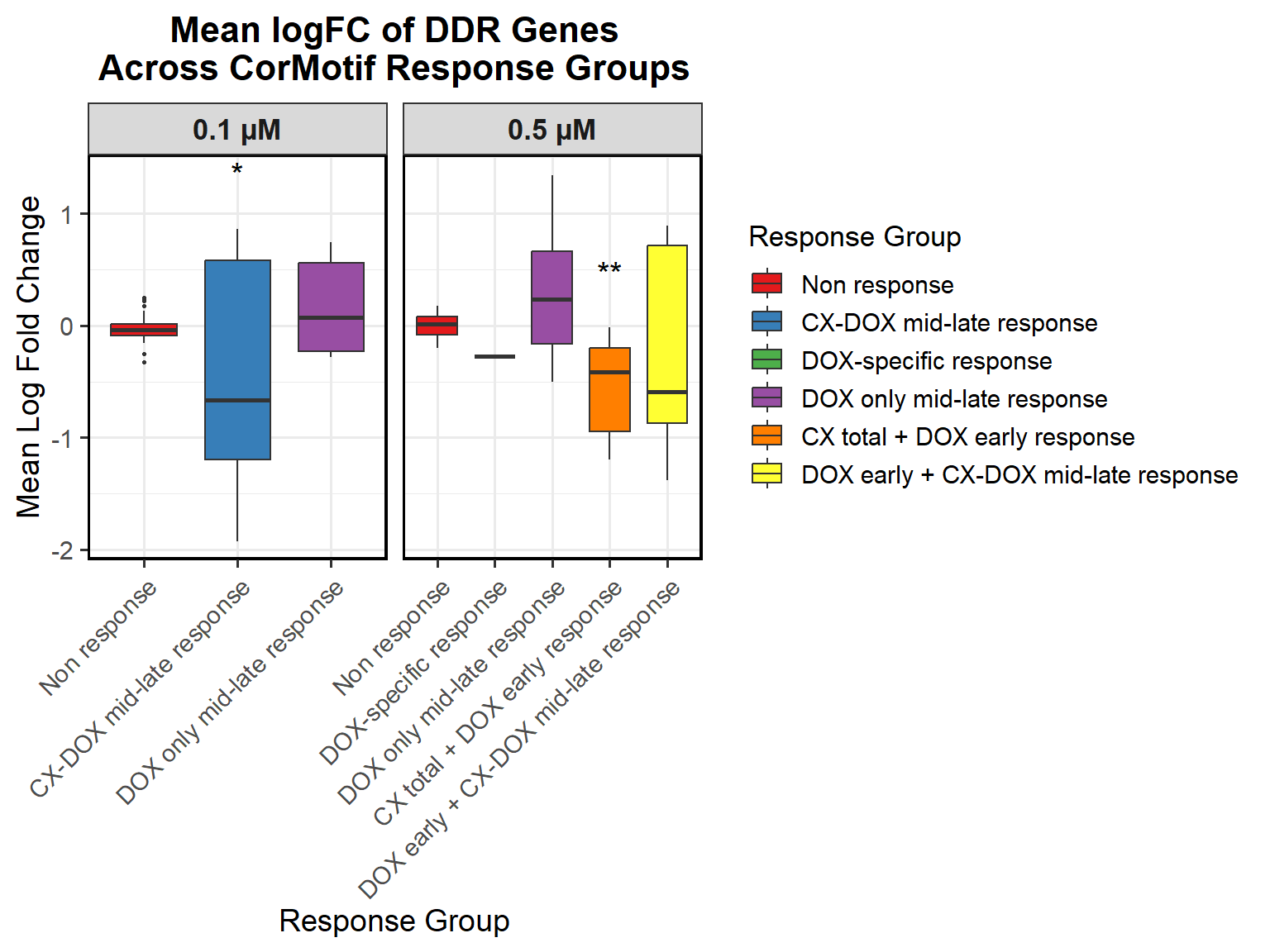
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DNA damage response genes across corrmotifs (Molecular signature dataset) (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DDR Entrez IDs -----------------
entrez_ids <- c(
10111, 1017, 1019, 1020, 1021, 1026, 1027, 10912, 11011, 1111,
11200, 1385, 1643, 1647, 1869, 207, 2177, 25, 27113, 27244,
3014, 317, 355, 4193, 4292, 4361, 4609, 4616, 4683, 472, 50484,
5366, 5371, 54205, 545, 55367, 5591, 581, 5810, 5883, 5884,
5888, 5893, 5925, 595, 5981, 6118, 637, 672, 7157, 7799,
8243, 836, 841, 84126, 842, 8795, 891, 894, 896, 898,
9133, 9134, 983, 9874, 993, 995, 5916
) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with CorMotif DDR Genes -----------------
ddr_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(ddr_all$Response_Group)[-1] # exclude "Non response"
stat_results <- list()
for (conc in unique(ddr_all$Concentration)) {
for (tp in levels(ddr_all$Timepoint)) {
sub <- ddr_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(ddr_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(ddr_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "DDR Gene logFC by CorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)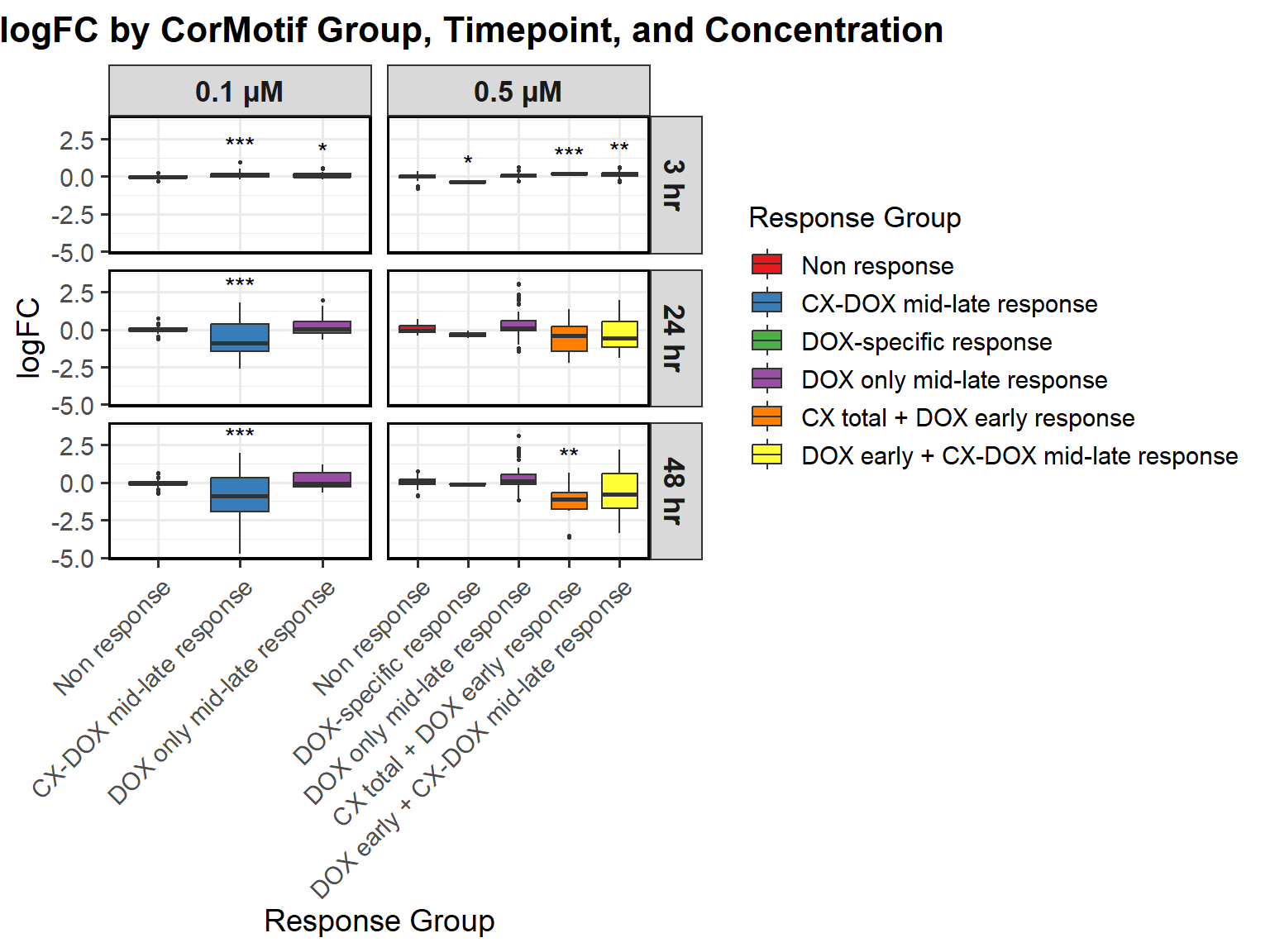
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DNA damage response genes across corrmotifs (Molecular signature dataset) (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DDR Entrez IDs -----------------
ddr_ids <- c(
10111, 1017, 1019, 1020, 1021, 1026, 1027, 10912, 11011, 1111,
11200, 1385, 1643, 1647, 1869, 207, 2177, 25, 27113, 27244,
3014, 317, 355, 4193, 4292, 4361, 4609, 4616, 4683, 472, 50484,
5366, 5371, 54205, 545, 55367, 5591, 581, 5810, 5883, 5884,
5888, 5893, 5925, 595, 5981, 6118, 637, 672, 7157, 7799,
8243, 836, 841, 84126, 842, 8795, 891, 894, 896, 898,
9133, 9134, 983, 9874, 993, 995, 5916
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% ddr_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM DDR) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "DDR Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)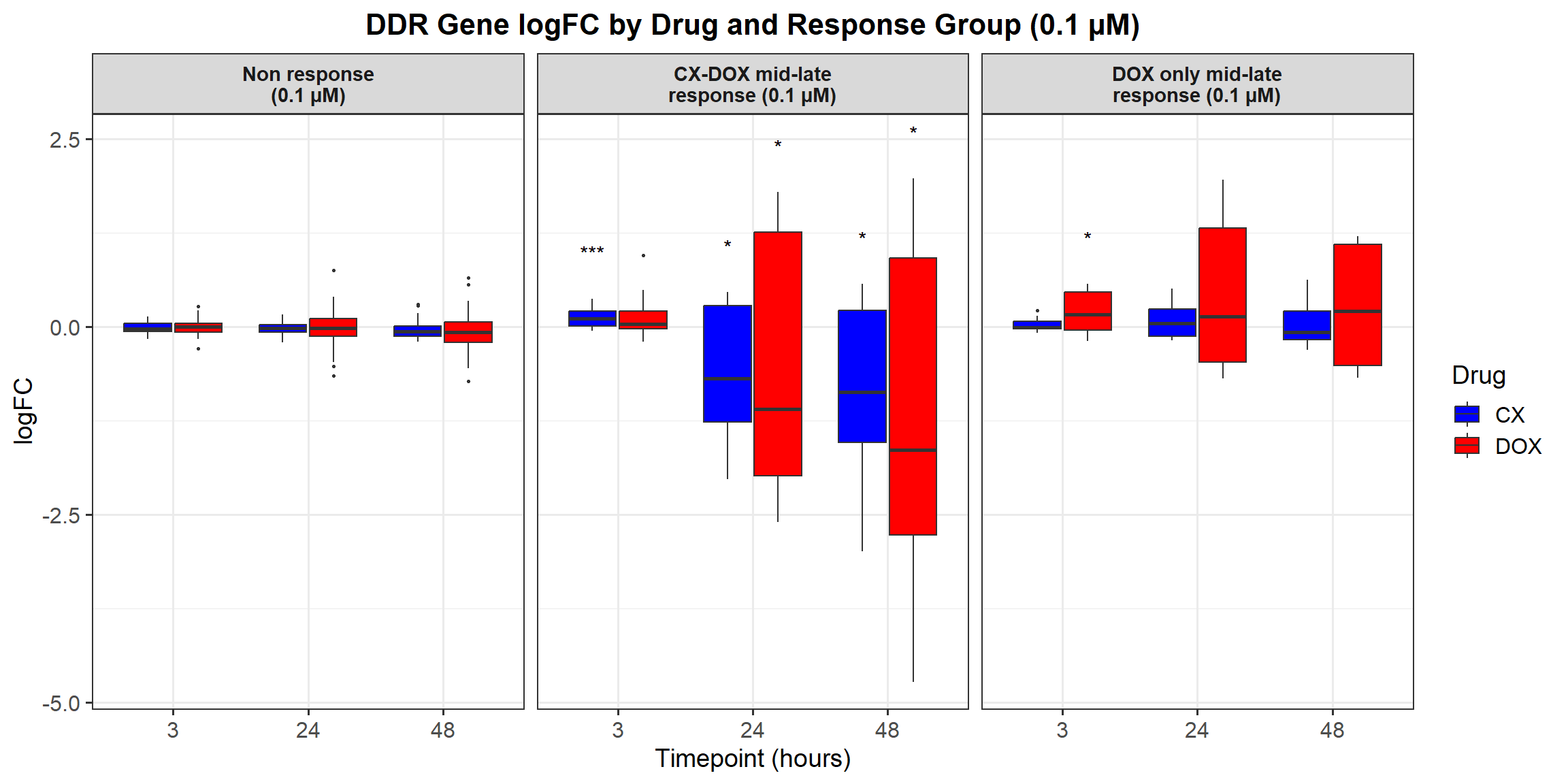
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### DDR Genes — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DDR Entrez IDs -----------------
ddr_ids <- c(
10111, 1017, 1019, 1020, 1021, 1026, 1027, 10912, 11011, 1111,
11200, 1385, 1643, 1647, 1869, 207, 2177, 25, 27113, 27244,
3014, 317, 355, 4193, 4292, 4361, 4609, 4616, 4683, 472, 50484,
5366, 5371, 54205, 545, 55367, 5591, 581, 5810, 5883, 5884,
5888, 5893, 5925, 595, 5981, 6118, 637, 672, 7157, 7799,
8243, 836, 841, 84126, 842, 8795, 891, 894, 896, 898,
9133, 9134, 983, 9874, 993, 995, 5916
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% ddr_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM DDR) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "DDR Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)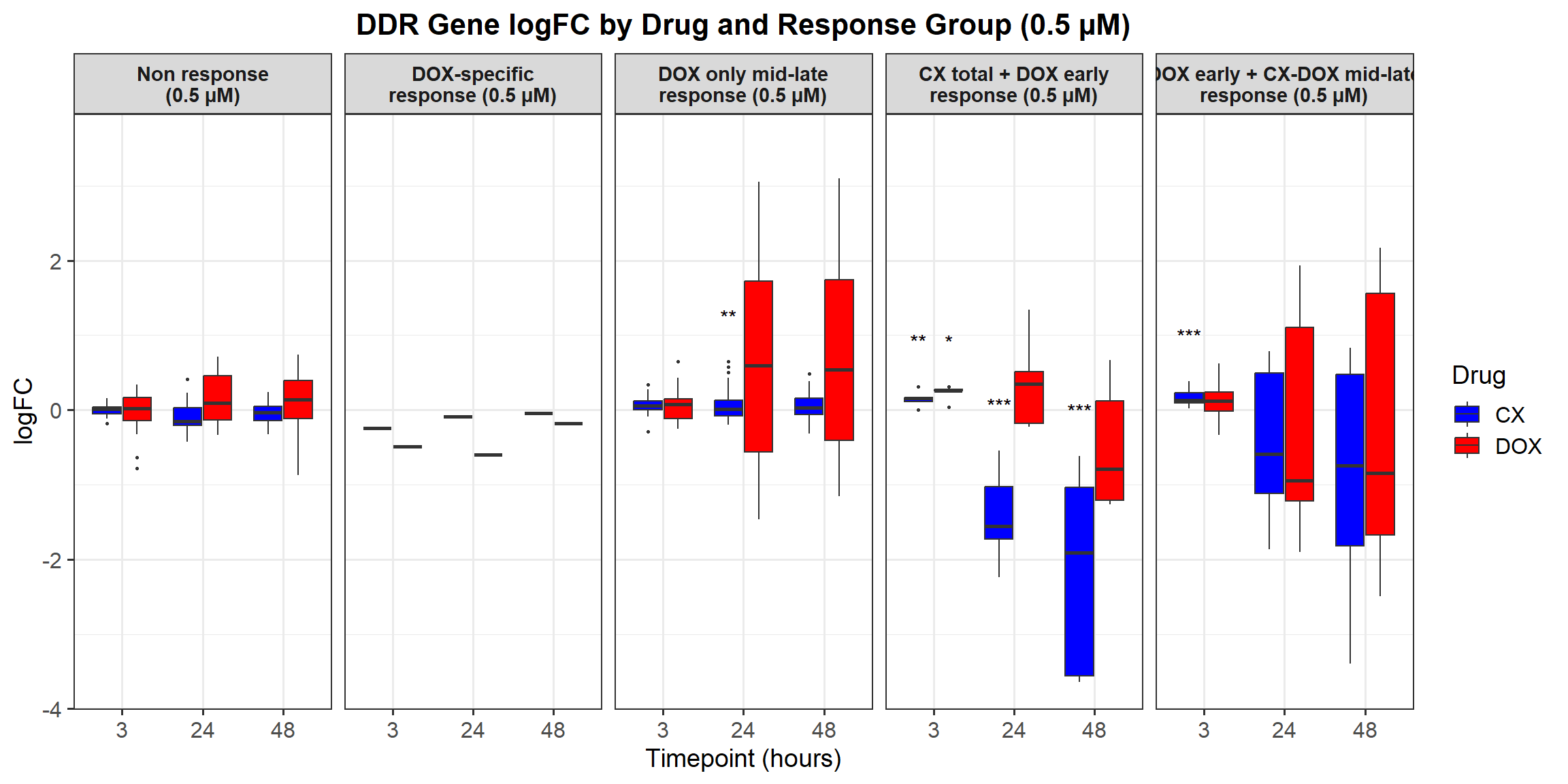
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of P53 target Genes across corrmotif clusters
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- P53 Entrez IDs -----------------
p53_entrez_ids <- as.character(c(
1026, 50484, 4193, 9766, 9518, 7832, 1643, 1647, 1263, 57103, 51065, 8795, 51499, 64393, 581, 5228, 5429, 8493, 55959,
7508, 64782, 282991, 355, 53836, 4814, 10769, 9050, 27244, 9540, 94241, 26154, 57763, 900, 26999, 55332, 26263, 23479,
23612, 29950, 9618, 10346, 8824, 134147, 55294, 22824, 4254, 6560, 467, 27113, 60492, 8444, 60401, 1969, 220965, 2232,
3976, 55191, 84284, 93129, 5564, 7803, 83667, 7779, 132671, 7039, 51768, 137695, 93134, 7633, 10973, 340485, 307,
27350, 23245, 3732, 29965, 1363, 1435, 196513, 8507, 8061, 2517, 51278, 53354, 54858, 23228, 5366, 5912, 6236, 51222,
26152, 59, 1907, 50650, 91012, 780, 9249, 11072, 144455, 64787, 116151, 27165, 2876, 57822, 55733, 57722, 121457,
375449, 85377, 4851, 5875, 127544, 29901, 84958, 8797, 8793, 441631, 220001, 54541, 5889, 5054, 25816, 25987, 5111,
98, 317, 598, 604, 10904, 1294, 80315, 53944, 1606, 2770, 3628, 3675, 3985, 4035, 4163, 84552, 29085, 55367, 5371,
5791, 54884, 5980, 8794, 1462, 50808, 220, 583, 694, 1056, 9076, 10978, 54677, 1612, 55040, 114907, 2274, 127707,
4000, 8079, 4646, 4747, 27445, 5143, 80055, 79156, 5360, 5364, 23654, 5565, 5613, 5625, 10076, 56963, 6004, 390,
255488, 6326, 6330, 23513, 7869, 283130, 204962, 83959, 6548, 6774, 9263, 10228, 22954, 10475, 85363, 494514, 10142,
79714, 1006, 8446, 9648, 79828, 5507, 55240, 63874, 25841, 9289, 84883, 154810, 51321, 421, 8553, 655, 119032, 84280,
10950, 824, 839, 57828, 857, 8812, 8837, 94027, 113189, 22837, 132864, 10898, 3300, 81704, 1847, 1849, 1947, 9538,
24139, 5168, 147965, 115548, 9873, 23768, 2632, 2817, 3280, 3265, 23308, 3490, 51477, 182, 3856, 8844, 144811, 9404,
4043, 9848, 2872, 23041, 740, 343263, 4638, 26509, 4792, 22861, 57523, 55214, 80025, 164091, 57060, 64065, 51090,
5453, 8496, 333926, 55671, 5900, 55544, 23179, 8601, 389, 6223, 55800, 6385, 4088, 6643, 122809, 257397, 285343,
7011, 54790, 374618, 55362, 51754, 7157, 9537, 22906, 7205, 80705, 219699, 55245, 83719, 7748, 25946, 118738
))
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% p53_entrez_ids, "P53 Target Genes", "Non-P53 Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% p53_entrez_ids, "P53 Target Genes", "Non-P53 Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order (P53 first) -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("P53 Target Genes", "Non-P53 Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("P53 Target Genes", "Non-P53 Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["P53 Target Genes"], ref_counts["Non-P53 Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 2: `Response_Group = "DOX early + CX-DOX mid-late response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"P53 Target Genes" = "#E41A1C",
"Non-P53 Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "P53 Target Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)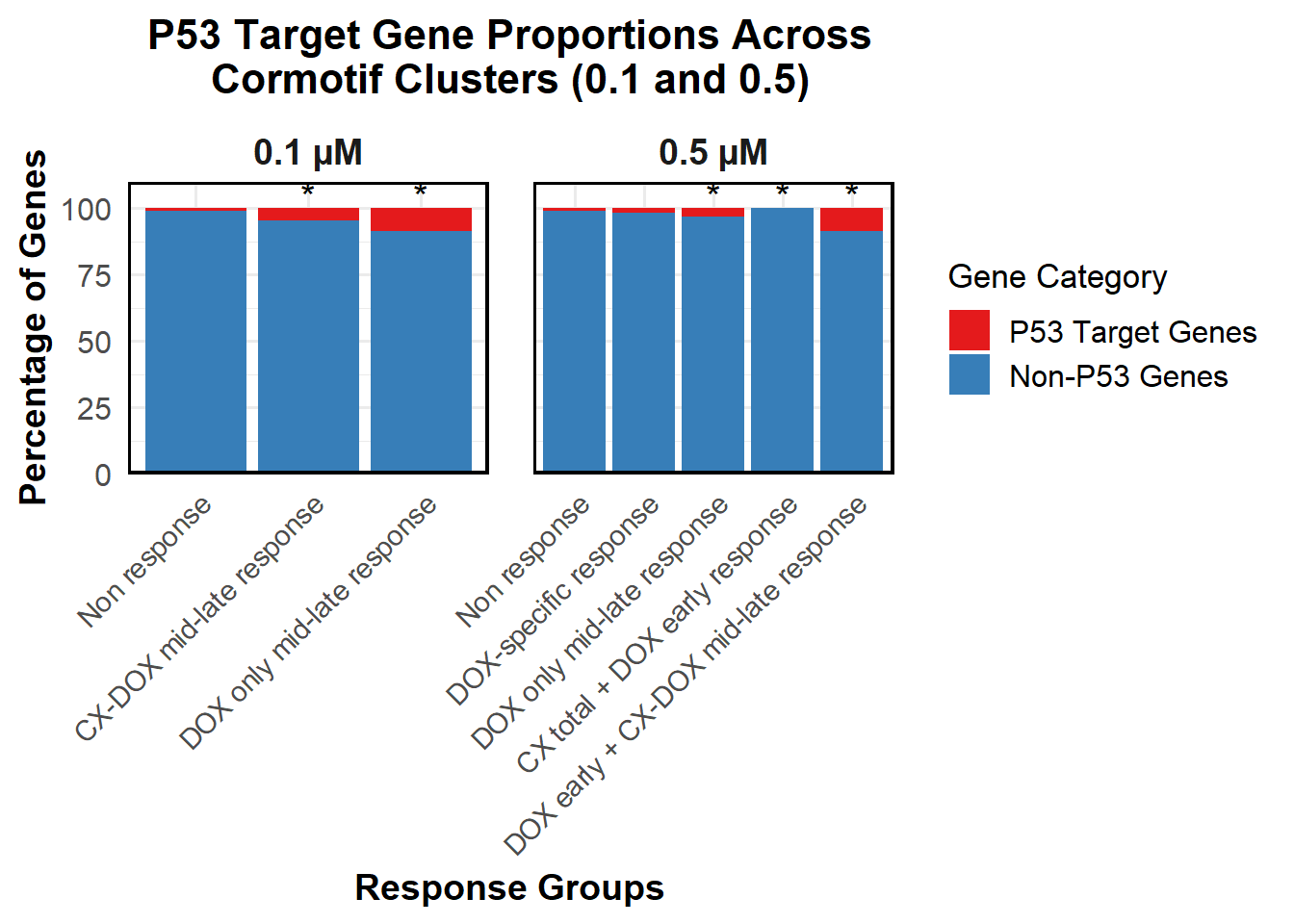
📌 Mean logFC of P53 target genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- P53 Entrez IDs -----------------
entrez_ids <- c(
1026, 50484, 4193, 9766, 9518, 7832, 1643, 1647, 1263, 57103, 51065, 8795, 51499, 64393, 581, 5228, 5429, 8493, 55959,
7508, 64782, 282991, 355, 53836, 4814, 10769, 9050, 27244, 9540, 94241, 26154, 57763, 900, 26999, 55332, 26263, 23479,
23612, 29950, 9618, 10346, 8824, 134147, 55294, 22824, 4254, 6560, 467, 27113, 60492, 8444, 60401, 1969, 220965, 2232,
3976, 55191, 84284, 93129, 5564, 7803, 83667, 7779, 132671, 7039, 51768, 137695, 93134, 7633, 10973, 340485, 307,
27350, 23245, 3732, 29965, 1363, 1435, 196513, 8507, 8061, 2517, 51278, 53354, 54858, 23228, 5366, 5912, 6236, 51222,
26152, 59, 1907, 50650, 91012, 780, 9249, 11072, 144455, 64787, 116151, 27165, 2876, 57822, 55733, 57722, 121457,
375449, 85377, 4851, 5875, 127544, 29901, 84958, 8797, 8793, 441631, 220001, 54541, 5889, 5054, 25816, 25987, 5111,
98, 317, 598, 604, 10904, 1294, 80315, 53944, 1606, 2770, 3628, 3675, 3985, 4035, 4163, 84552, 29085, 55367, 5371,
5791, 54884, 5980, 8794, 1462, 50808, 220, 583, 694, 1056, 9076, 10978, 54677, 1612, 55040, 114907, 2274, 127707,
4000, 8079, 4646, 4747, 27445, 5143, 80055, 79156, 5360, 5364, 23654, 5565, 5613, 5625, 10076, 56963, 6004, 390,
255488, 6326, 6330, 23513, 7869, 283130, 204962, 83959, 6548, 6774, 9263, 10228, 22954, 10475, 85363, 494514, 10142,
79714, 1006, 8446, 9648, 79828, 5507, 55240, 63874, 25841, 9289, 84883, 154810, 51321, 421, 8553, 655, 119032, 84280,
10950, 824, 839, 57828, 857, 8812, 8837, 94027, 113189, 22837, 132864, 10898, 3300, 81704, 1847, 1849, 1947, 9538,
24139, 5168, 147965, 115548, 9873, 23768, 2632, 2817, 3280, 3265, 23308, 3490, 51477, 182, 3856, 8844, 144811, 9404,
4043, 9848, 2872, 23041, 740, 343263, 4638, 26509, 4792, 22861, 57523, 55214, 80025, 164091, 57060, 64065, 51090,
5453, 8496, 333926, 55671, 5900, 55544, 23179, 8601, 389, 6223, 55800, 6385, 4088, 6643, 122809, 257397, 285343,
7011, 54790, 374618, 55362, 51754, 7157, 9537, 22906, 7205, 80705, 219699, 55245, 83719, 7748, 25946, 118738
)
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% as.character(entrez_ids)) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% as.character(entrez_ids)) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif P53 Genes -----------------
p53_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
p53_logfc$Response_Group <- factor(p53_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
star_df <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- p53_logfc$logFC[p53_logfc$Group == resp_group]
control_vals <- p53_logfc$logFC[p53_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
if (pval < 0.05) {
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
TRUE ~ "*"
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(Group = resp_group, y_pos = y_pos, label = label, P_Value = signif(pval, 4)))
}
}
return(NULL)
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- star_df %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(p53_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of P53 Target Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)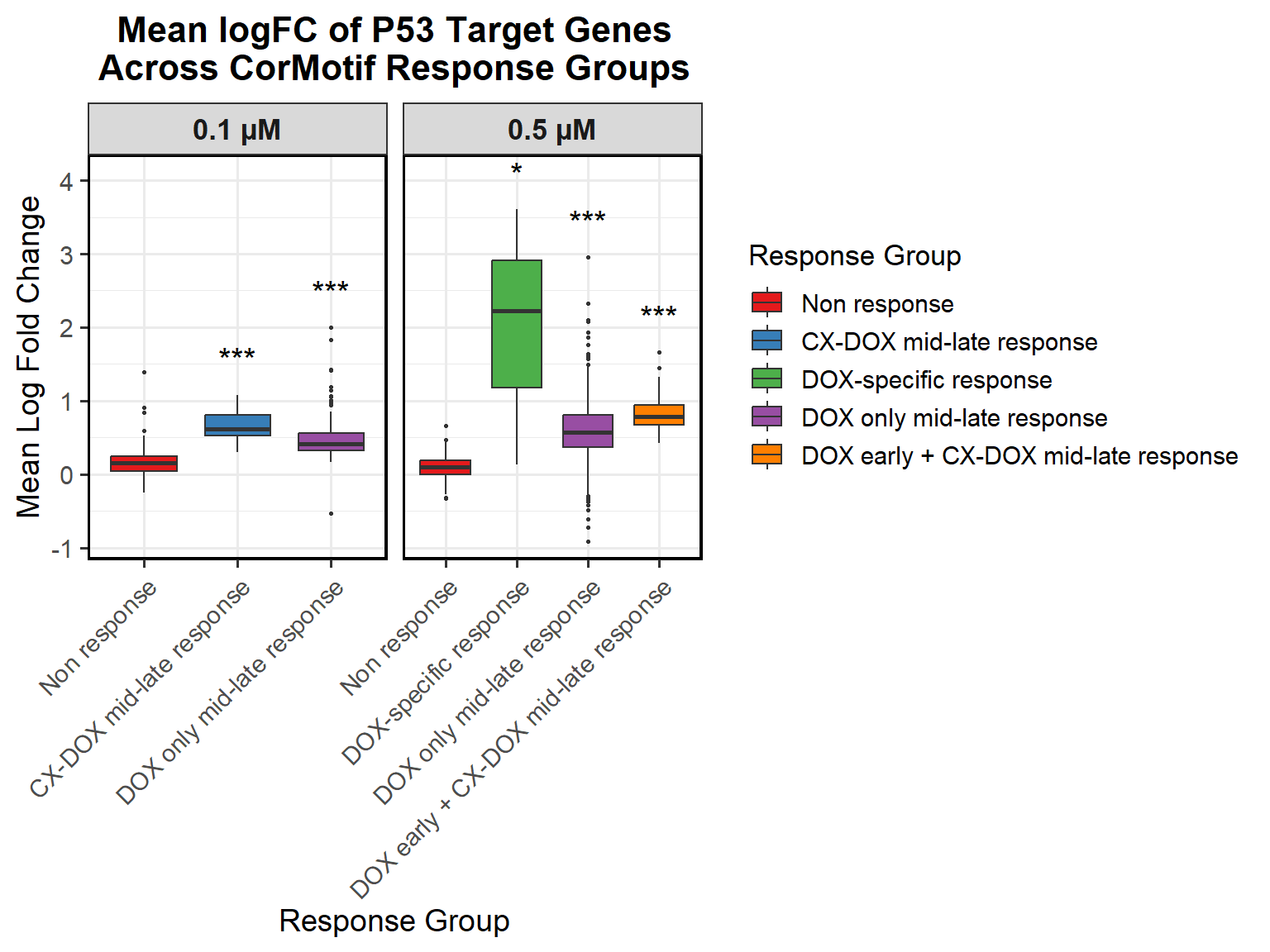
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of P53 target genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- P53 Entrez IDs -----------------
entrez_ids <- c(
1026, 50484, 4193, 9766, 9518, 7832, 1643, 1647, 1263, 57103, 51065, 8795, 51499, 64393, 581, 5228, 5429, 8493, 55959,
7508, 64782, 282991, 355, 53836, 4814, 10769, 9050, 27244, 9540, 94241, 26154, 57763, 900, 26999, 55332, 26263, 23479,
23612, 29950, 9618, 10346, 8824, 134147, 55294, 22824, 4254, 6560, 467, 27113, 60492, 8444, 60401, 1969, 220965, 2232,
3976, 55191, 84284, 93129, 5564, 7803, 83667, 7779, 132671, 7039, 51768, 137695, 93134, 7633, 10973, 340485, 307,
27350, 23245, 3732, 29965, 1363, 1435, 196513, 8507, 8061, 2517, 51278, 53354, 54858, 23228, 5366, 5912, 6236, 51222,
26152, 59, 1907, 50650, 91012, 780, 9249, 11072, 144455, 64787, 116151, 27165, 2876, 57822, 55733, 57722, 121457,
375449, 85377, 4851, 5875, 127544, 29901, 84958, 8797, 8793, 441631, 220001, 54541, 5889, 5054, 25816, 25987, 5111,
98, 317, 598, 604, 10904, 1294, 80315, 53944, 1606, 2770, 3628, 3675, 3985, 4035, 4163, 84552, 29085, 55367, 5371,
5791, 54884, 5980, 8794, 1462, 50808, 220, 583, 694, 1056, 9076, 10978, 54677, 1612, 55040, 114907, 2274, 127707,
4000, 8079, 4646, 4747, 27445, 5143, 80055, 79156, 5360, 5364, 23654, 5565, 5613, 5625, 10076, 56963, 6004, 390,
255488, 6326, 6330, 23513, 7869, 283130, 204962, 83959, 6548, 6774, 9263, 10228, 22954, 10475, 85363, 494514, 10142,
79714, 1006, 8446, 9648, 79828, 5507, 55240, 63874, 25841, 9289, 84883, 154810, 51321, 421, 8553, 655, 119032, 84280,
10950, 824, 839, 57828, 857, 8812, 8837, 94027, 113189, 22837, 132864, 10898, 3300, 81704, 1847, 1849, 1947, 9538,
24139, 5168, 147965, 115548, 9873, 23768, 2632, 2817, 3280, 3265, 23308, 3490, 51477, 182, 3856, 8844, 144811, 9404,
4043, 9848, 2872, 23041, 740, 343263, 4638, 26509, 4792, 22861, 57523, 55214, 80025, 164091, 57060, 64065, 51090,
5453, 8496, 333926, 55671, 5900, 55544, 23179, 8601, 389, 6223, 55800, 6385, 4088, 6643, 122809, 257397, 285343,
7011, 54790, 374618, 55362, 51754, 7157, 9537, 22906, 7205, 80705, 219699, 55245, 83719, 7748, 25946, 118738
) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with P53 Targets and Annotate -----------------
p53_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(p53_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(p53_all$Concentration)) {
for (tp in levels(p53_all$Timepoint)) {
sub <- p53_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(p53_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(p53_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "P53 Target Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)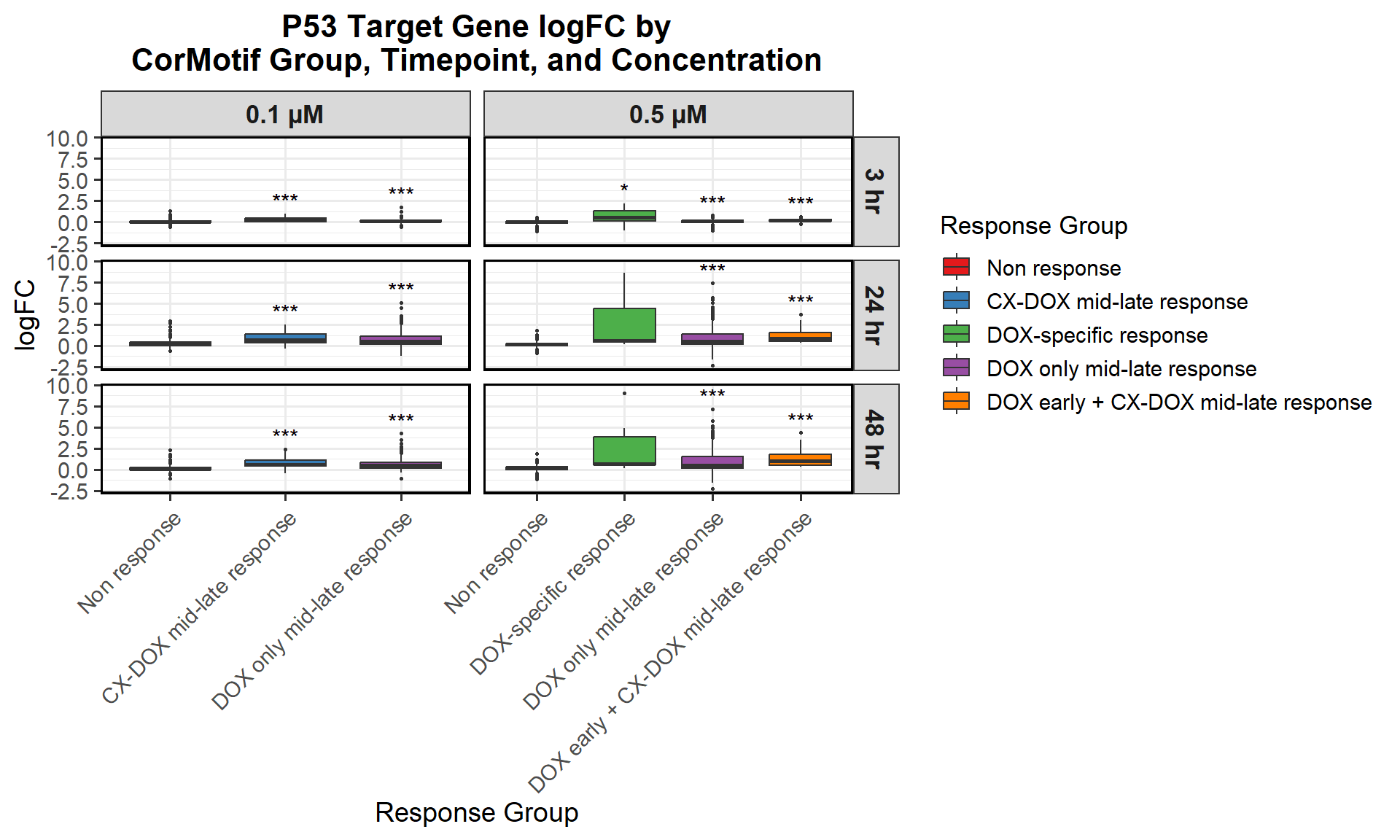
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of P53 target genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- P53 Target Entrez IDs -----------------
p53_ids <- c(
1026, 50484, 4193, 9766, 9518, 7832, 1643, 1647, 1263, 57103, 51065, 8795, 51499, 64393, 581, 5228, 5429, 8493, 55959,
7508, 64782, 282991, 355, 53836, 4814, 10769, 9050, 27244, 9540, 94241, 26154, 57763, 900, 26999, 55332, 26263, 23479,
23612, 29950, 9618, 10346, 8824, 134147, 55294, 22824, 4254, 6560, 467, 27113, 60492, 8444, 60401, 1969, 220965, 2232,
3976, 55191, 84284, 93129, 5564, 7803, 83667, 7779, 132671, 7039, 51768, 137695, 93134, 7633, 10973, 340485, 307,
27350, 23245, 3732, 29965, 1363, 1435, 196513, 8507, 8061, 2517, 51278, 53354, 54858, 23228, 5366, 5912, 6236, 51222,
26152, 59, 1907, 50650, 91012, 780, 9249, 11072, 144455, 64787, 116151, 27165, 2876, 57822, 55733, 57722, 121457,
375449, 85377, 4851, 5875, 127544, 29901, 84958, 8797, 8793, 441631, 220001, 54541, 5889, 5054, 25816, 25987, 5111,
98, 317, 598, 604, 10904, 1294, 80315, 53944, 1606, 2770, 3628, 3675, 3985, 4035, 4163, 84552, 29085, 55367, 5371,
5791, 54884, 5980, 8794, 1462, 50808, 220, 583, 694, 1056, 9076, 10978, 54677, 1612, 55040, 114907, 2274, 127707,
4000, 8079, 4646, 4747, 27445, 5143, 80055, 79156, 5360, 5364, 23654, 5565, 5613, 5625, 10076, 56963, 6004, 390,
255488, 6326, 6330, 23513, 7869, 283130, 204962, 83959, 6548, 6774, 9263, 10228, 22954, 10475, 85363, 494514, 10142,
79714, 1006, 8446, 9648, 79828, 5507, 55240, 63874, 25841, 9289, 84883, 154810, 51321, 421, 8553, 655, 119032, 84280,
10950, 824, 839, 57828, 857, 8812, 8837, 94027, 113189, 22837, 132864, 10898, 3300, 81704, 1847, 1849, 1947, 9538,
24139, 5168, 147965, 115548, 9873, 23768, 2632, 2817, 3280, 3265, 23308, 3490, 51477, 182, 3856, 8844, 144811, 9404,
4043, 9848, 2872, 23041, 740, 343263, 4638, 26509, 4792, 22861, 57523, 55214, 80025, 164091, 57060, 64065, 51090,
5453, 8496, 333926, 55671, 5900, 55544, 23179, 8601, 389, 6223, 55800, 6385, 4088, 6643, 122809, 257397, 285343,
7011, 54790, 374618, 55362, 51754, 7157, 9537, 22906, 7205, 80705, 219699, 55245, 83719, 7748, 25946, 118738
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% p53_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM P53) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "P53 Target Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)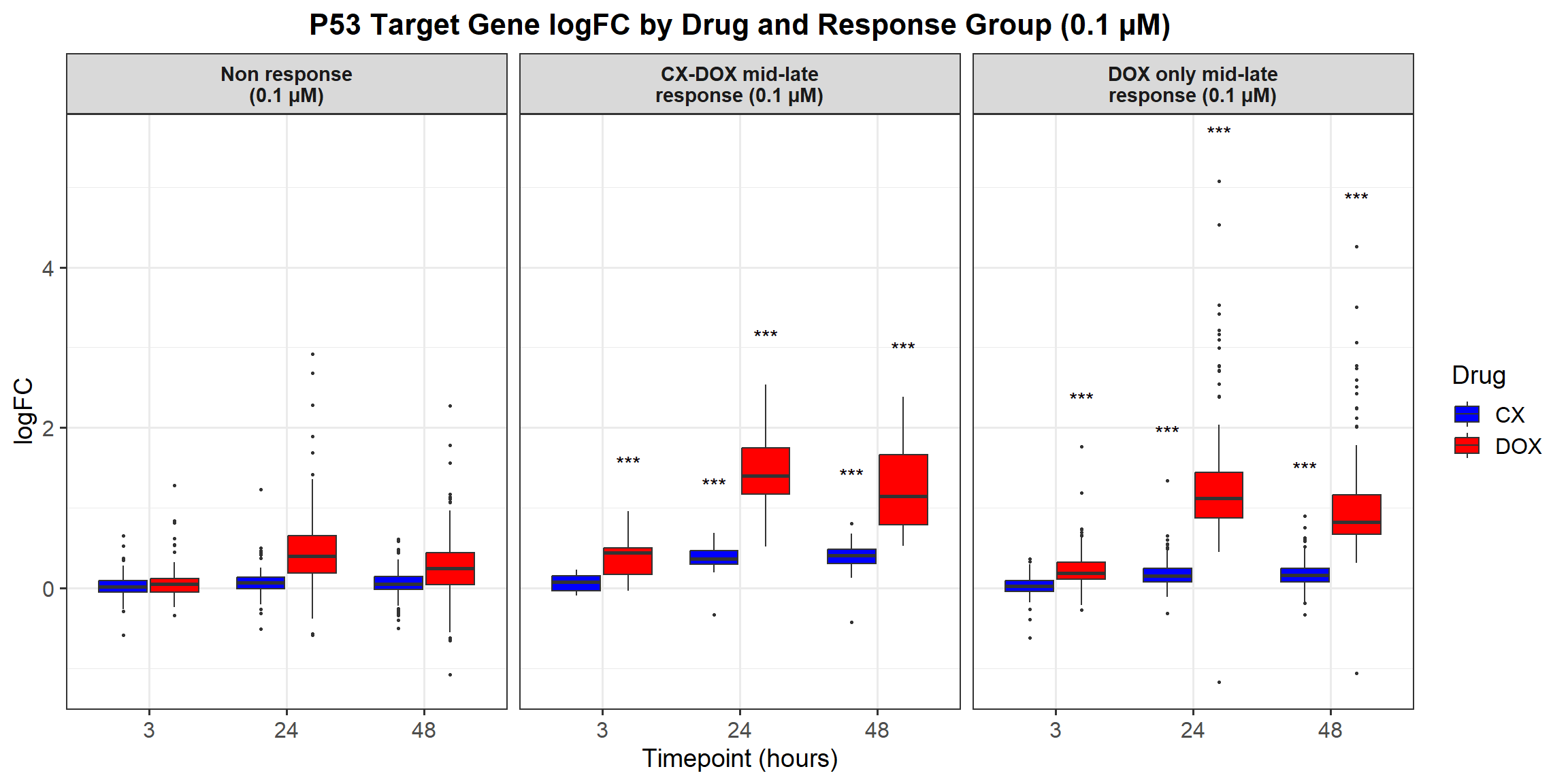
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### P53 Target Genes — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- P53 Target Entrez IDs -----------------
p53_ids <- c(
1026, 50484, 4193, 9766, 9518, 7832, 1643, 1647, 1263, 57103, 51065, 8795, 51499, 64393, 581, 5228, 5429, 8493, 55959,
7508, 64782, 282991, 355, 53836, 4814, 10769, 9050, 27244, 9540, 94241, 26154, 57763, 900, 26999, 55332, 26263, 23479,
23612, 29950, 9618, 10346, 8824, 134147, 55294, 22824, 4254, 6560, 467, 27113, 60492, 8444, 60401, 1969, 220965, 2232,
3976, 55191, 84284, 93129, 5564, 7803, 83667, 7779, 132671, 7039, 51768, 137695, 93134, 7633, 10973, 340485, 307,
27350, 23245, 3732, 29965, 1363, 1435, 196513, 8507, 8061, 2517, 51278, 53354, 54858, 23228, 5366, 5912, 6236, 51222,
26152, 59, 1907, 50650, 91012, 780, 9249, 11072, 144455, 64787, 116151, 27165, 2876, 57822, 55733, 57722, 121457,
375449, 85377, 4851, 5875, 127544, 29901, 84958, 8797, 8793, 441631, 220001, 54541, 5889, 5054, 25816, 25987, 5111,
98, 317, 598, 604, 10904, 1294, 80315, 53944, 1606, 2770, 3628, 3675, 3985, 4035, 4163, 84552, 29085, 55367, 5371,
5791, 54884, 5980, 8794, 1462, 50808, 220, 583, 694, 1056, 9076, 10978, 54677, 1612, 55040, 114907, 2274, 127707,
4000, 8079, 4646, 4747, 27445, 5143, 80055, 79156, 5360, 5364, 23654, 5565, 5613, 5625, 10076, 56963, 6004, 390,
255488, 6326, 6330, 23513, 7869, 283130, 204962, 83959, 6548, 6774, 9263, 10228, 22954, 10475, 85363, 494514, 10142,
79714, 1006, 8446, 9648, 79828, 5507, 55240, 63874, 25841, 9289, 84883, 154810, 51321, 421, 8553, 655, 119032, 84280,
10950, 824, 839, 57828, 857, 8812, 8837, 94027, 113189, 22837, 132864, 10898, 3300, 81704, 1847, 1849, 1947, 9538,
24139, 5168, 147965, 115548, 9873, 23768, 2632, 2817, 3280, 3265, 23308, 3490, 51477, 182, 3856, 8844, 144811, 9404,
4043, 9848, 2872, 23041, 740, 343263, 4638, 26509, 4792, 22861, 57523, 55214, 80025, 164091, 57060, 64065, 51090,
5453, 8496, 333926, 55671, 5900, 55544, 23179, 8601, 389, 6223, 55800, 6385, 4088, 6643, 122809, 257397, 285343,
7011, 54790, 374618, 55362, 51754, 7157, 9537, 22906, 7205, 80705, 219699, 55245, 83719, 7748, 25946, 118738
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% p53_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM P53) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "P53 Target Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)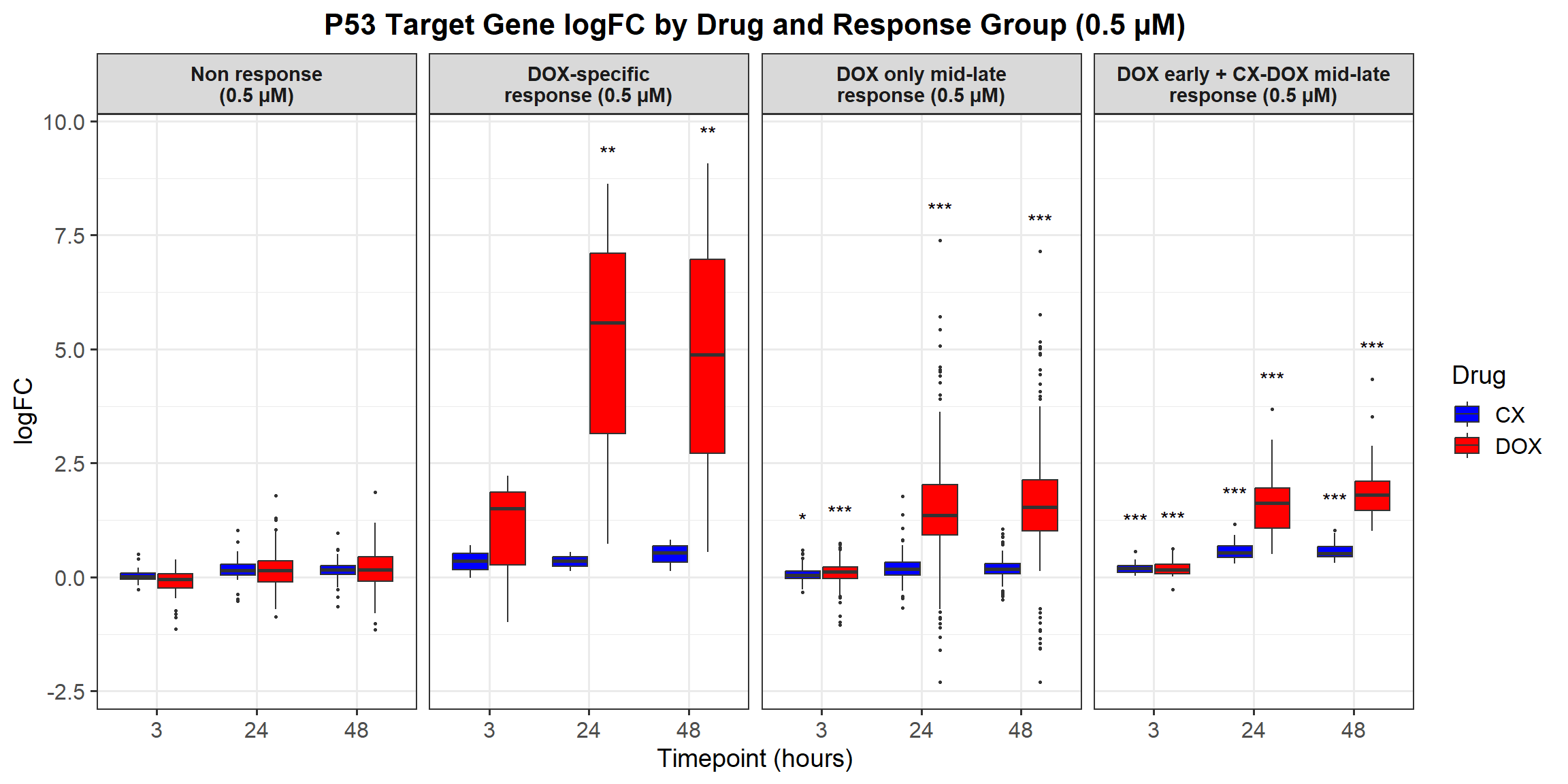
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 TOP2B target genes proportions across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(readr)
# ----------------- Load TOP2B Entrez IDs -----------------
top2b_entrez_ids <- read_csv("data/TOP2B_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% top2b_entrez_ids, "TOP2B Target Genes", "Non-TOP2B Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% top2b_entrez_ids, "TOP2B Target Genes", "Non-TOP2B Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order (TOP2B first) -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("TOP2B Target Genes", "Non-TOP2B Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("TOP2B Target Genes", "Non-TOP2B Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["TOP2B Target Genes"], ref_counts["Non-TOP2B Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"TOP2B Target Genes" = "#E41A1C",
"Non-TOP2B Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "TOP2B Target Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)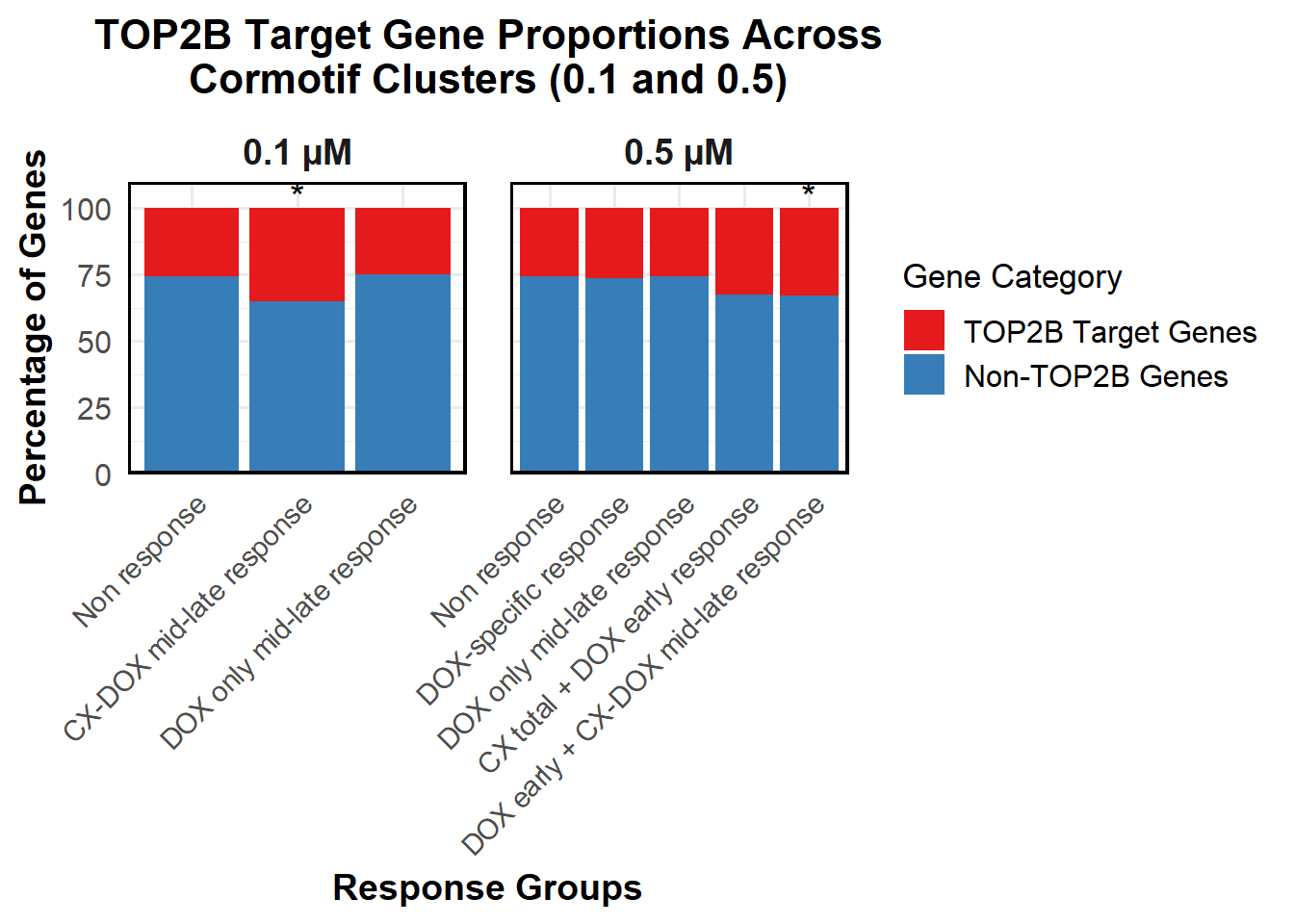
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2B target genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- TOP2B Entrez IDs -----------------
top2b_entrez_ids <- read_csv("data/TOP2B_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2b_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2b_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif TOP2B Genes -----------------
top2b_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
top2b_logfc$Response_Group <- factor(top2b_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
star_df <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- top2b_logfc$logFC[top2b_logfc$Group == resp_group]
control_vals <- top2b_logfc$logFC[top2b_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
if (pval < 0.05) {
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
TRUE ~ "*"
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(Group = resp_group, y_pos = y_pos, label = label, P_Value = signif(pval, 4)))
}
}
return(NULL)
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- star_df %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(top2b_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of TOP2B Target Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)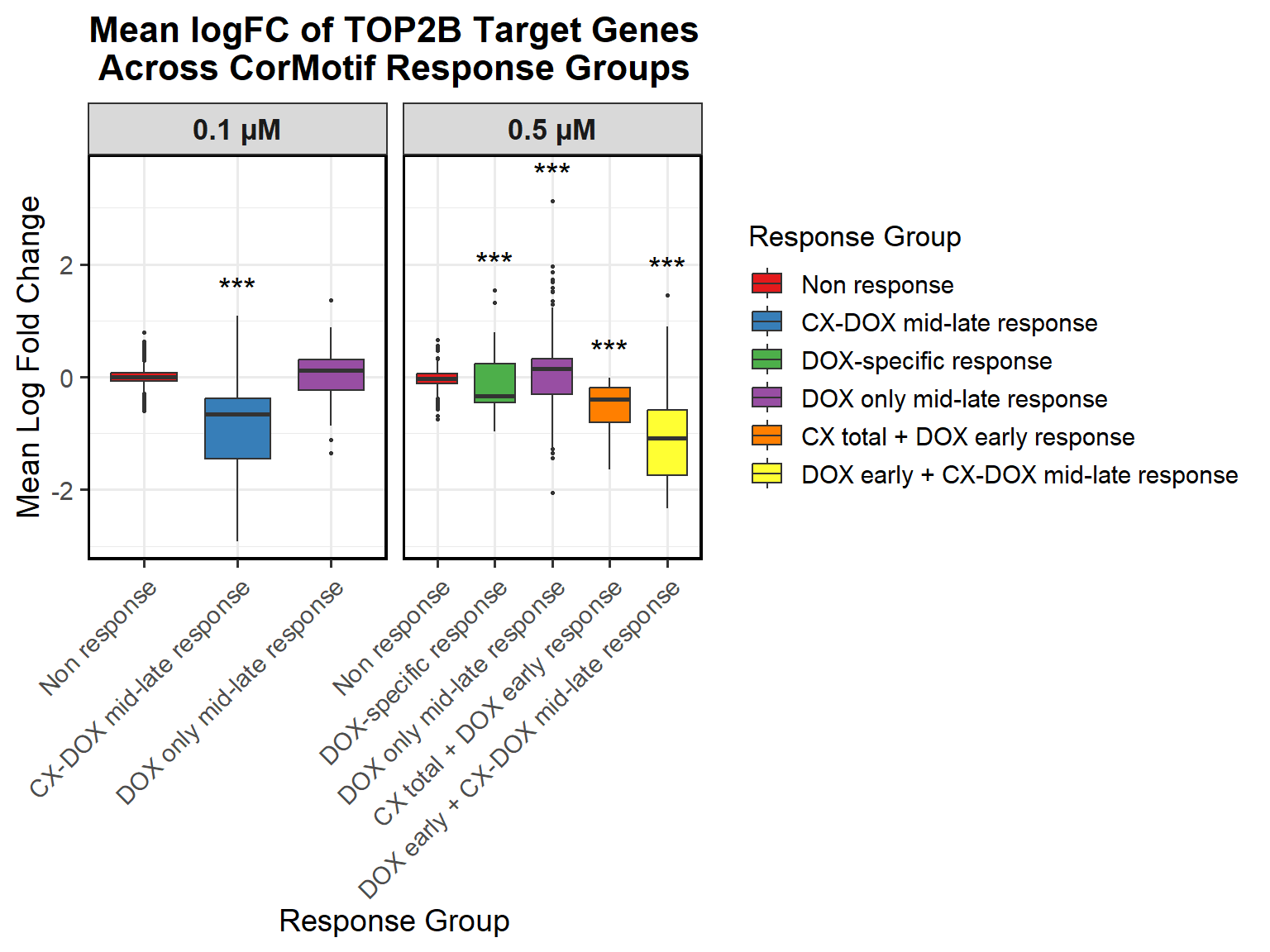
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2B target genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- TOP2B Entrez IDs -----------------
top2b_entrez_ids <- read_csv("data/TOP2B_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2b_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2b_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with TOP2B Targets and Annotate -----------------
top2b_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% top2b_entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(top2b_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(top2b_all$Concentration)) {
for (tp in levels(top2b_all$Timepoint)) {
sub <- top2b_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(top2b_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(top2b_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "TOP2B Target Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)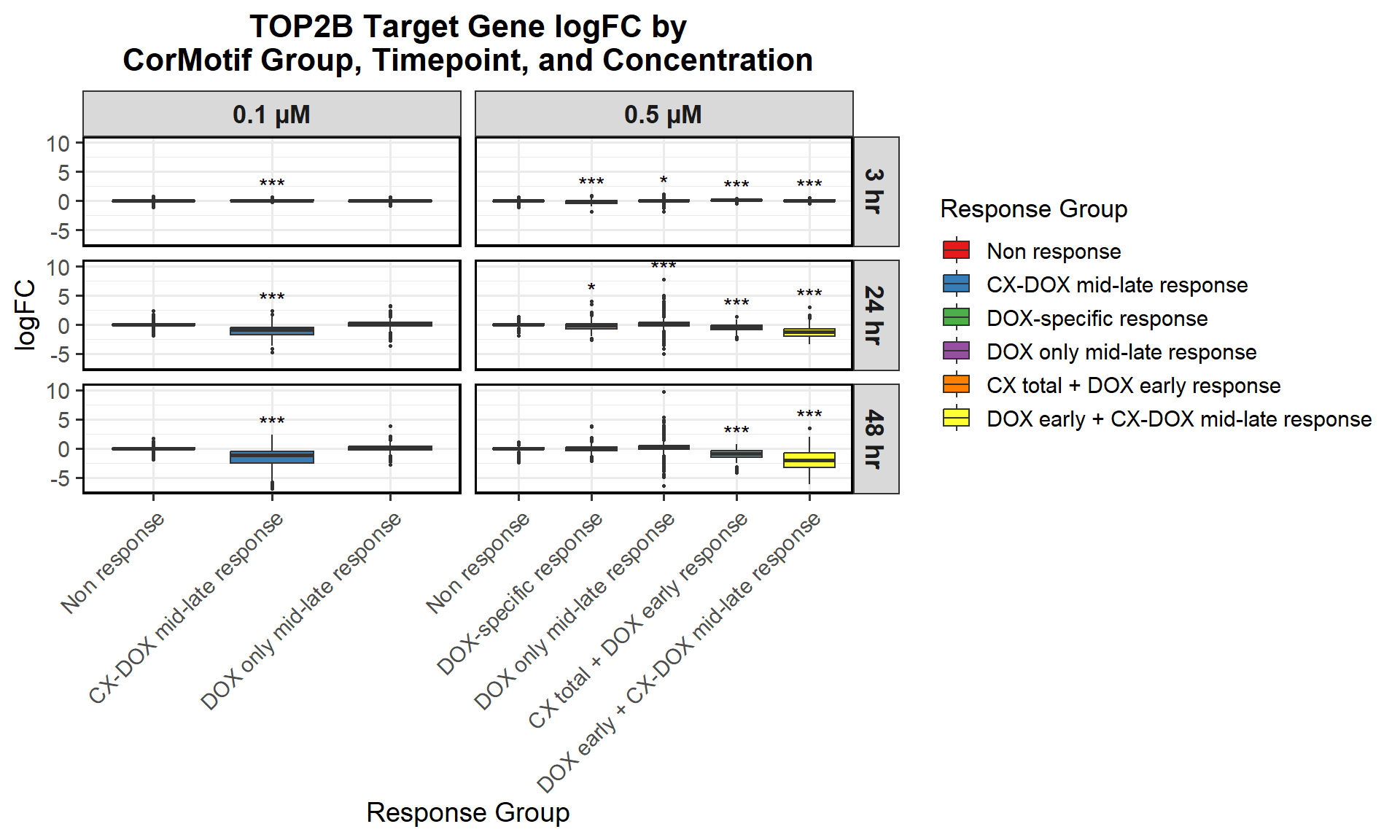
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2B target genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
################### TOP2B Target Genes — 0.1 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2B Target Entrez IDs -----------------
top2b_entrez_ids <- read_csv("data/TOP2B_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2b_entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM TOP2B) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2B Target Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)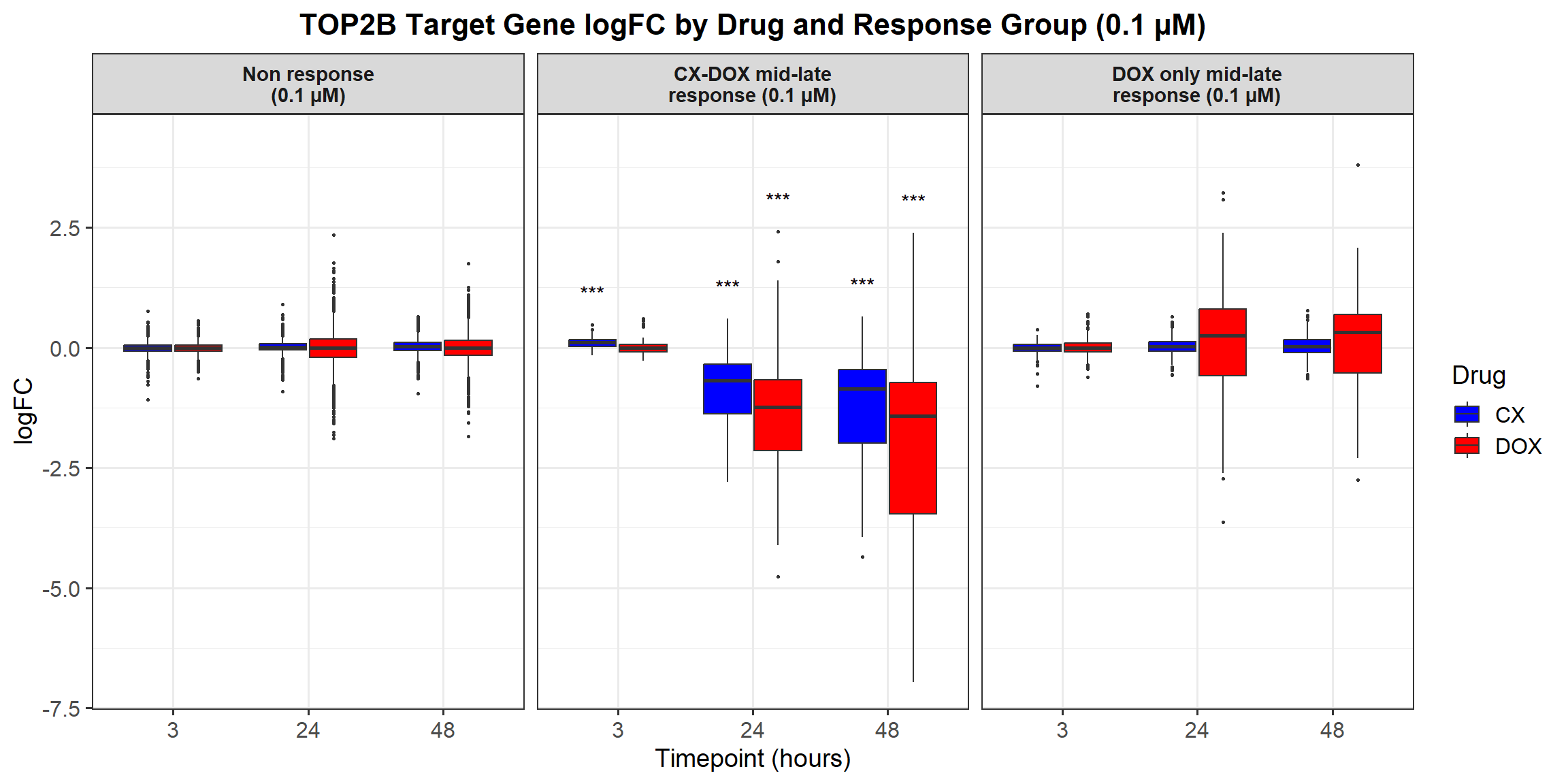
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### TOP2B Target Genes — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2B Target Entrez IDs -----------------
top2b_entrez_ids <- read_csv("data/TOP2B_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2b_entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM TOP2B) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2B Target Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)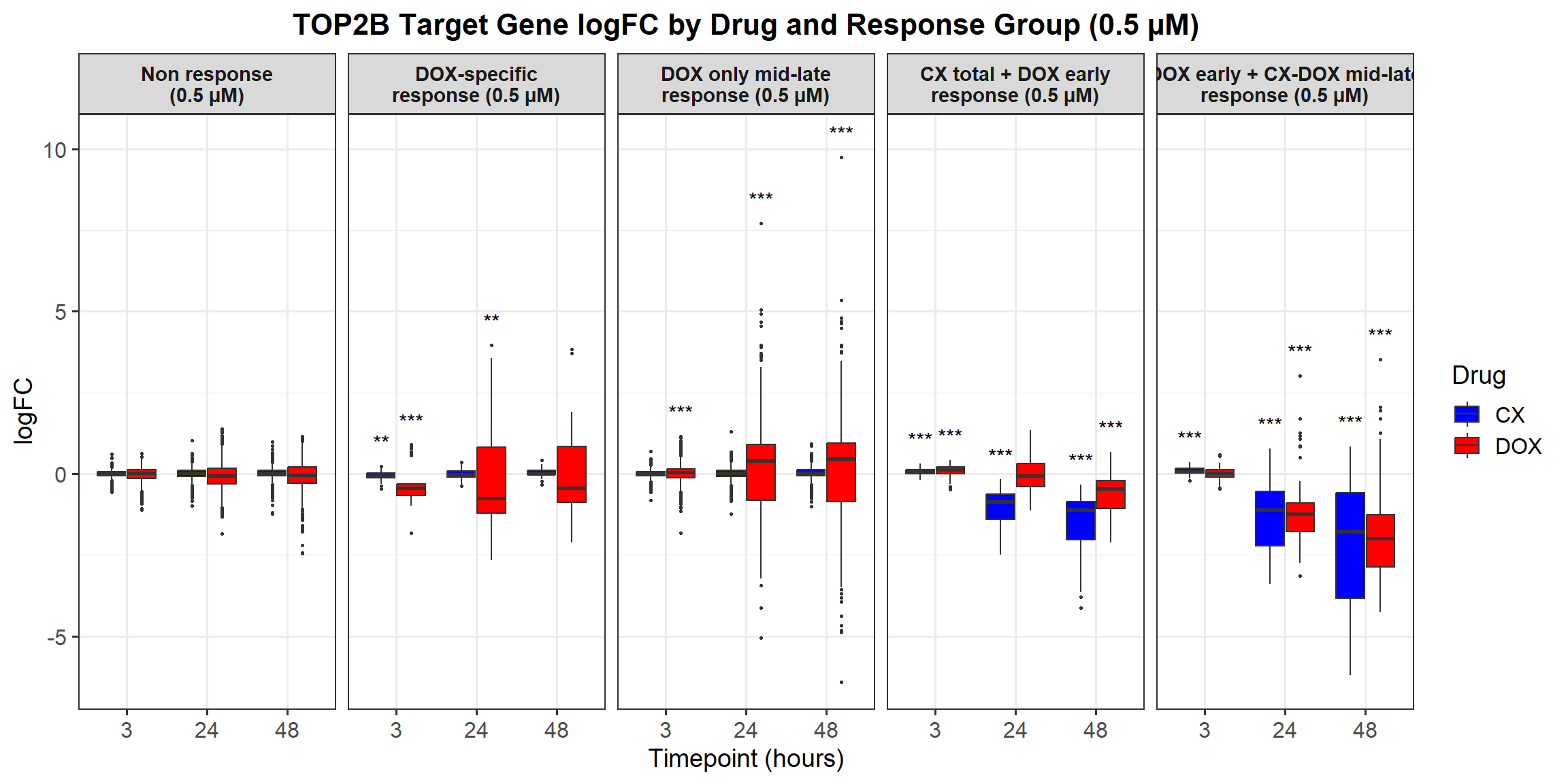
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 TOP2A target genes (ChIP_Atlas) proportion across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(readr)
# ----------------- Load TOP2A Entrez IDs -----------------
top2a_entrez_ids <- read_csv("data/TOP2A_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% top2a_entrez_ids, "TOP2A Target Genes", "Non-TOP2A Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% top2a_entrez_ids, "TOP2A Target Genes", "Non-TOP2A Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("TOP2A Target Genes", "Non-TOP2A Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("TOP2A Target Genes", "Non-TOP2A Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["TOP2A Target Genes"], ref_counts["Non-TOP2A Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 4: `Response_Group = "DOX-specific response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"TOP2A Target Genes" = "#E41A1C",
"Non-TOP2A Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "TOP2A Target Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)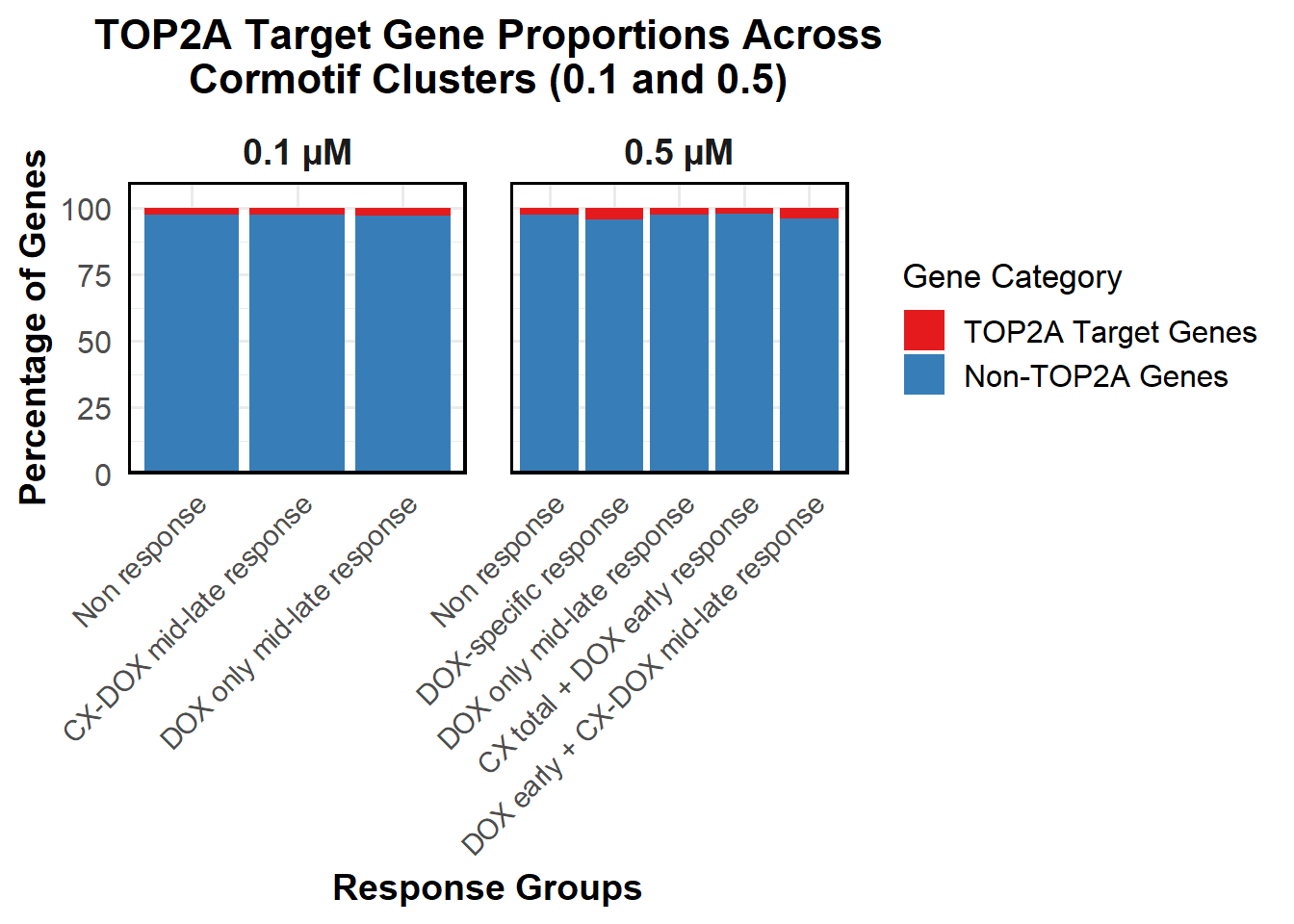
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (ChIP_Atlas) across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A Entrez IDs -----------------
top2a_entrez_ids <- read_csv("data/TOP2A_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2a_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2a_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif TOP2A Genes -----------------
top2a_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Response Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
top2a_logfc$Response_Group <- factor(top2a_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test with Output -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- top2a_logfc$logFC[top2a_logfc$Group == resp_group]
control_vals <- top2a_logfc$logFC[top2a_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
stat <- test_result$statistic
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(
Response_Group = resp_group,
Control_Group = control_group,
W_statistic = as.numeric(stat),
P_value = signif(pval, 4),
Significance = label,
y_pos = y_pos
))
} else {
return(data.frame(
Response_Group = resp_group,
Control_Group = control_group,
W_statistic = NA,
P_value = NA,
Significance = "",
y_pos = NA
))
}
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- wilcoxon_results %>%
separate(Response_Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(top2a_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of TOP2A Target Genes\nAcross CorMotif Response Groups (ChIP atlas)",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)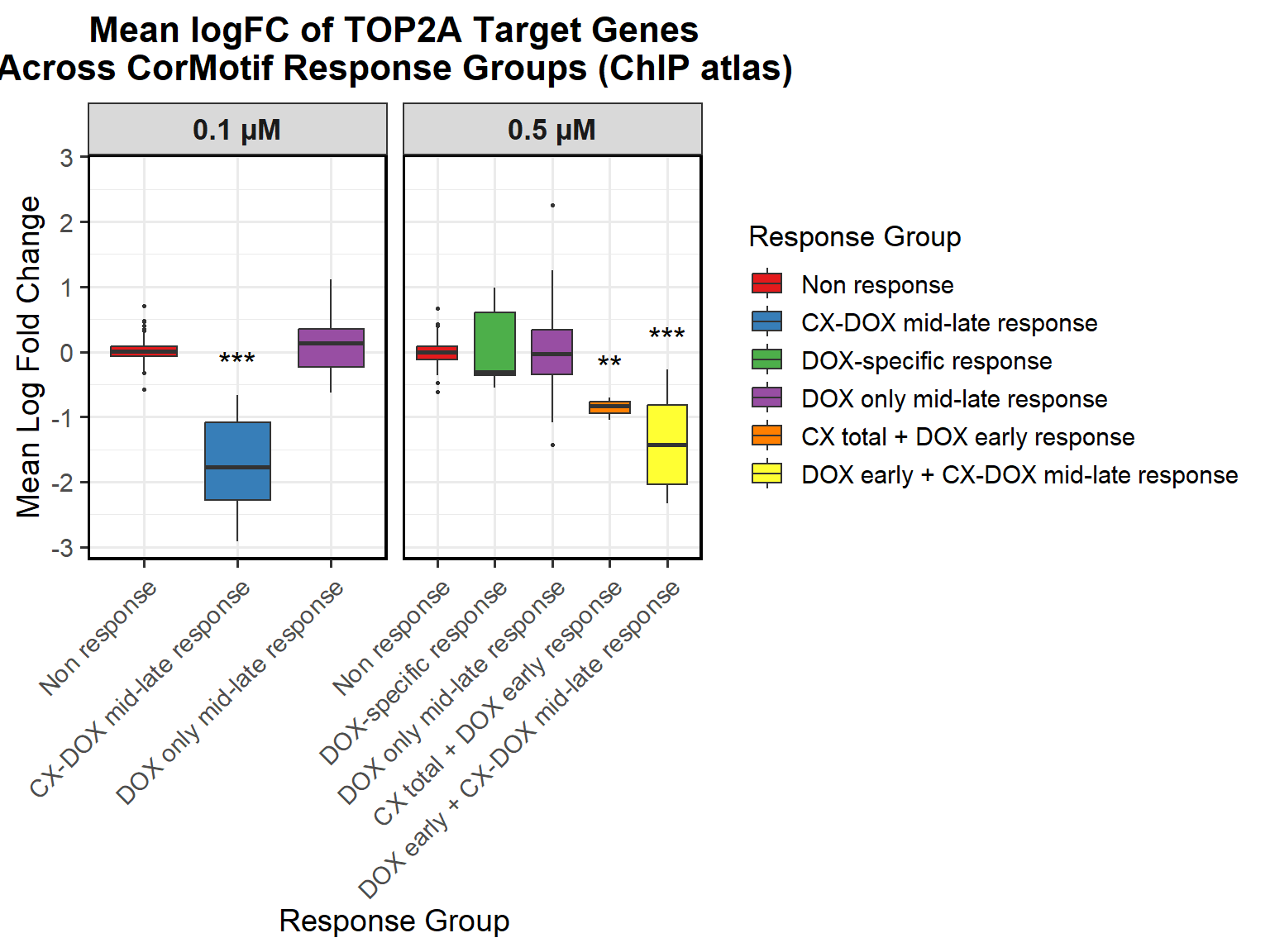
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (ChIP_Atlas) across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A Entrez IDs -----------------
top2a_entrez_ids <- read_csv("data/TOP2A_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2a_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2a_entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with TOP2A Targets and Annotate -----------------
top2a_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% top2a_entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(top2a_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(top2a_all$Concentration)) {
for (tp in levels(top2a_all$Timepoint)) {
sub <- top2a_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(top2a_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(top2a_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "TOP2A Target Gene logFC by\nCorMotif Group, Timepoint, and Concentration (ChIP Atlas)",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)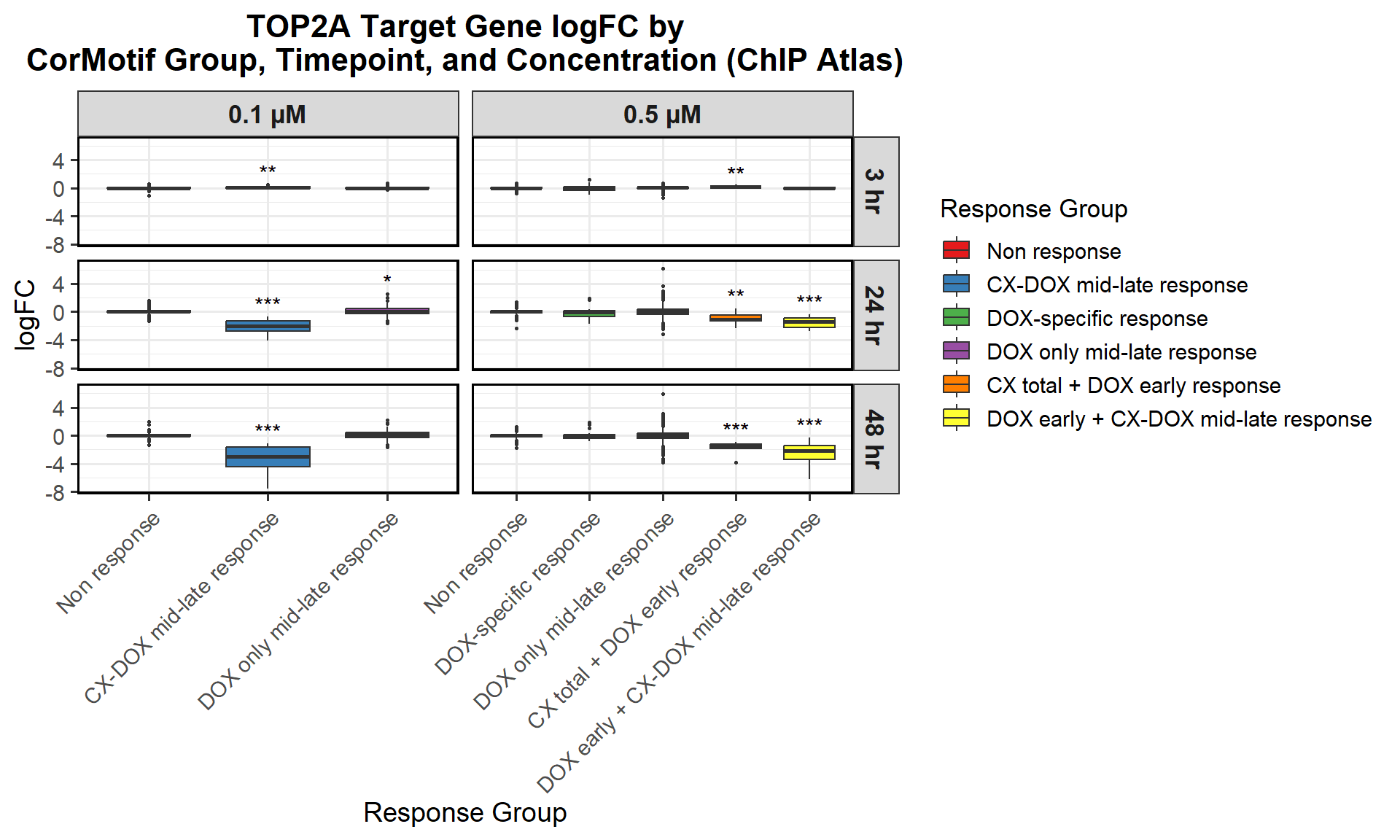
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (ChIP_Atlas) across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A ChIP-Atlas Entrez IDs -----------------
top2a_entrez_ids <- read_csv("data/TOP2A_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2a_entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM TOP2A) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2A Target Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)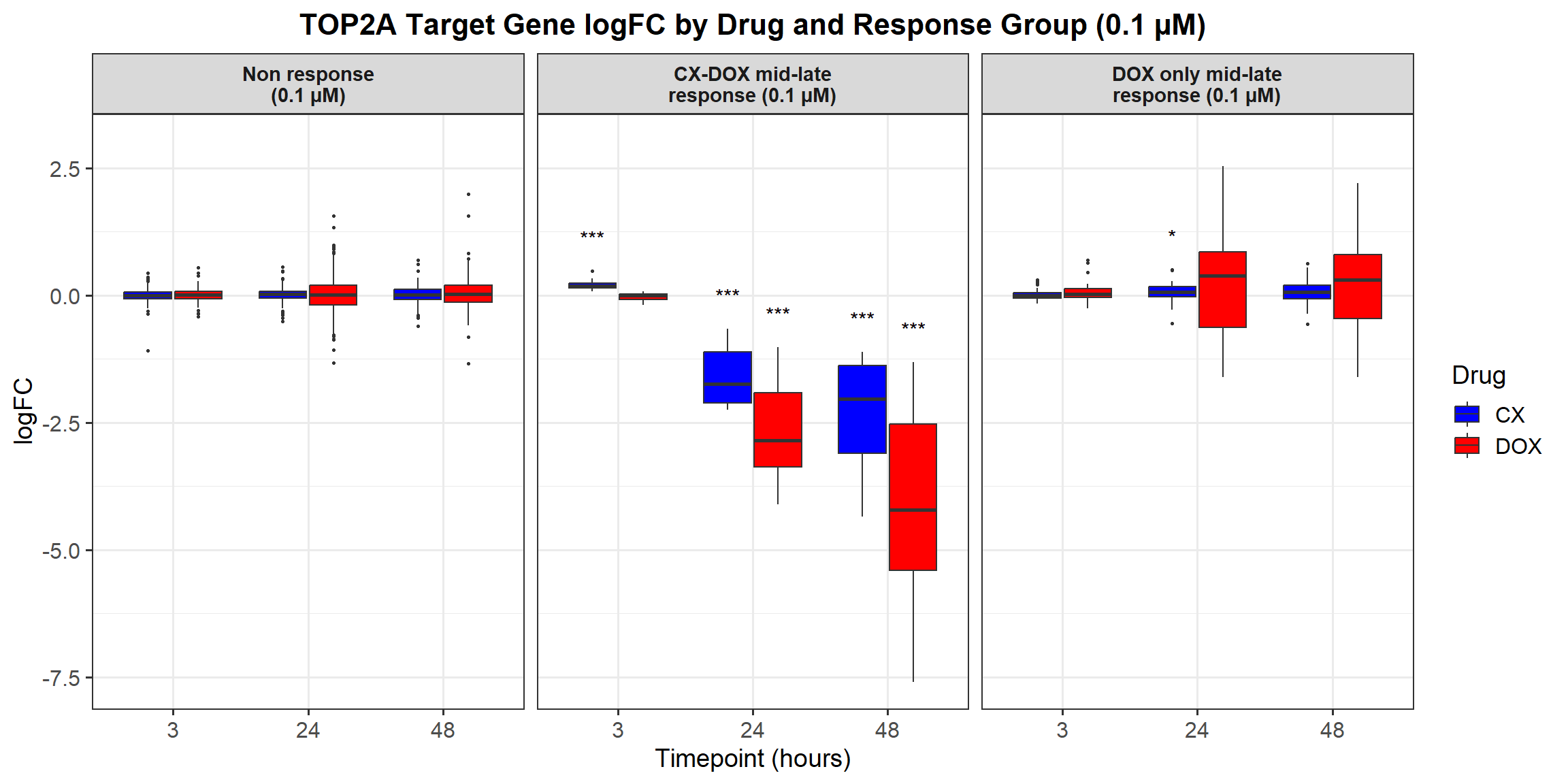
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### TOP2A Target Genes (ChIP-Atlas) — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A Entrez IDs -----------------
top2a_entrez_ids <- read_csv("data/TOP2A_target_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2a_entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM TOP2A ChIP-Atlas) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2A (ChIP-Atlas) Target Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)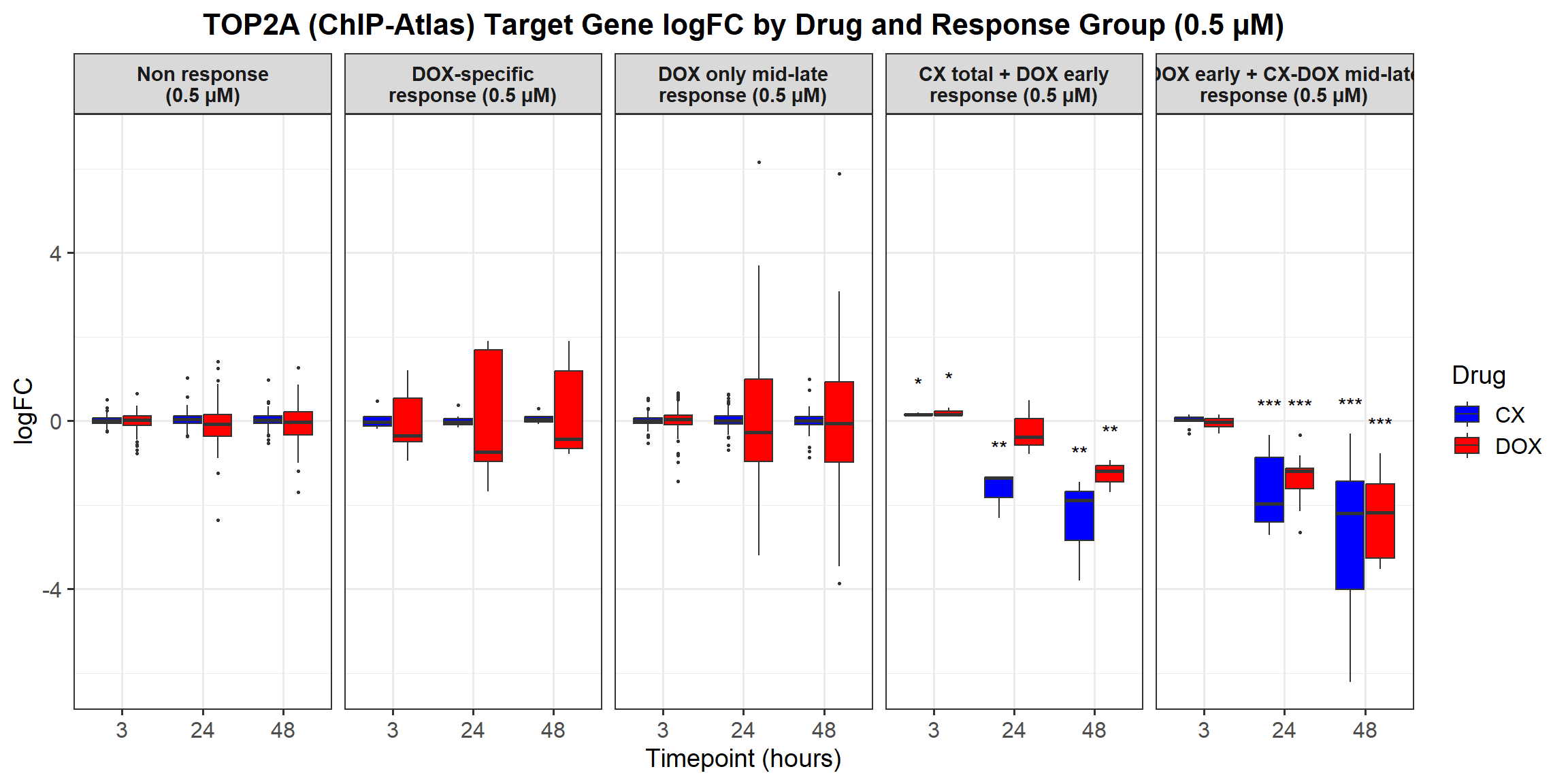
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of TOP2A target genes (RPE-1) across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(readr)
# ----------------- Load TOP2A (RPE-1) Entrez IDs -----------------
top2a_lit_ids <- read_csv("data/TOP2A_target_lit_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% top2a_lit_ids, "TOP2A (RPE-1) Targets", "Non-TOP2A Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% top2a_lit_ids, "TOP2A (RPE-1) Targets", "Non-TOP2A Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("TOP2A (RPE-1) Targets", "Non-TOP2A Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("TOP2A (RPE-1) Targets", "Non-TOP2A Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["TOP2A (RPE-1) Targets"], ref_counts["Non-TOP2A Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"TOP2A (RPE-1) Targets" = "#E41A1C",
"Non-TOP2A Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "TOP2A (RPE-1) Target Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)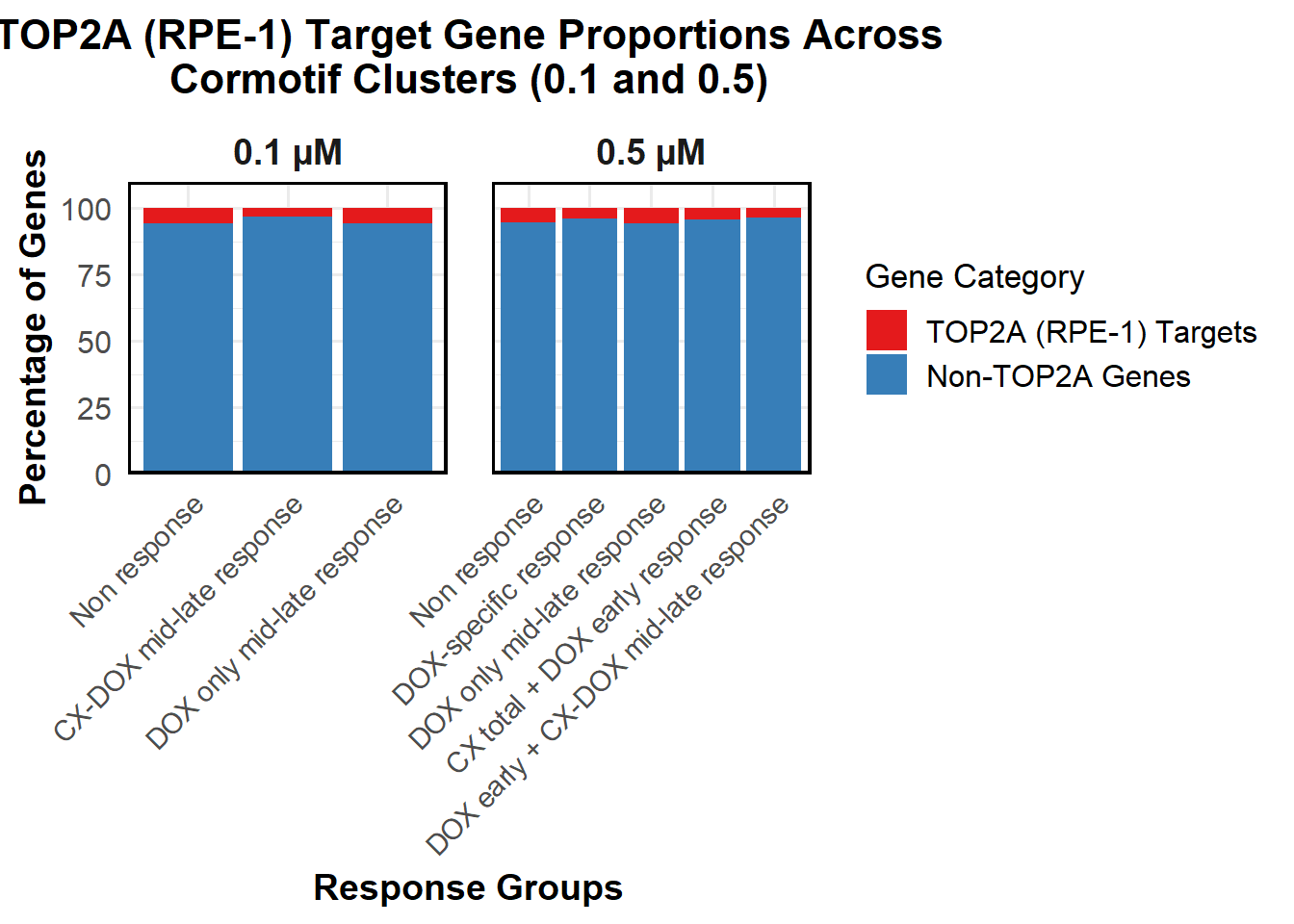
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (RPE-1) across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A (RPE-1) Entrez IDs -----------------
top2a_lit_ids <- read_csv("data/TOP2A_target_lit_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2a_lit_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2a_lit_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif Genes -----------------
top2a_lit_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Response Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
top2a_lit_logfc$Response_Group <- factor(top2a_lit_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test with Output -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- top2a_lit_logfc$logFC[top2a_lit_logfc$Group == resp_group]
control_vals <- top2a_lit_logfc$logFC[top2a_lit_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
stat <- test_result$statistic
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(
Response_Group = resp_group,
Control_Group = control_group,
W_statistic = as.numeric(stat),
P_value = signif(pval, 4),
Significance = label,
y_pos = y_pos
))
} else {
return(data.frame(
Response_Group = resp_group,
Control_Group = control_group,
W_statistic = NA,
P_value = NA,
Significance = "",
y_pos = NA
))
}
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- wilcoxon_results %>%
separate(Response_Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(top2a_lit_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of Literature-Based TOP2A Targets (RPE-1)\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)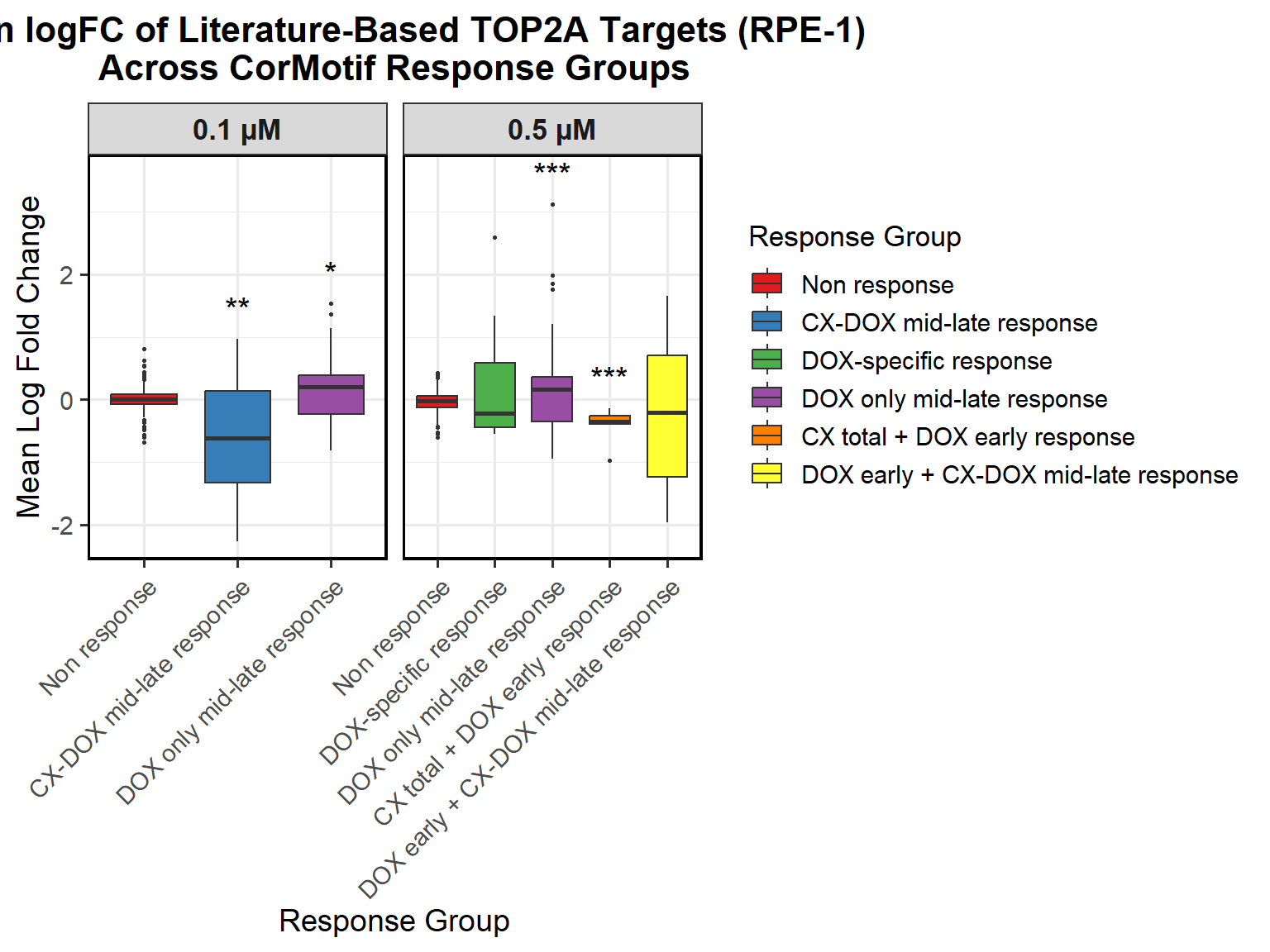
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (RPE-1) across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A (RPE-1) Entrez IDs -----------------
top2a_lit_ids <- read_csv("data/TOP2A_target_lit_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% top2a_lit_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% top2a_lit_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with TOP2A (Lit) Targets and Annotate -----------------
top2a_lit_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% top2a_lit_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(top2a_lit_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(top2a_lit_all$Concentration)) {
for (tp in levels(top2a_lit_all$Timepoint)) {
sub <- top2a_lit_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(top2a_lit_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(top2a_lit_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "TOP2A Target Gene (RPE-1 cell) logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)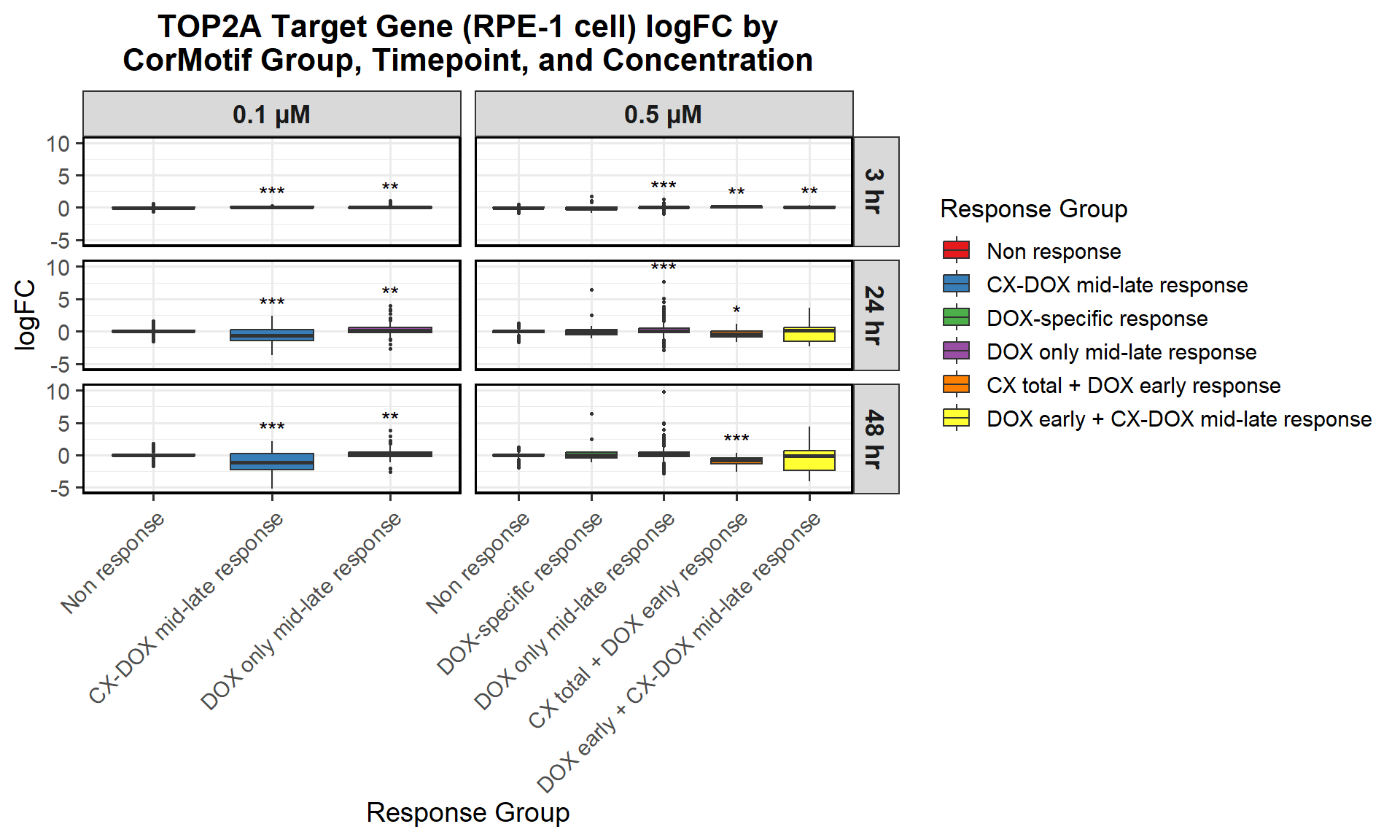
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of TOP2A target genes (RPE-1) across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
################### TOP2A Target Genes (RPE-1 Literature) — 0.1 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A (RPE-1) Entrez IDs -----------------
top2a_lit_ids <- read_csv("data/TOP2A_target_lit_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2a_lit_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM TOP2A RPE-1) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2A (RPE-1) Target Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)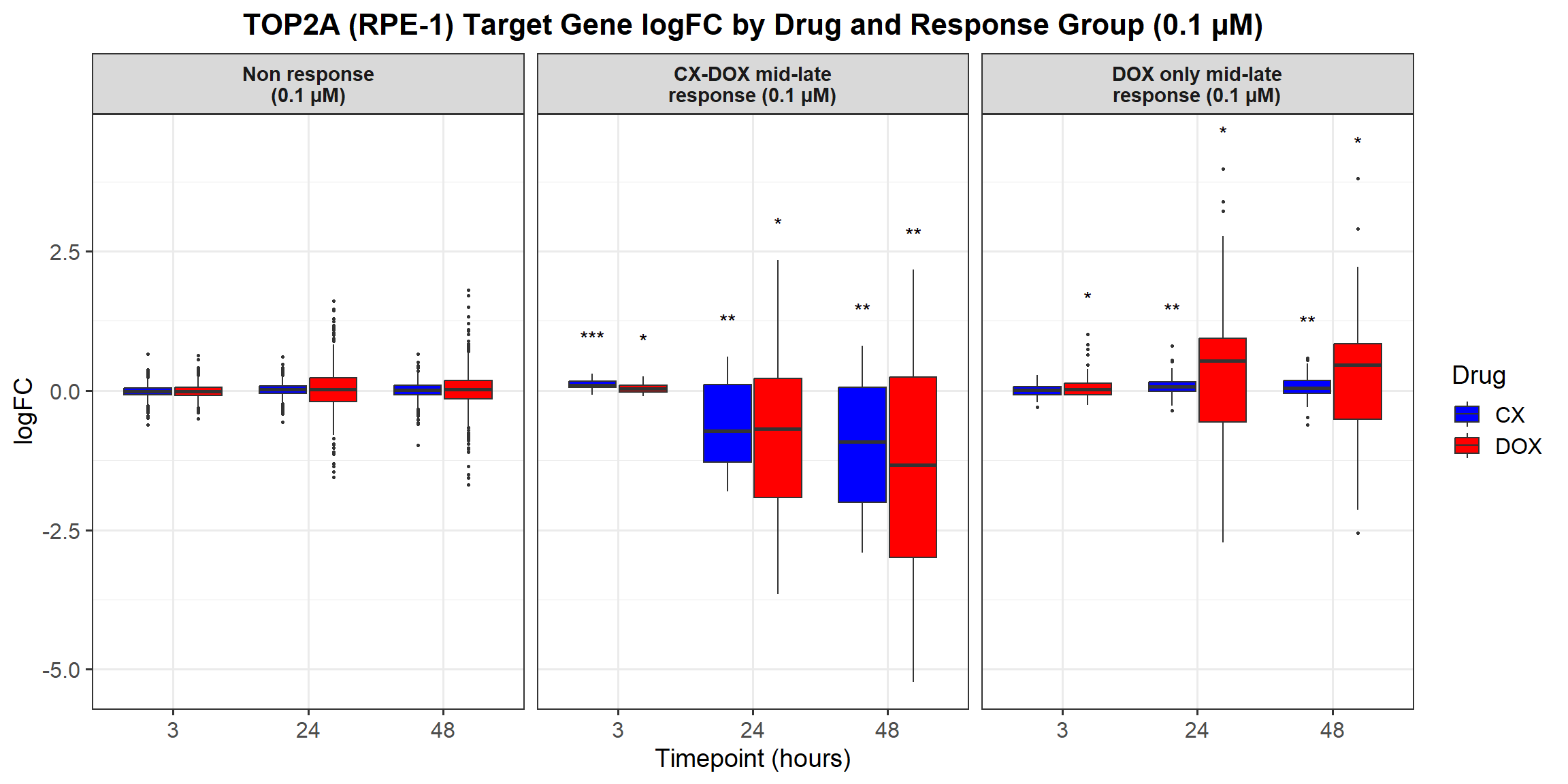
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### TOP2A Target Genes (RPE-1 Literature) — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load TOP2A (RPE-1) Entrez IDs -----------------
top2a_lit_ids <- read_csv("data/TOP2A_target_lit_mapped.csv", show_col_types = FALSE) %>%
pull(Entrez_ID) %>%
unique() %>%
as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% top2a_lit_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM TOP2A RPE-1) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "TOP2A (RPE-1) Target Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)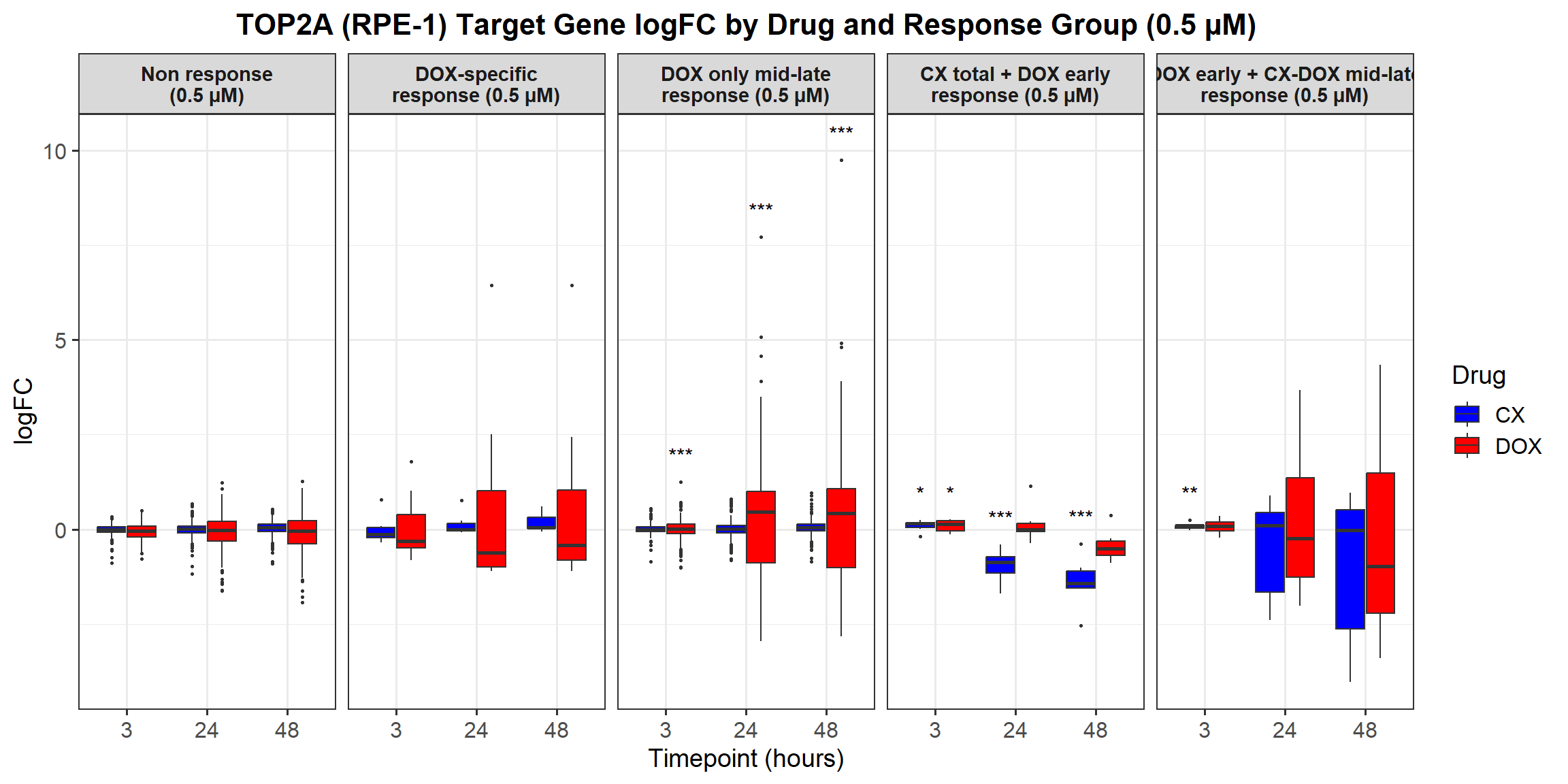
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of Anthracycline Cardiotoxicity genes across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
# ----------------- AC Cardiotoxicity Entrez IDs -----------------
ac_cardio_ids <- c(
6272, 8029, 11128, 79899, 54477, 121665, 5095, 22863, 57161, 4692,
8214, 23151, 56606, 108, 22999, 56895, 9603, 3181, 4023, 10499,
92949, 4363, 10057, 5243, 5244, 5880, 1535, 2950, 847, 5447,
3038, 3077, 4846, 3958, 23327, 29899, 23155, 80856, 55020, 78996,
23262, 150383, 9620, 79730, 344595, 5066, 6251, 3482, 9588, 339416,
7292, 55157, 87769, 23409, 720, 3107, 54535, 1590, 80059, 7991,
57110, 8803, 323, 54826, 5916, 23371, 283337, 64078, 80010, 1933,
10818, 51020
) %>% as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% ac_cardio_ids, "AC-Toxicity Genes", "Non-AC Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% ac_cardio_ids, "AC-Toxicity Genes", "Non-AC Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("AC-Toxicity Genes", "Non-AC Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("AC-Toxicity Genes", "Non-AC Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["AC-Toxicity Genes"], ref_counts["Non-AC Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"AC-Toxicity Genes" = "#E41A1C",
"Non-AC Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "AC Cardiotoxicity Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)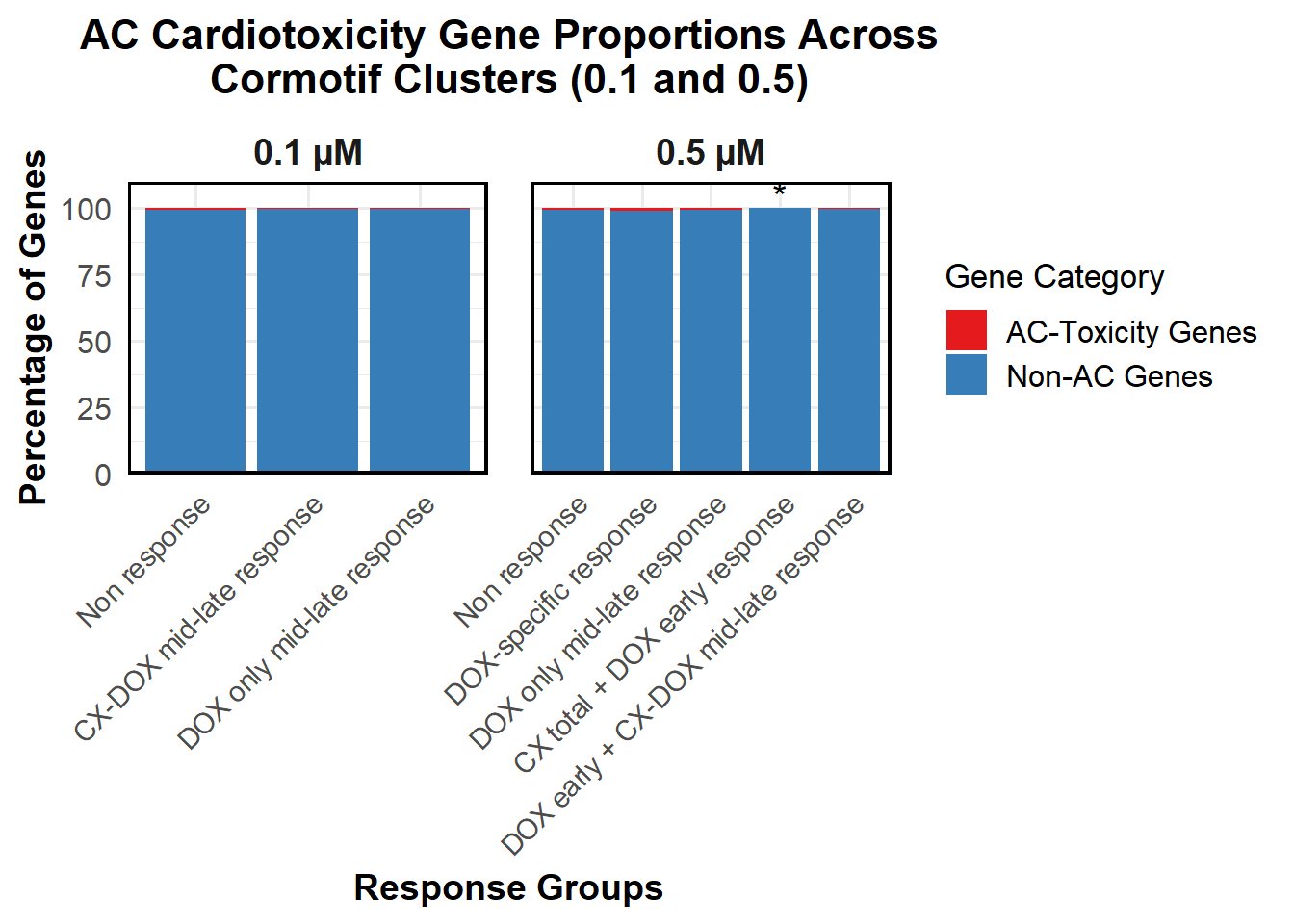
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Anthracycline Cardiotoxicity genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AC Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
6272, 8029, 11128, 79899, 54477, 121665, 5095, 22863, 57161, 4692,
8214, 23151, 56606, 108, 22999, 56895, 9603, 3181, 4023, 10499,
92949, 4363, 10057, 5243, 5244, 5880, 1535, 2950, 847, 5447,
3038, 3077, 4846, 3958, 23327, 29899, 23155, 80856, 55020, 78996,
23262, 150383, 9620, 79730, 344595, 5066, 6251, 3482, 9588, 339416,
7292, 55157, 87769, 23409, 720, 3107, 54535, 1590, 80059, 7991,
57110, 8803, 323, 54826, 5916, 23371, 283337, 64078, 80010, 1933,
10818, 51020
) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif Genes -----------------
ac_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
ac_logfc$Response_Group <- factor(ac_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- ac_logfc$logFC[ac_logfc$Group == resp_group]
control_vals <- ac_logfc$logFC[ac_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
stat <- test_result$statistic
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(
Group = resp_group,
y_pos = y_pos,
label = label,
P_Value = signif(pval, 4)
))
} else {
return(NULL)
}
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- wilcoxon_results %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(ac_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of AC Cardiotoxicity Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)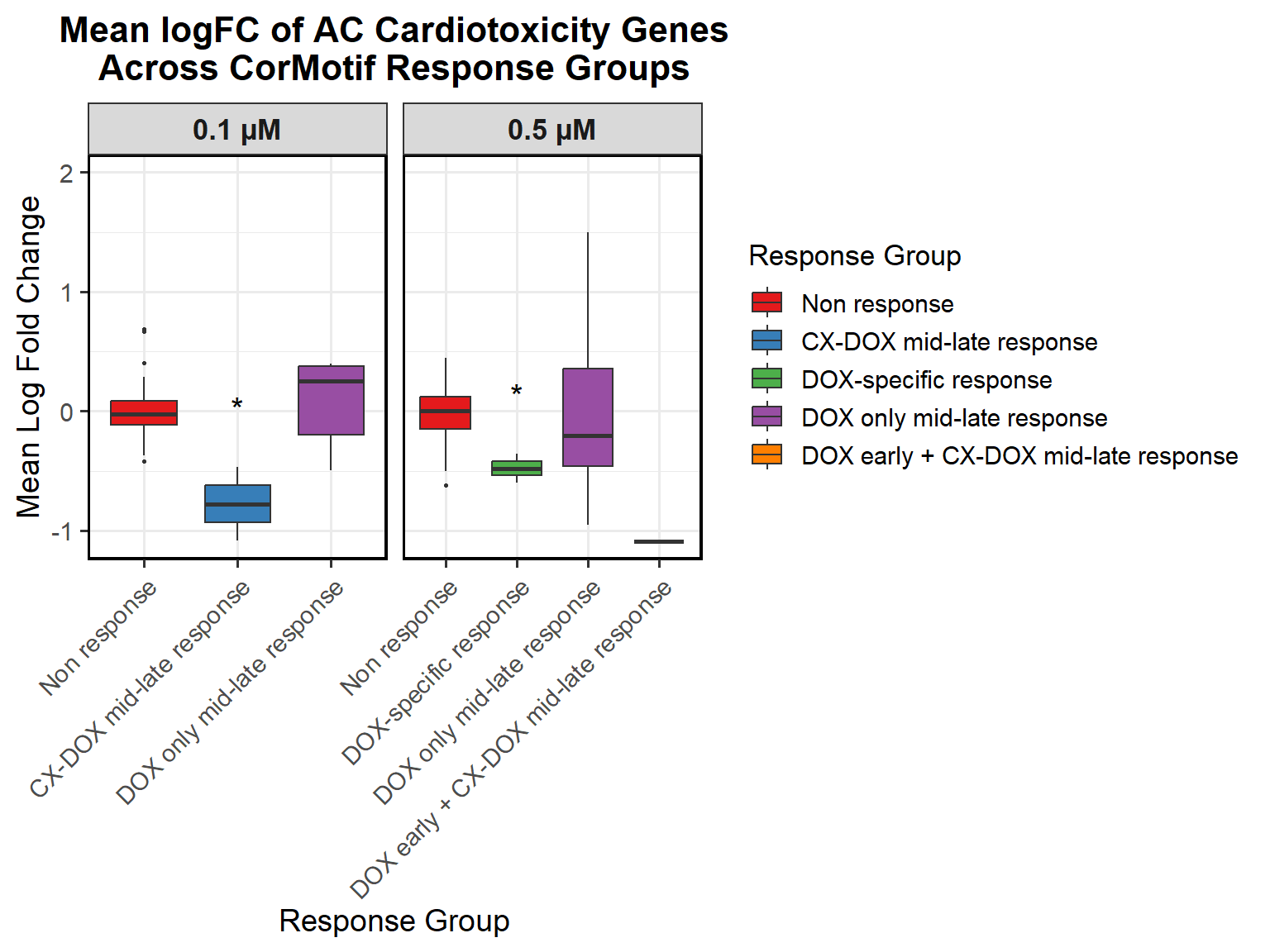
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Anthracycline Cardiotoxicity genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AC Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
6272, 8029, 11128, 79899, 54477, 121665, 5095, 22863, 57161, 4692,
8214, 23151, 56606, 108, 22999, 56895, 9603, 3181, 4023, 10499,
92949, 4363, 10057, 5243, 5244, 5880, 1535, 2950, 847, 5447,
3038, 3077, 4846, 3958, 23327, 29899, 23155, 80856, 55020, 78996,
23262, 150383, 9620, 79730, 344595, 5066, 6251, 3482, 9588, 339416,
7292, 55157, 87769, 23409, 720, 3107, 54535, 1590, 80059, 7991,
57110, 8803, 323, 54826, 5916, 23371, 283337, 64078, 80010, 1933,
10818, 51020
) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with AC Cardiotoxicity Targets -----------------
ac_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(ac_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(ac_all$Concentration)) {
for (tp in levels(ac_all$Timepoint)) {
sub <- ac_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(ac_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(ac_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "AC Cardiotoxicity Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)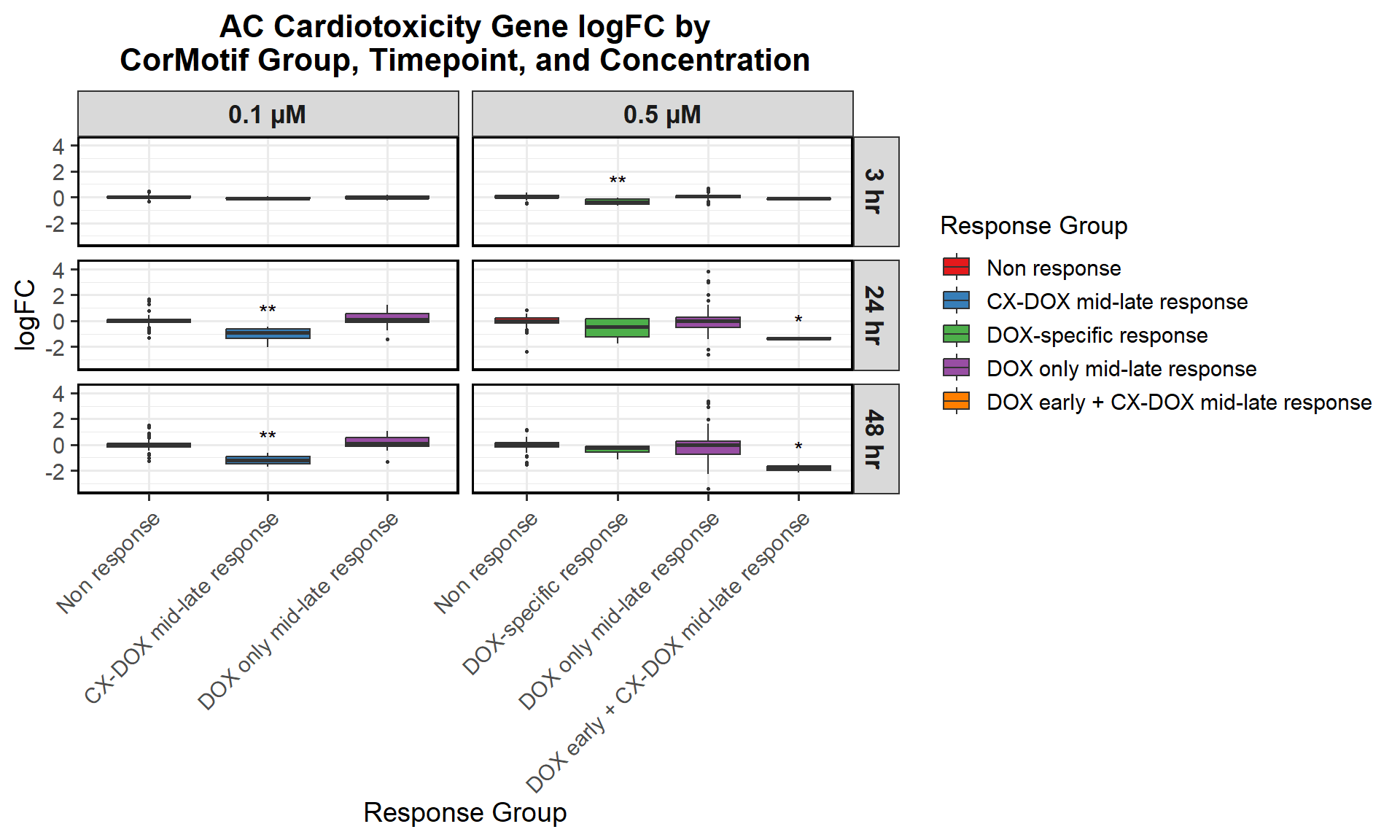
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Anthracycline Cardiotoxicity genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
################### AC Cardiotoxicity Genes — 0.1 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AC Cardiotoxicity Entrez IDs -----------------
ac_ids <- c(
6272, 8029, 11128, 79899, 54477, 121665, 5095, 22863, 57161, 4692,
8214, 23151, 56606, 108, 22999, 56895, 9603, 3181, 4023, 10499,
92949, 4363, 10057, 5243, 5244, 5880, 1535, 2950, 847, 5447,
3038, 3077, 4846, 3958, 23327, 29899, 23155, 80856, 55020, 78996,
23262, 150383, 9620, 79730, 344595, 5066, 6251, 3482, 9588, 339416,
7292, 55157, 87769, 23409, 720, 3107, 54535, 1590, 80059, 7991,
57110, 8803, 323, 54826, 5916, 23371, 283337, 64078, 80010, 1933,
10818, 51020
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% ac_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM AC Cardiotoxicity) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "AC Cardiotoxicity Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)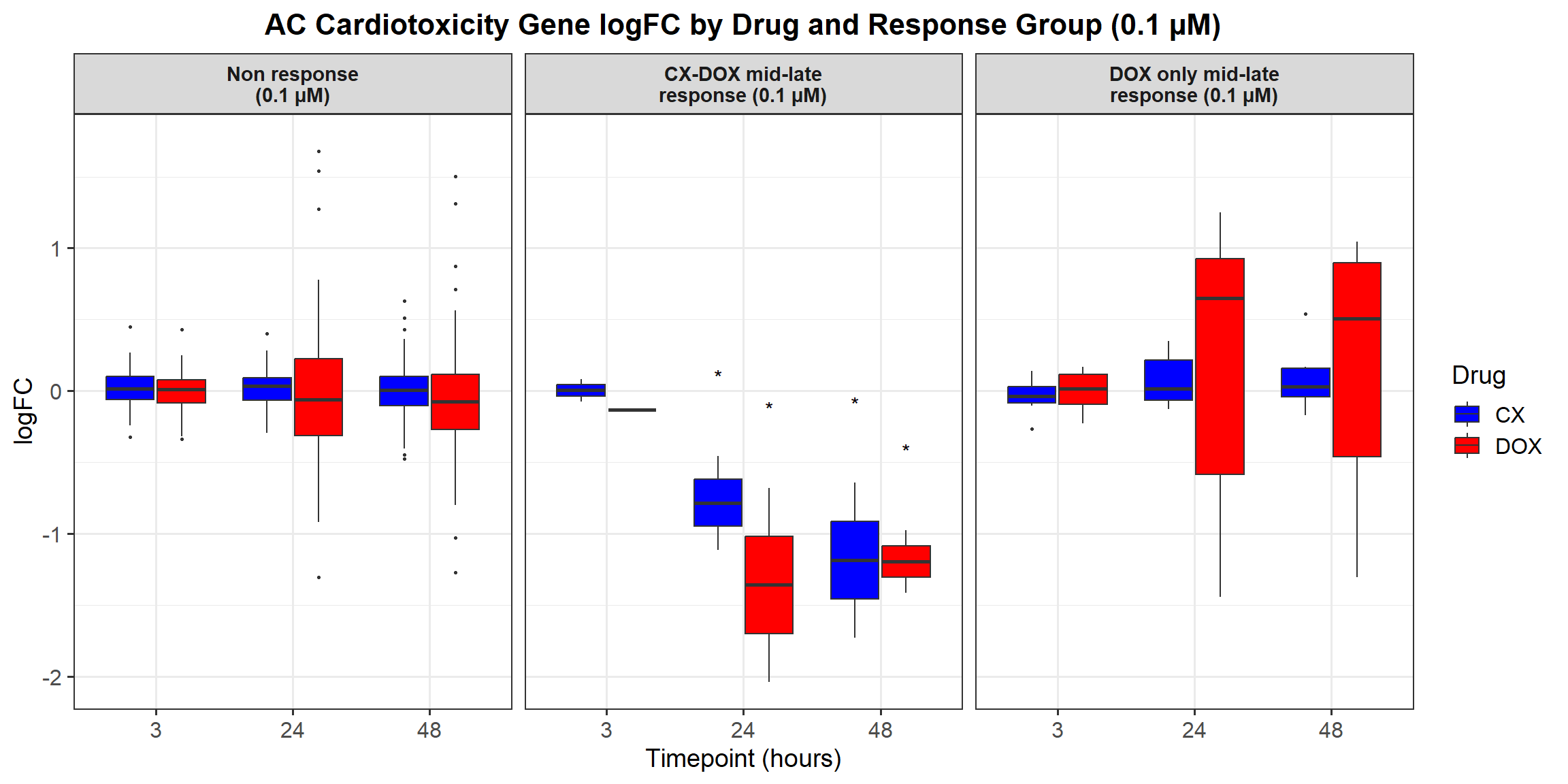
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### AC Genes — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AC Cardiotoxicity Entrez IDs -----------------
ac_ids <- c(
6272, 8029, 11128, 79899, 54477, 121665, 5095, 22863, 57161, 4692,
8214, 23151, 56606, 108, 22999, 56895, 9603, 3181, 4023, 10499,
92949, 4363, 10057, 5243, 5244, 5880, 1535, 2950, 847, 5447,
3038, 3077, 4846, 3958, 23327, 29899, 23155, 80856, 55020, 78996,
23262, 150383, 9620, 79730, 344595, 5066, 6251, 3482, 9588, 339416,
7292, 55157, 87769, 23409, 720, 3107, 54535, 1590, 80059, 7991,
57110, 8803, 323, 54826, 5916, 23371, 283337, 64078, 80010, 1933,
10818, 51020
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% ac_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM AC Genes) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "AC Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)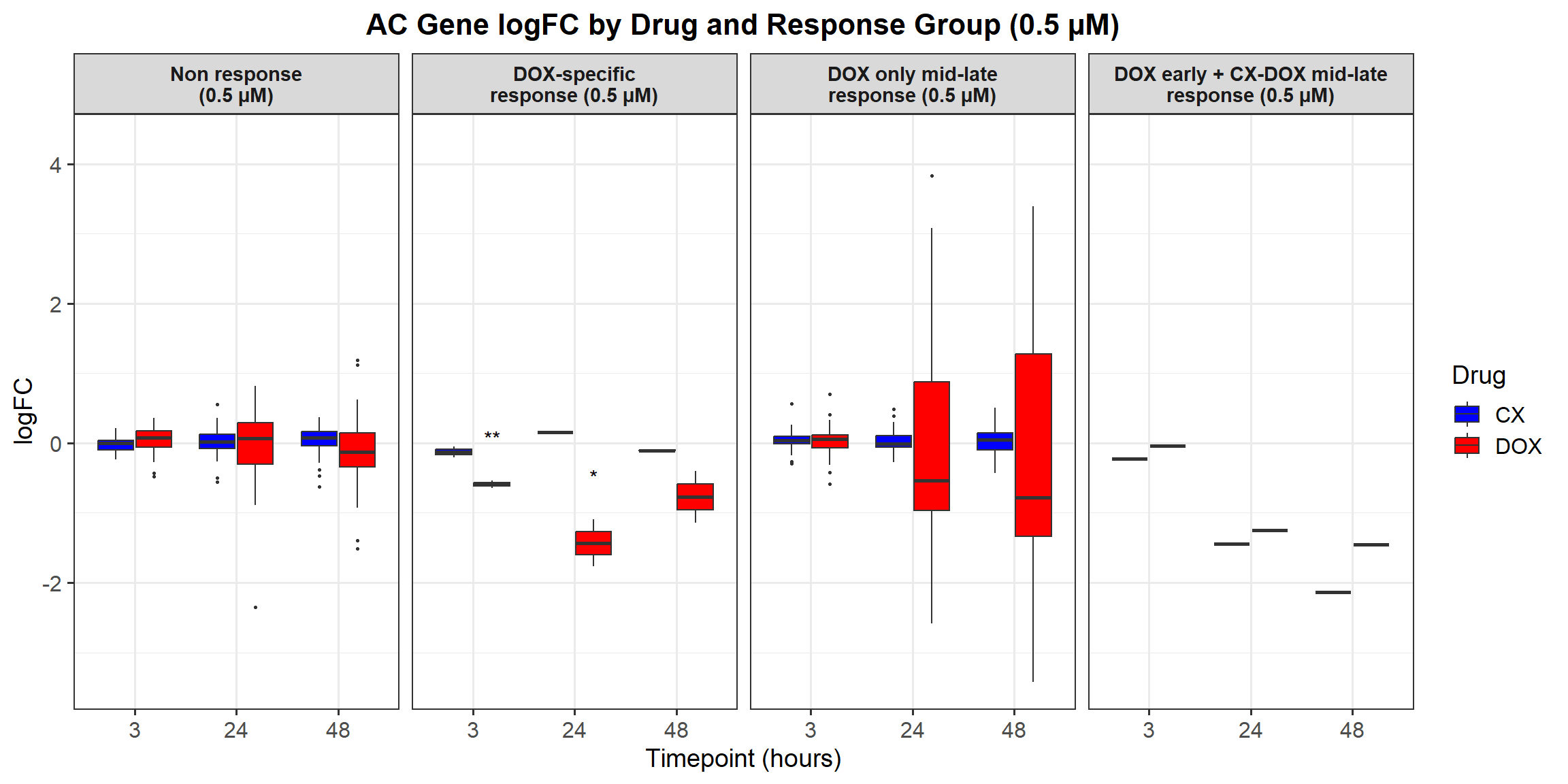
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of DOX Cardiotoxicity genes across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
# ----------------- DOX Cardiotoxicity Entrez IDs -----------------
dox_cardio_ids <- c(
847, 873, 2064, 2878, 2944, 3038, 4846, 51196, 5880, 6687,
7799, 4292, 5916, 3077, 51310, 9154, 64078, 5244, 10057, 10060,
89845, 56853, 4625, 1573, 79890
) %>% as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% dox_cardio_ids, "DOX-Toxicity Genes", "Non-DOX Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% dox_cardio_ids, "DOX-Toxicity Genes", "Non-DOX Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Set Category Order -----------------
df_combined$Category <- factor(df_combined$Category, levels = c("DOX-Toxicity Genes", "Non-DOX Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("DOX-Toxicity Genes", "Non-DOX Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["DOX-Toxicity Genes"], ref_counts["Non-DOX Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run test for each concentration
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 2: `Response_Group = "DOX only mid-late response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
# Merge test results into proportions
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Star Label Position -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"DOX-Toxicity Genes" = "#E41A1C",
"Non-DOX Genes" = "#377EB8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "DOX Cardiotoxicity Gene Proportions Across\nCormotif Clusters (0.1 and 0.5)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)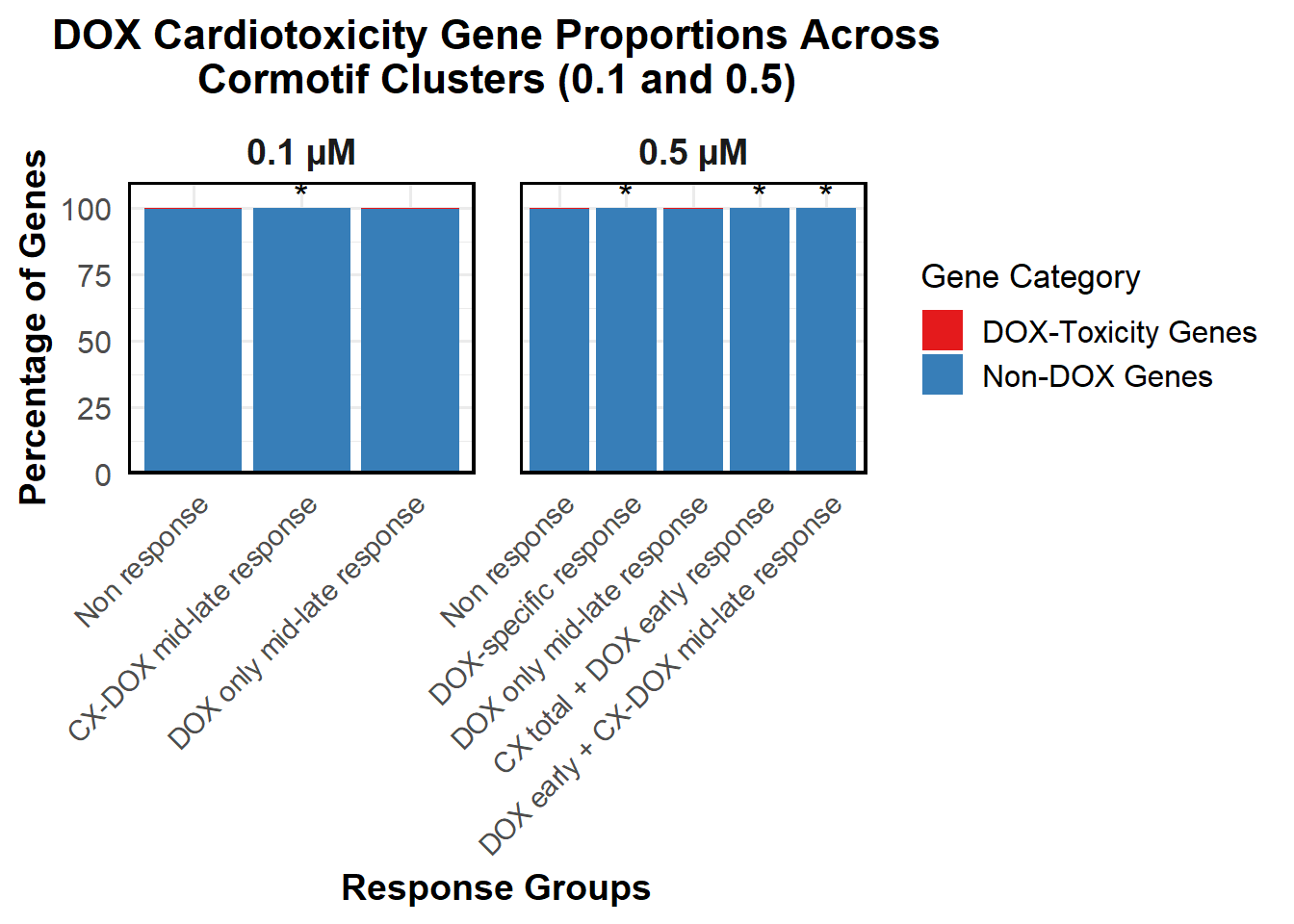
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DOX Cardiotoxicity genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DOX Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
847, 873, 2064, 2878, 2944, 3038, 4846, 51196, 5880, 6687,
7799, 4292, 5916, 3077, 51310, 9154, 64078, 5244, 10057, 10060,
89845, 56853, 4625, 1573, 79890
) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM",
TRUE ~ NA_character_
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with CorMotif Genes -----------------
dox_cardio_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Response Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
dox_cardio_logfc$Response_Group <- factor(dox_cardio_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- dox_cardio_logfc$logFC[dox_cardio_logfc$Group == resp_group]
control_vals <- dox_cardio_logfc$logFC[dox_cardio_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
stat <- test_result$statistic
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(
Group = resp_group,
y_pos = y_pos,
label = label,
P_Value = signif(pval, 4)
))
} else {
return(NULL)
}
}) %>% bind_rows()
# ----------------- Prepare Annotation -----------------
label_data <- wilcoxon_results %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(dox_cardio_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of DOX Cardiotoxicity Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)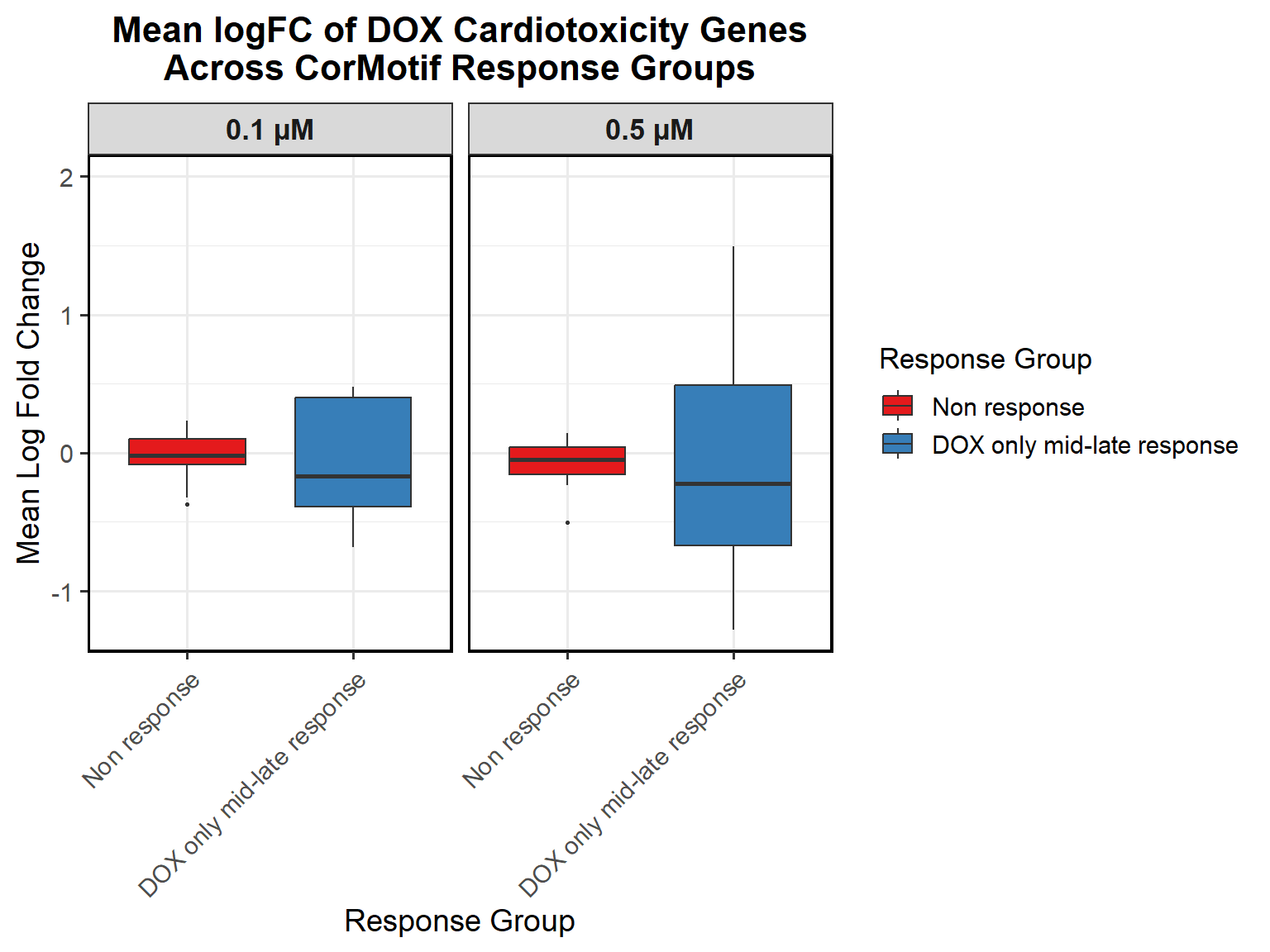
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DOX Cardiotoxicity genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DOX Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
847, 873, 2064, 2878, 2944, 3038, 4846, 51196, 5880, 6687,
7799, 4292, 5916, 3077, 51310, 9154, 64078, 5244, 10057, 10060,
89845, 56853, 4625, 1573, 79890
) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with DOX Cardiotoxicity Targets -----------------
dox_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(dox_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(dox_all$Concentration)) {
for (tp in levels(dox_all$Timepoint)) {
sub <- dox_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(dox_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(dox_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "DOX Cardiotoxicity Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)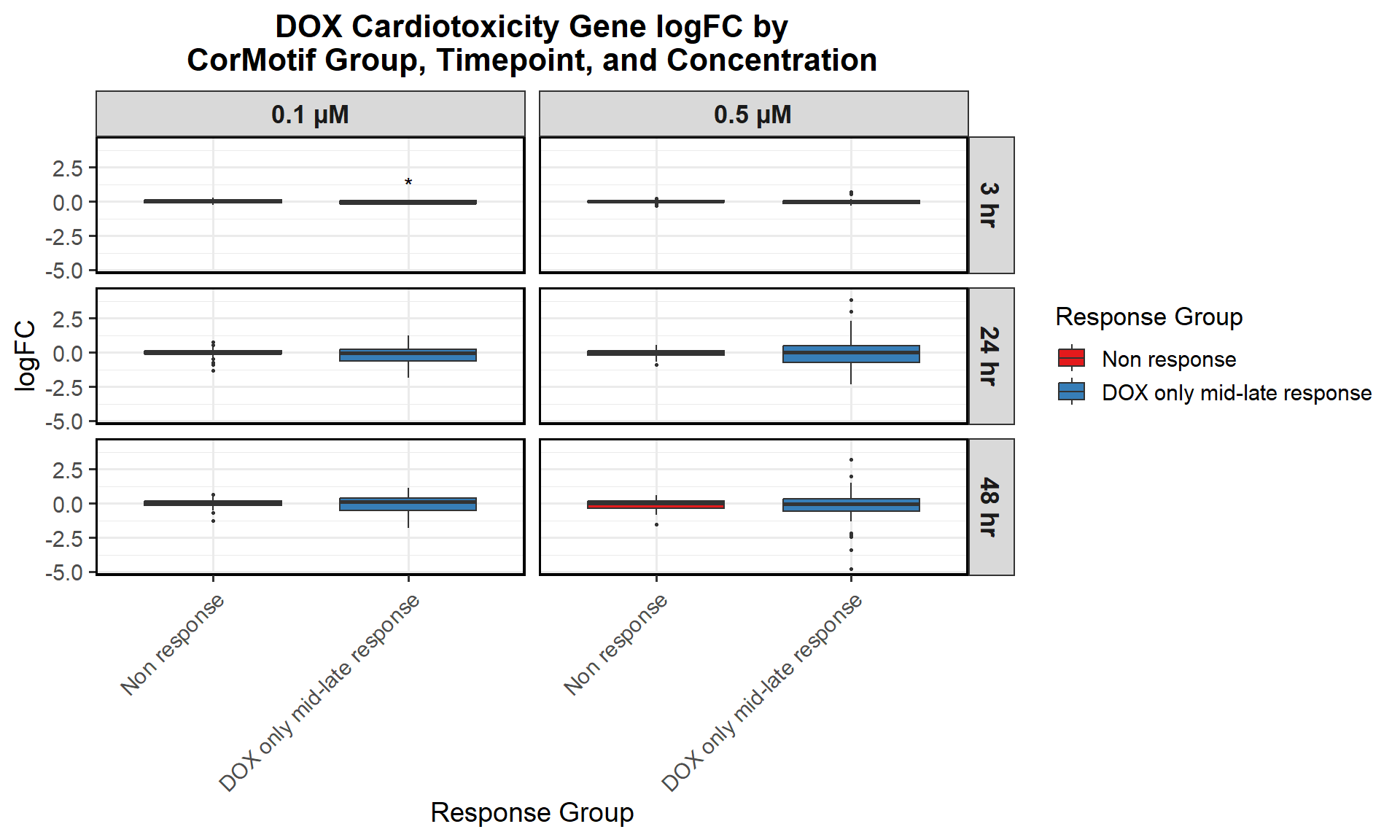
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of DOX Cardiotoxicity genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
################### DOX Cardiotoxicity Genes — 0.1 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DOX Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
847, 873, 2064, 2878, 2944, 3038, 4846, 51196, 5880, 6687,
7799, 4292, 5916, 3077, 51310, 9154, 64078, 5244, 10057, 10060,
89845, 56853, 4625, 1573, 79890
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM DOX Cardiotoxicity Genes) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "DOX Cardiotoxicity Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)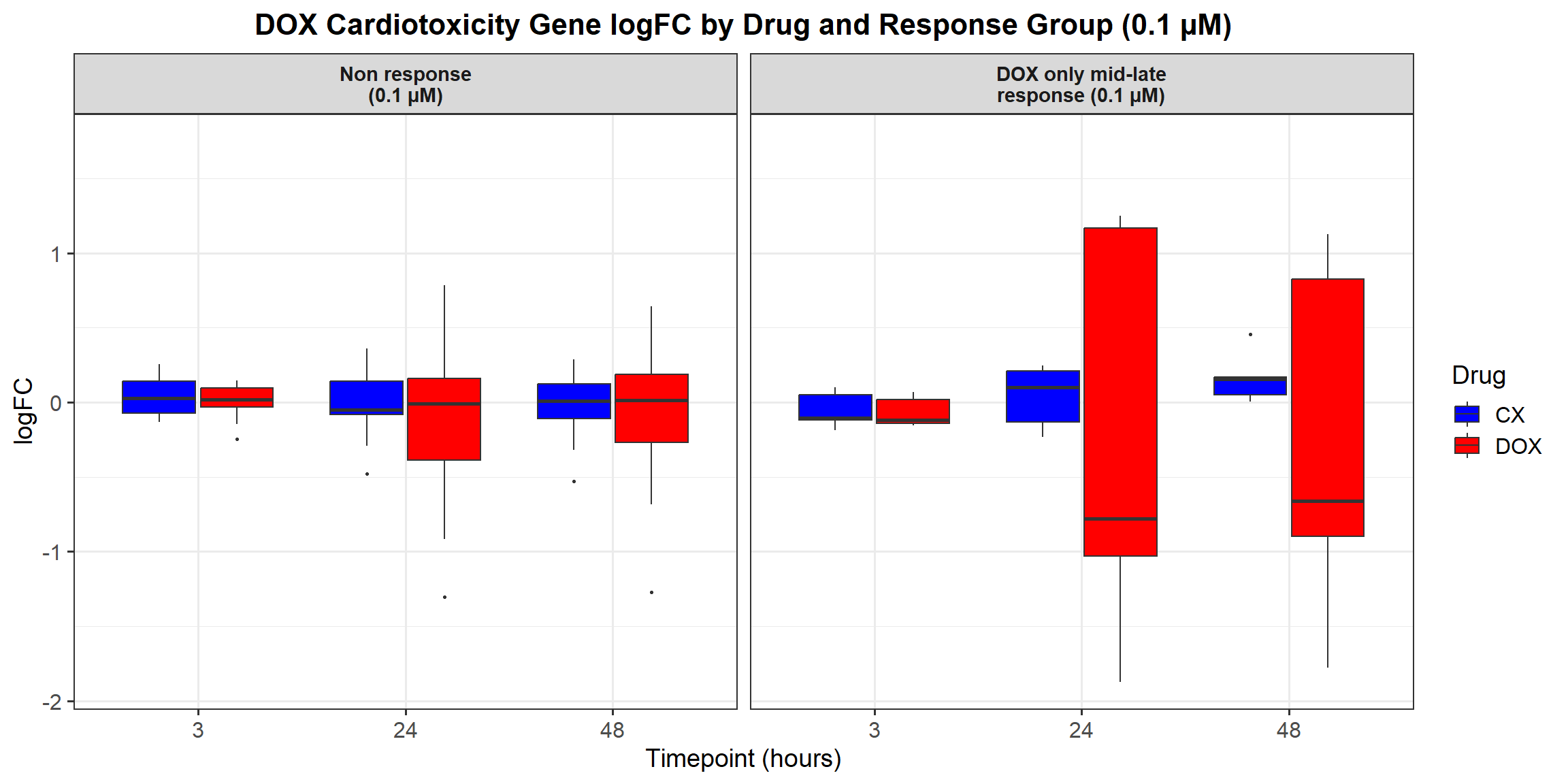
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
################### DOX Cardiotoxicity Genes — 0.5 µM ###################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- DOX Cardiotoxicity Entrez IDs -----------------
entrez_ids <- c(
847, 873, 2064, 2878, 2944, 3038, 4846, 51196, 5880, 6687,
7799, 4292, 5916, 3077, 51310, 9154, 64078, 5244, 10057, 10060,
89845, 56853, 4625, 1573, 79890
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM DOX Cardiotoxicity Genes) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(width = 0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "DOX Cardiotoxicity Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)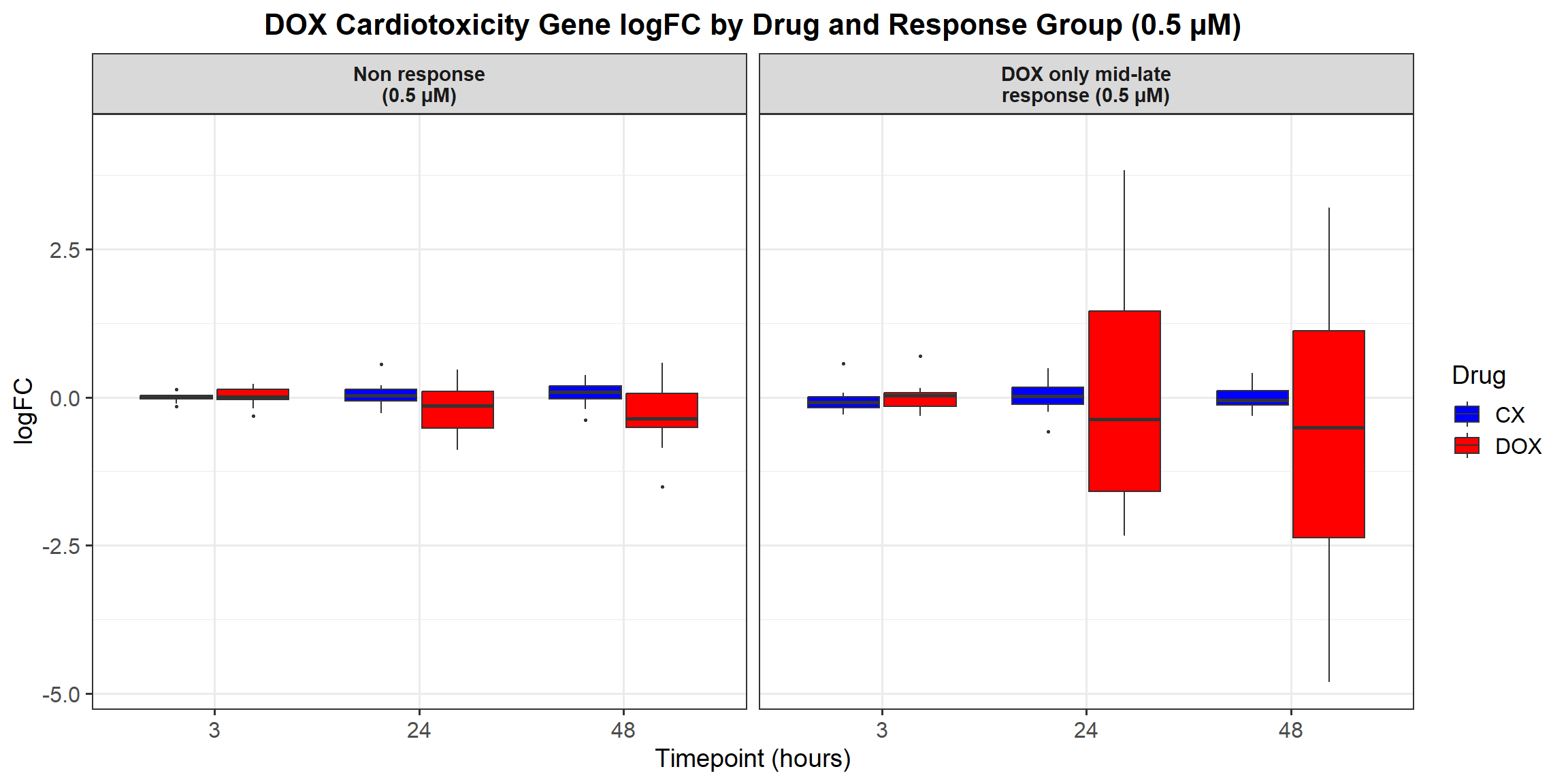
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of Heart Specific Genes (Combined)
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
heart_entrez_ids <- na.omit(heart_genes$Entrez_ID)
# ----------------- Load CorrMotif Groups -----------------
# 0.1
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% heart_entrez_ids, "Heart-specific Genes", "Non-Heart-specific Genes"),
Concentration = "0.1"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% heart_entrez_ids, "Heart-specific Genes", "Non-Heart-specific Genes"),
Concentration = "0.5"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Fisher's Exact Test -----------------
run_fisher_test <- function(df, ref_group) {
# Get reference counts
ref_counts <- df %>%
dplyr::ungroup() %>%
dplyr::filter(Response_Group == ref_group) %>%
dplyr::select(Category, Count) %>%
{setNames(.$Count, .$Category)}
# Run Fisher test for each group vs. reference
df %>%
dplyr::ungroup() %>%
dplyr::filter(Response_Group != ref_group) %>%
dplyr::group_by(Response_Group) %>%
dplyr::summarise(
p_value = {
group_counts <- Count[Category %in% c("Heart-specific Genes", "Non-Heart-specific Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["Heart-specific Genes"], ref_counts["Non-Heart-specific Genes"]
), nrow = 2)
fisher.test(contingency_table)$p.value
},
.groups = "drop"
) %>%
dplyr::mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# Run Fisher test
fisher_0.1 <- run_fisher_test(proportion_data %>% filter(Concentration == "0.1"), "Non response")
fisher_0.5 <- run_fisher_test(proportion_data %>% filter(Concentration == "0.5"), "Non response")
fisher_all <- bind_rows(
fisher_0.1 %>% mutate(Concentration = "0.1"),
fisher_0.5 %>% mutate(Concentration = "0.5")
)
# ----------------- Merge Fisher Results -----------------
proportion_data <- proportion_data %>%
left_join(fisher_all, by = c("Concentration", "Response_Group"))
# ----------------- Reorder Factor Levels -----------------
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1", "0.5"))
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
# ----------------- Significance Star Labels -----------------
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance)) %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(
data = label_data,
aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE,
size = 5,
color = "black"
) +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c(
"Heart-specific Genes" = "#4daf4a",
"Non-Heart-specific Genes" = "#377eb8"
)) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "Heart-Specific Gene Proportions Across\nCormotif Clusters (0.1 and 0.5 µM)",
x = "Response Groups",
y = "Percentage of Genes",
fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)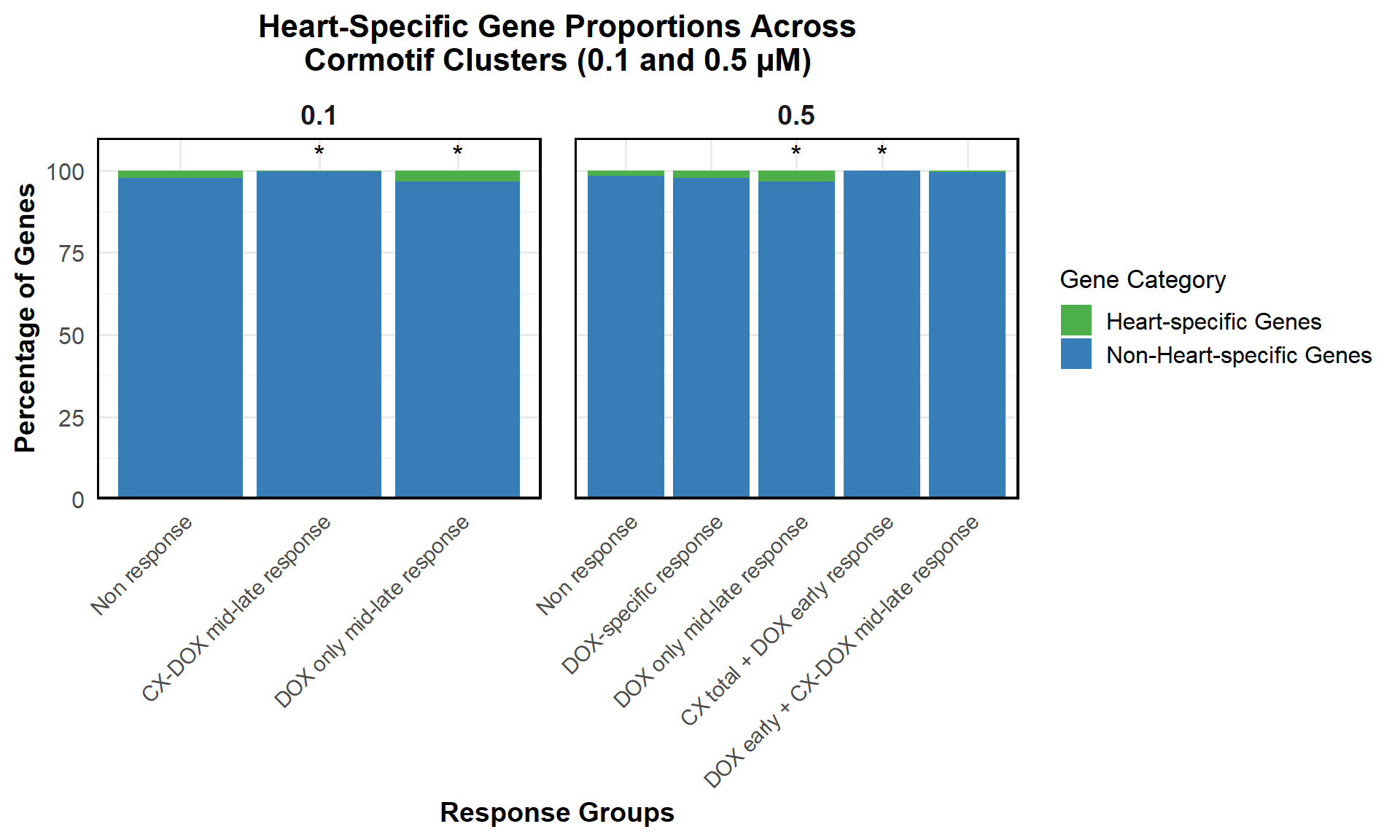
📌 Mean logFC of Heart specific genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
entrez_ids <- na.omit(heart_genes$Entrez_ID) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>% mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge with Group Annotations -----------------
heart_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Response Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
heart_logfc$Response_Group <- factor(heart_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- heart_logfc$logFC[heart_logfc$Group == resp_group]
control_vals <- heart_logfc$logFC[heart_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(
Group = resp_group,
y_pos = y_pos,
label = label,
P_Value = signif(pval, 4)
))
}
return(NULL)
}) %>% bind_rows()
# ----------------- Annotation Data -----------------
label_data <- wilcoxon_results %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(heart_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of Heart-Specific Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)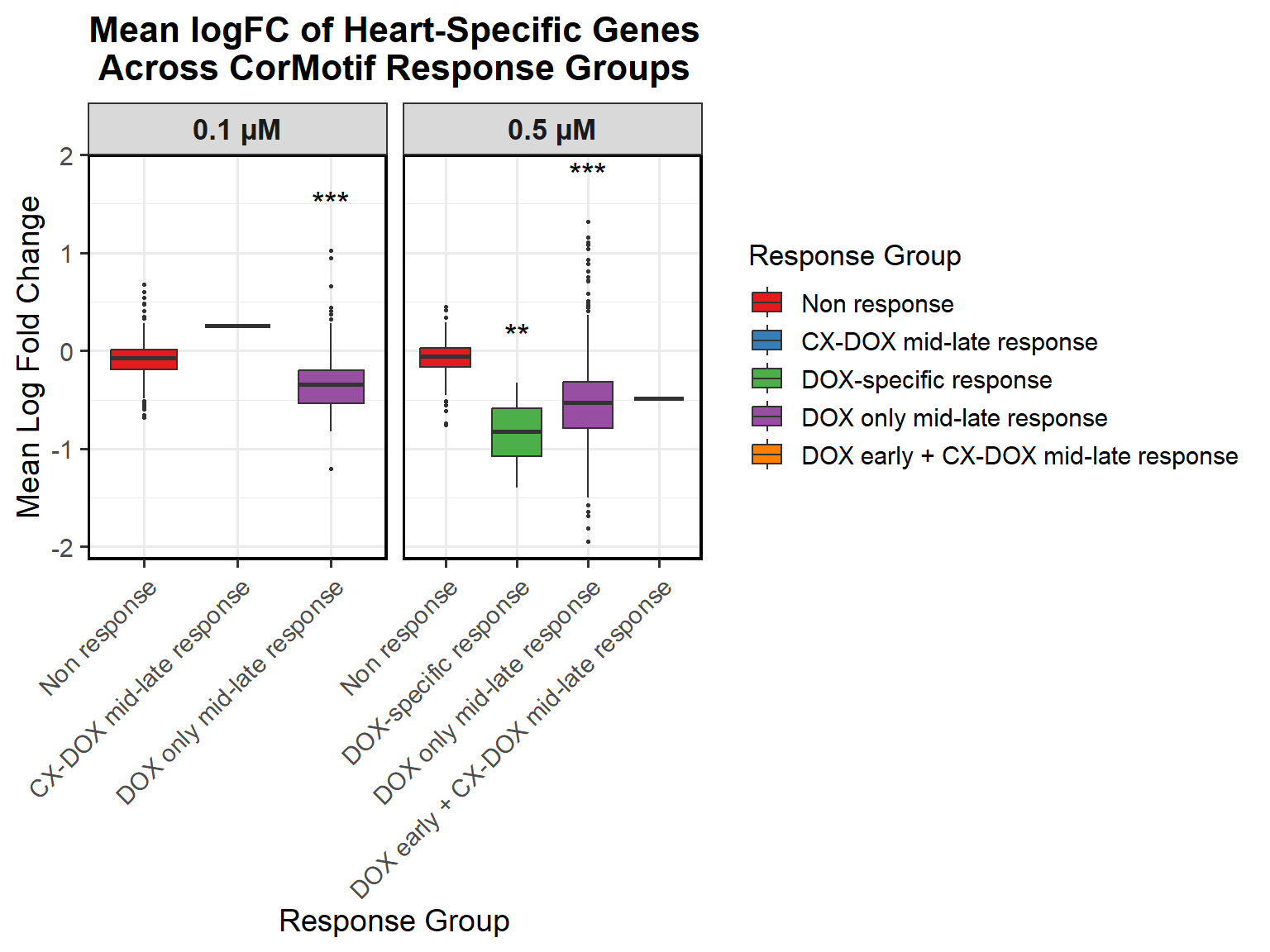
📌 Mean logFC of Heart specific genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
entrez_ids <- na.omit(heart_genes$Entrez_ID) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with Heart-Specific Targets -----------------
heart_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(heart_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(heart_all$Concentration)) {
for (tp in levels(heart_all$Timepoint)) {
sub <- heart_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(heart_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(heart_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Heart-Specific Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)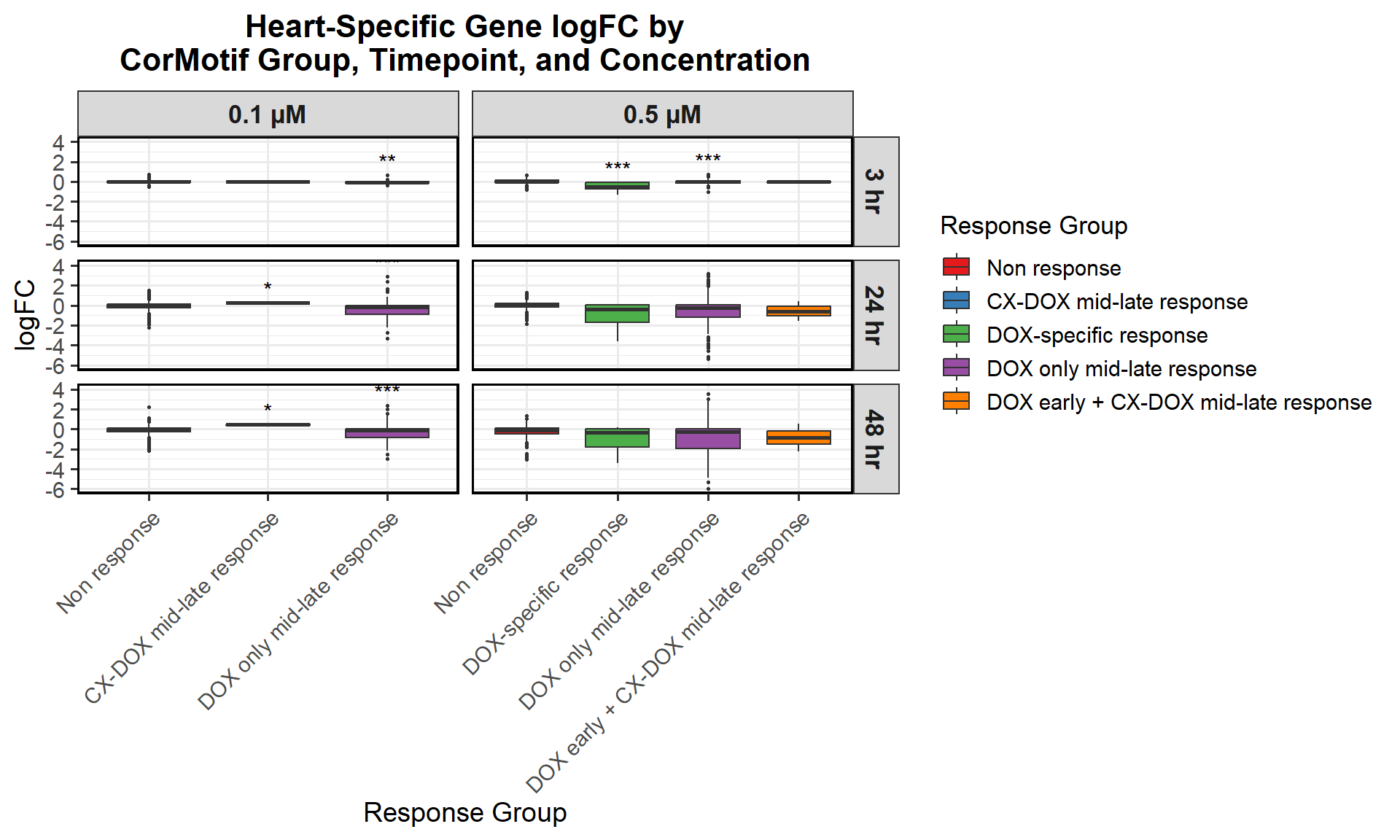
📌 Mean logFC of Heart specific genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
############ HEART-SPECIFIC GENES — 0.1 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
entrez_ids <- na.omit(heart_genes$Entrez_ID) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM Heart-Specific Genes) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "Heart-Specific Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)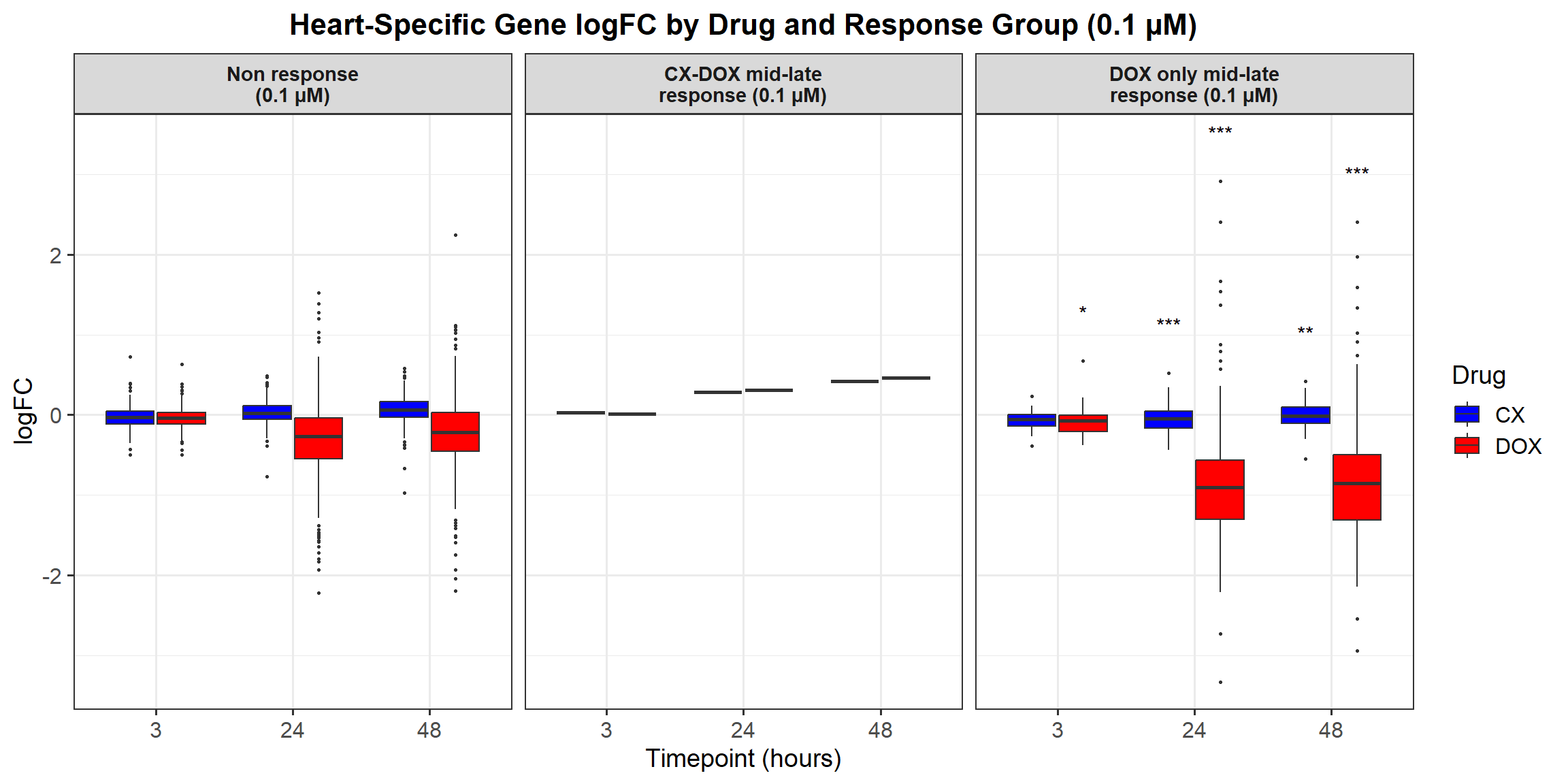
############ HEART-SPECIFIC GENES — 0.5 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
entrez_ids <- na.omit(heart_genes$Entrez_ID) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM Heart-Specific Genes) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "Heart-Specific Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)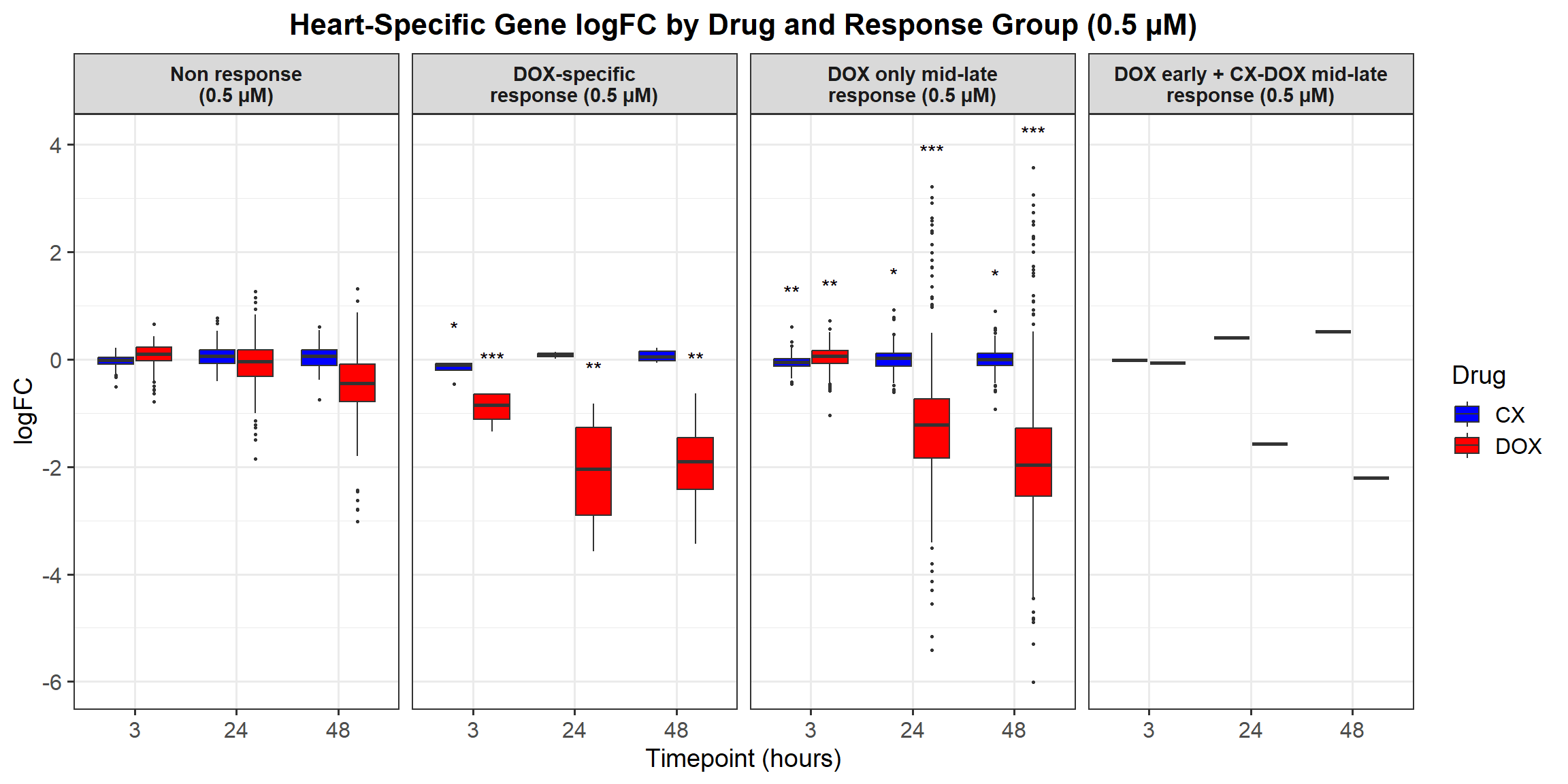
📌 Proportion of Atrial Fibrillation GWAS genes across corrmotifs
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
# ----------------- AF Entrez IDs -----------------
af_entrez_ids <- c(
3425, 53834, 9464, 79658, 55876, 3781, 9472, 11017, 64395, 23353,
57794, 79591, 2702, 51306, 857, 10418, 9644, 115509, 89797, 10728,
282996, 8497, 5695, 9026, 57666, 143384, 5883, 90102, 84909, 221037,
29119, 79933, 391, 81575, 8738, 5396, 26010, 744, 56981, 80724,
5781, 6910, 4598, 79068, 2250, 56978, 3752, 5208, 9736, 26778,
80315, 64374, 79159, 11078, 5308, 3782, 10654, 79776, 6310, 8082,
2995, 23224, 79741, 5708, 26136, 9967, 84033, 9148, 29982, 81488,
1788, 9208, 2908, 1021, 5339, 5727, 23118, 10090, 57585, 221154,
1073, 29998, 817, 858, 3486, 5747, 2104, 55105, 4194, 3570,
1607, 6586, 5570, 2070, 27145, 4646, 3159, 9748, 79991, 221035,
5033, 80212, 196385, 79600, 11046, 54014, 151636, 64778, 92597, 3983,
7090, 9267, 7273, 26018, 9948, 2131, 55870, 5523, 5318, 6239,
3480, 55777, 2066, 11165, 2028, 57619, 2690, 23414, 55818, 84700,
28965, 80204, 463, 5108, 222553, 387119, 28981, 11113, 10301, 995,
23030, 2697, 996, 339500, 54805, 9960, 91404, 145781, 100820829, 84542,
2176, 51684, 9513, 7473, 4666, 23150, 5915, 5062, 4016, 23039,
159686, 1839, 5201, 93166, 64753, 29959, 5496, 23245, 5069, 56916,
92344, 23092, 3992, 9415, 10554, 7456, 9570, 57178, 23143, 161176,
5424, 2034, 10277, 11278, 79803, 6653, 4756, 132660, 5430, 9031,
57158, 285761, 8110, 387700, 1829, 4126, 7323, 51308, 7332, 6598,
3757, 6187, 6660, 10529, 6920, 115286, 8451, 8943, 4137, 7514,
4801, 9709, 23177, 8671, 29915, 26207, 3680, 490, 493856, 58489,
54897, 4625, 22955, 84952, 10221, 2263, 84641, 4892, 1026, 84650,
8382, 221656, 2969, 144453, 117177, 2626, 8476, 161882, 51807, 4624,
9612, 55795, 51043, 144348, 51232, 8729, 3899, 11155, 23316, 79006,
146330, 6403, 6331, 4300, 427, 845, 3313, 113622, 5789, 376132,
29841, 8462, 203859, 401397, 5506, 55521, 5819, 4059, 6934, 57727,
23066, 79568, 83478, 10087, 9586, 222194, 10466, 10499, 58499, 79720,
4772, 10794, 125919, 602, 27332, 59345, 340359, 3705, 64710, 57801,
10818, 143684, 149281, 55013, 23095, 93649, 84034, 23347, 440926, 11124,
23293, 51426, 832, 7068, 57646, 152002, 7531, 1398, 100101267, 221937,
26873, 3709, 10576, 27040, 201176, 284403, 307, 6525, 5387, 1808,
114907, 1952, 4091, 5096, 23451, 51207, 142891, 4084, 3797, 1185,
5334, 217, 2042, 7781, 253461, 152404, 2992, 153478, 6695, 26249,
662, 23036, 22852, 23411, 23387, 6786, 7690, 10021, 8925, 5595,
63892, 23466, 11149, 139411, 755, 55347, 22820, 55111, 84444, 6258,
57623, 1387, 3762, 5861, 3339, 114822, 129787, 196528, 54437, 10395,
4023, 5095, 894, 3156, 1877, 283871, 2673, 23157, 10512, 2258,
79750, 84665, 26091, 5978, 8751, 79695, 2768, 155382, 84163, 7709,
4092, 1837, 2064, 4629, 55122, 8882, 150962, 23013, 8742, 489,
201134, 55114, 84264, 64428, 4089, 861, 7422
) %>% as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% af_entrez_ids, "AF Genes", "Non-AF Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% af_entrez_ids, "AF Genes", "Non-AF Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
df_combined$Category <- factor(df_combined$Category, levels = c("AF Genes", "Non-AF Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("AF Genes", "Non-AF Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["AF Genes"], ref_counts["Non-AF Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# ----------------- Run test -----------------
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")
chi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 4: `Response_Group = "DOX-specific response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Factor Order and Star Label -----------------
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c("AF Genes" = "#E41A1C", "Non-AF Genes" = "#377EB8")) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "AF-Associated Gene Proportions Across\nCormotif Clusters (0.1 and 0.5 µM)",
x = "Response Groups", y = "Percentage of Genes", fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)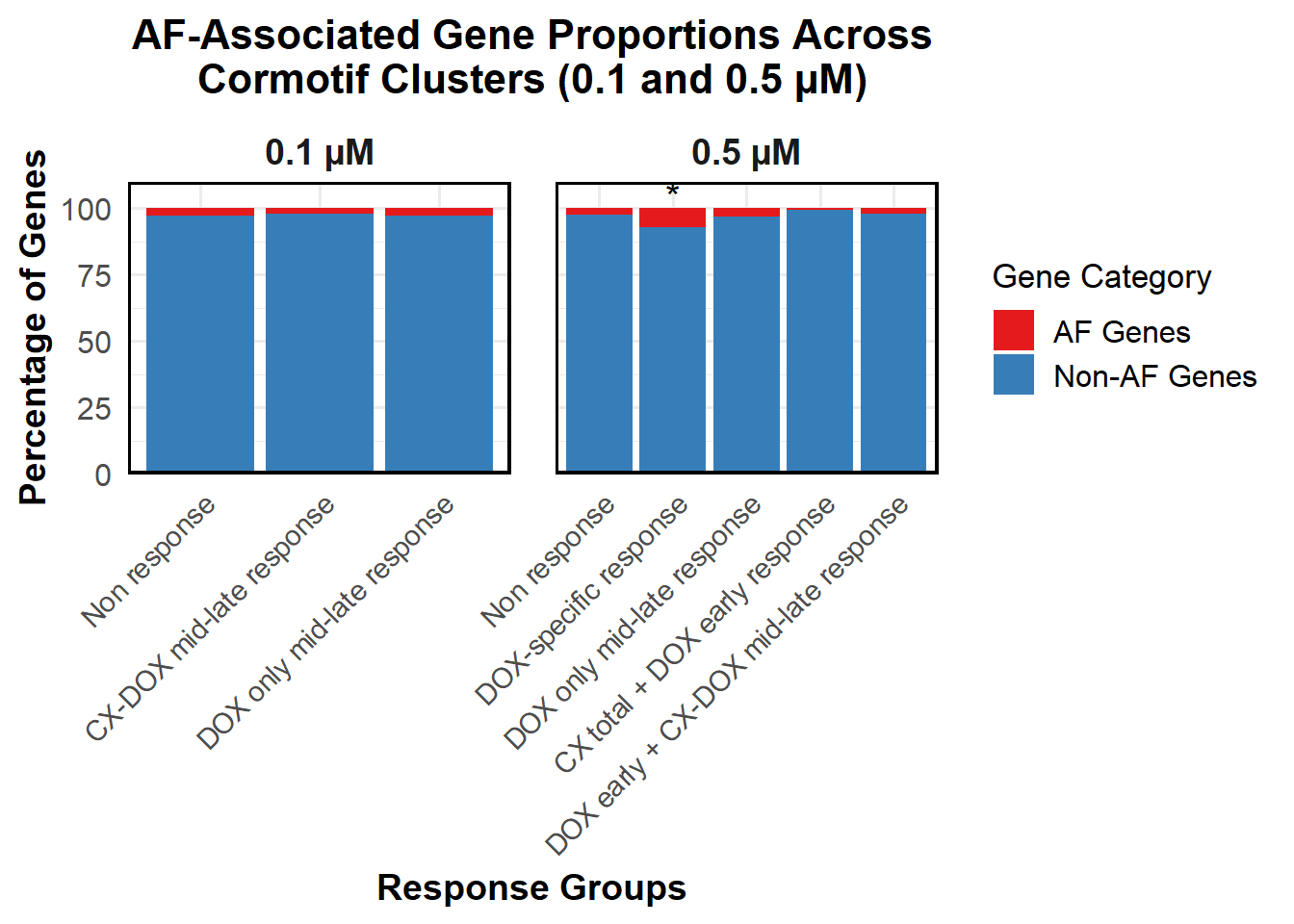
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Atrial Fibrillation GWAS genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AF Entrez IDs -----------------
entrez_ids <- c(
3425, 53834, 9464, 79658, 55876, 3781, 9472, 11017, 64395, 23353,
57794, 79591, 2702, 51306, 857, 10418, 9644, 115509, 89797, 10728,
282996, 8497, 5695, 9026, 57666, 143384, 5883, 90102, 84909, 221037,
29119, 79933, 391, 81575, 8738, 5396, 26010, 744, 56981, 80724,
5781, 6910, 4598, 79068, 2250, 56978, 3752, 5208, 9736, 26778,
80315, 64374, 79159, 11078, 5308, 3782, 10654, 79776, 6310, 8082,
2995, 23224, 79741, 5708, 26136, 9967, 84033, 9148, 29982, 81488,
1788, 9208, 2908, 1021, 5339, 5727, 23118, 10090, 57585, 221154,
1073, 29998, 817, 858, 3486, 5747, 2104, 55105, 4194, 3570,
1607, 6586, 5570, 2070, 27145, 4646, 3159, 9748, 79991, 221035,
5033, 80212, 196385, 79600, 11046, 54014, 151636, 64778, 92597, 3983,
7090, 9267, 7273, 26018, 9948, 2131, 55870, 5523, 5318, 6239,
3480, 55777, 2066, 11165, 2028, 57619, 2690, 23414, 55818, 84700,
28965, 80204, 463, 5108, 222553, 387119, 28981, 11113, 10301, 995,
23030, 2697, 996, 339500, 54805, 9960, 91404, 145781, 100820829, 84542,
2176, 51684, 9513, 7473, 4666, 23150, 5915, 5062, 4016, 23039,
159686, 1839, 5201, 93166, 64753, 29959, 5496, 23245, 5069, 56916,
92344, 23092, 3992, 9415, 10554, 7456, 9570, 57178, 23143, 161176,
5424, 2034, 10277, 11278, 79803, 6653, 4756, 132660, 5430, 9031,
57158, 285761, 8110, 387700, 1829, 4126, 7323, 51308, 7332, 6598,
3757, 6187, 6660, 10529, 6920, 115286, 8451, 8943, 4137, 7514,
4801, 9709, 23177, 8671, 29915, 26207, 3680, 490, 493856, 58489,
54897, 4625, 22955, 84952, 10221, 2263, 84641, 4892, 1026, 84650,
8382, 221656, 2969, 144453, 117177, 2626, 8476, 161882, 51807, 4624,
9612, 55795, 51043, 144348, 51232, 8729, 3899, 11155, 23316, 79006,
146330, 6403, 6331, 4300, 427, 845, 3313, 113622, 5789, 376132,
29841, 8462, 203859, 401397, 5506, 55521, 5819, 4059, 6934, 57727,
23066, 79568, 83478, 10087, 9586, 222194, 10466, 10499, 58499, 79720,
4772, 10794, 125919, 602, 27332, 59345, 340359, 3705, 64710, 57801,
10818, 143684, 149281, 55013, 23095, 93649, 84034, 23347, 440926, 11124,
23293, 51426, 832, 7068, 57646, 152002, 7531, 1398, 100101267, 221937,
26873, 3709, 10576, 27040, 201176, 284403, 307, 6525, 5387, 1808,
114907, 1952, 4091, 5096, 23451, 51207, 142891, 4084, 3797, 1185,
5334, 217, 2042, 7781, 253461, 152404, 2992, 153478, 6695, 26249,
662, 23036, 22852, 23411, 23387, 6786, 7690, 10021, 8925, 5595,
63892, 23466, 11149, 139411, 755, 55347, 22820, 55111, 84444, 6258,
57623, 1387, 3762, 5861, 3339, 114822, 129787, 196528, 54437, 10395,
4023, 5095, 894, 3156, 1877, 283871, 2673, 23157, 10512, 2258,
79750, 84665, 26091, 5978, 8751, 79695, 2768, 155382, 84163, 7709,
4092, 1837, 2064, 4629, 55122, 8882, 150962, 23013, 8742, 489,
201134, 55114, 84264, 64428, 4089, 861, 7422
) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>% mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge and Annotate -----------------
af_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Response Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
af_logfc$Response_Group <- factor(af_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- af_logfc$logFC[af_logfc$Group == resp_group]
control_vals <- af_logfc$logFC[af_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(Group = resp_group, y_pos = y_pos, label = label, P_Value = signif(pval, 4)))
}
return(NULL)
}) %>% bind_rows()
label_data <- wilcoxon_results %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(af_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of Atrial Fibrillation Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)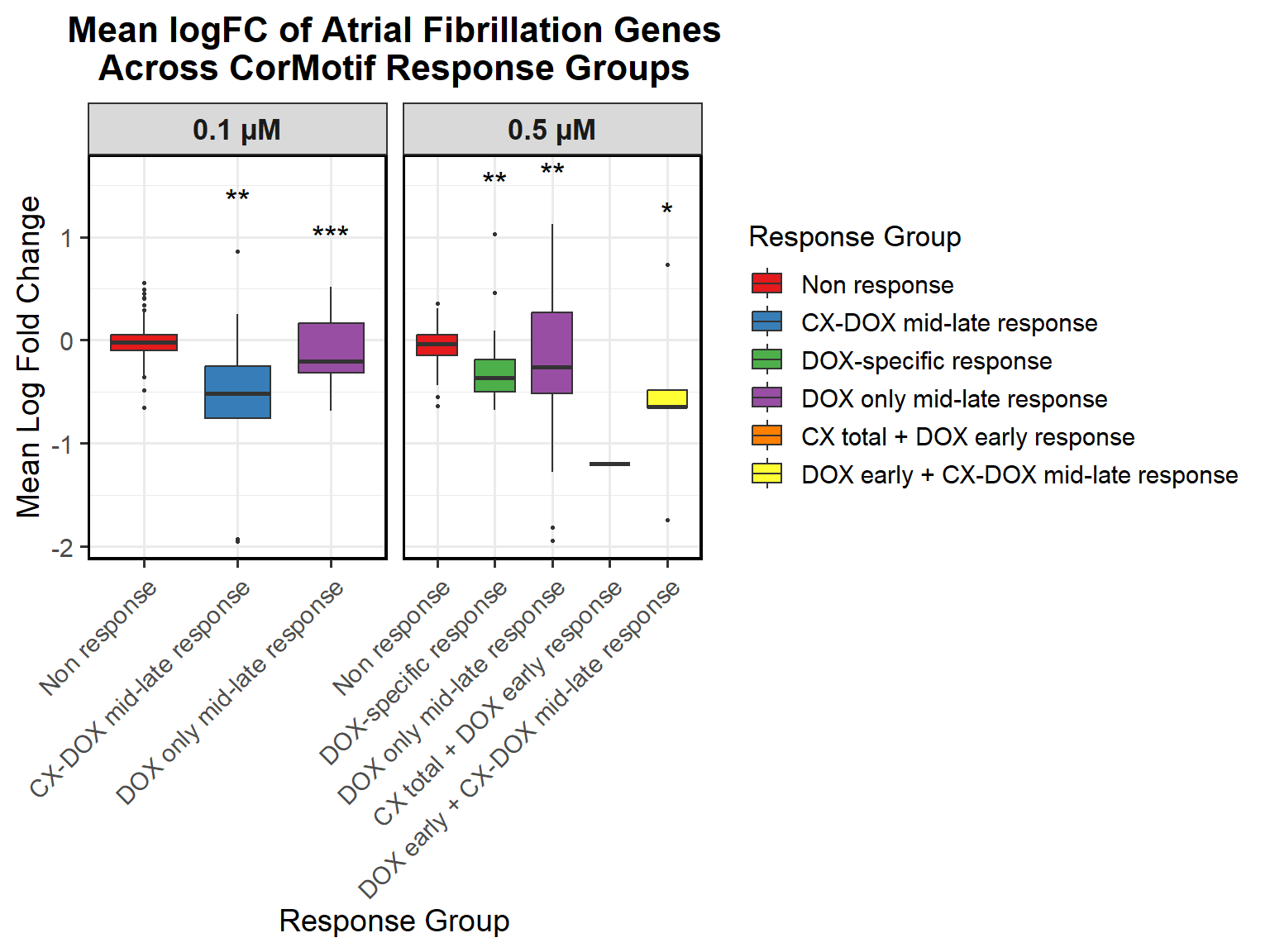
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Atrial Fibrillation GWAS genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Load Heart-Specific Genes -----------------
heart_genes <- read.csv("data/Human_Heart_Genes.csv", stringsAsFactors = FALSE)
heart_genes$Entrez_ID <- mapIds(
org.Hs.eg.db,
keys = heart_genes$Gene,
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
entrez_ids <- na.omit(heart_genes$Entrez_ID) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Annotate DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge with Heart-Specific Targets -----------------
heart_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID, column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Test -----------------
comparison_groups <- levels(heart_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(heart_all$Concentration)) {
for (tp in levels(heart_all$Timepoint)) {
sub <- heart_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(heart_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(heart_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Heart-Specific Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)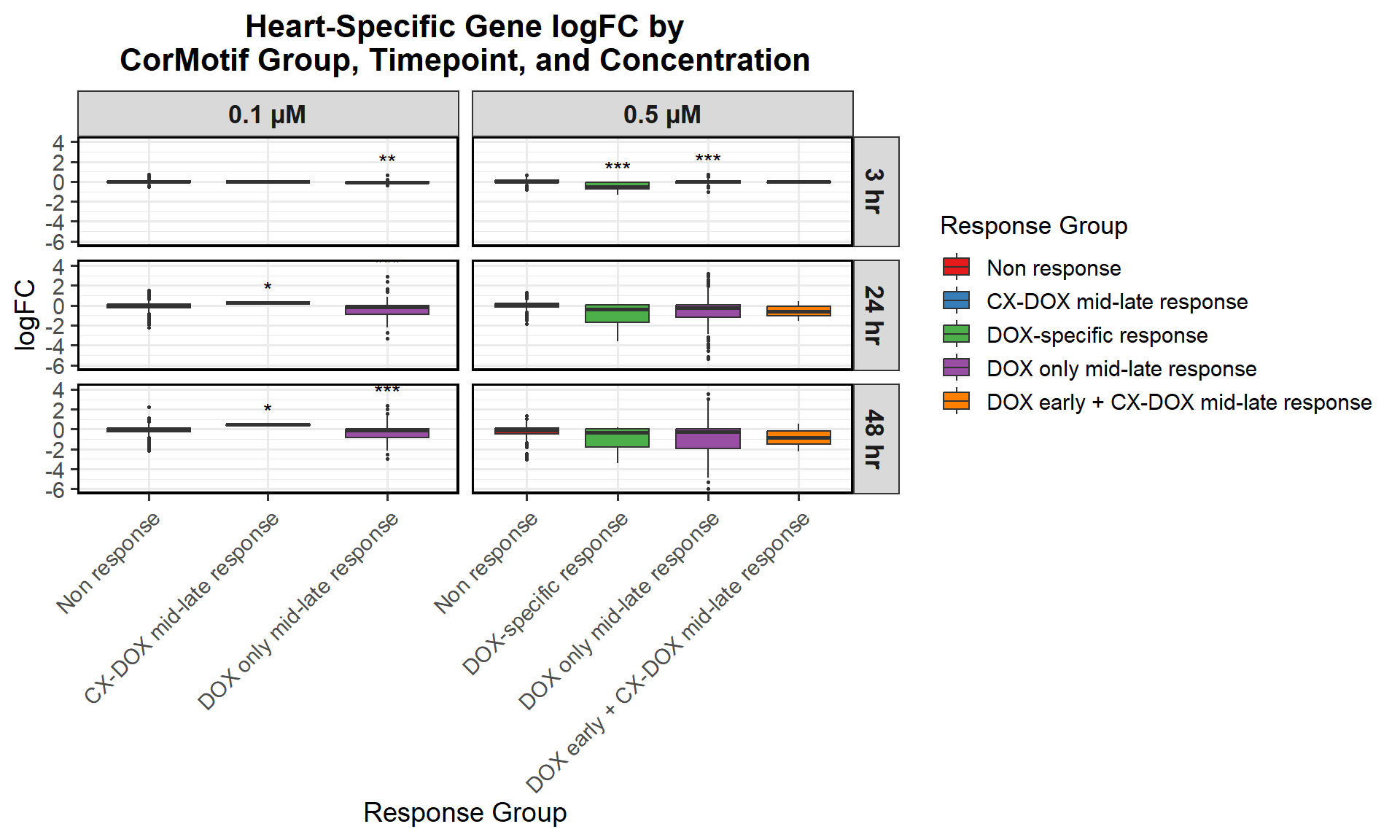
📌 Mean logFC of Atrial Fibrillation GWAS genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
############ AF GENES — 0.1 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AF Entrez IDs -----------------
entrez_ids <- c(
3425, 53834, 9464, 79658, 55876, 3781, 9472, 11017, 64395, 23353,
57794, 79591, 2702, 51306, 857, 10418, 9644, 115509, 89797, 10728,
282996, 8497, 5695, 9026, 57666, 143384, 5883, 90102, 84909, 221037,
29119, 79933, 391, 81575, 8738, 5396, 26010, 744, 56981, 80724,
5781, 6910, 4598, 79068, 2250, 56978, 3752, 5208, 9736, 26778,
80315, 64374, 79159, 11078, 5308, 3782, 10654, 79776, 6310, 8082,
2995, 23224, 79741, 5708, 26136, 9967, 84033, 9148, 29982, 81488,
1788, 9208, 2908, 1021, 5339, 5727, 23118, 10090, 57585, 221154,
1073, 29998, 817, 858, 3486, 5747, 2104, 55105, 4194, 3570,
1607, 6586, 5570, 2070, 27145, 4646, 3159, 9748, 79991, 221035,
5033, 80212, 196385, 79600, 11046, 54014, 151636, 64778, 92597, 3983,
7090, 9267, 7273, 26018, 9948, 2131, 55870, 5523, 5318, 6239,
3480, 55777, 2066, 11165, 2028, 57619, 2690, 23414, 55818, 84700,
28965, 80204, 463, 5108, 222553, 387119, 28981, 11113, 10301, 995,
23030, 2697, 996, 339500, 54805, 9960, 91404, 145781, 100820829, 84542,
2176, 51684, 9513, 7473, 4666, 23150, 5915, 5062, 4016, 23039,
159686, 1839, 5201, 93166, 64753, 29959, 5496, 23245, 5069, 56916,
92344, 23092, 3992, 9415, 10554, 7456, 9570, 57178, 23143, 161176,
5424, 2034, 10277, 11278, 79803, 6653, 4756, 132660, 5430, 9031,
57158, 285761, 8110, 387700, 1829, 4126, 7323, 51308, 7332, 6598,
3757, 6187, 6660, 10529, 6920, 115286, 8451, 8943, 4137, 7514,
4801, 9709, 23177, 8671, 29915, 26207, 3680, 490, 493856, 58489,
54897, 4625, 22955, 84952, 10221, 2263, 84641, 4892, 1026, 84650,
8382, 221656, 2969, 144453, 117177, 2626, 8476, 161882, 51807, 4624,
9612, 55795, 51043, 144348, 51232, 8729, 3899, 11155, 23316, 79006,
146330, 6403, 6331, 4300, 427, 845, 3313, 113622, 5789, 376132,
29841, 8462, 203859, 401397, 5506, 55521, 5819, 4059, 6934, 57727,
23066, 79568, 83478, 10087, 9586, 222194, 10466, 10499, 58499, 79720,
4772, 10794, 125919, 602, 27332, 59345, 340359, 3705, 64710, 57801,
10818, 143684, 149281, 55013, 23095, 93649, 84034, 23347, 440926, 11124,
23293, 51426, 832, 7068, 57646, 152002, 7531, 1398, 100101267, 221937,
26873, 3709, 10576, 27040, 201176, 284403, 307, 6525, 5387, 1808,
114907, 1952, 4091, 5096, 23451, 51207, 142891, 4084, 3797, 1185,
5334, 217, 2042, 7781, 253461, 152404, 2992, 153478, 6695, 26249,
662, 23036, 22852, 23411, 23387, 6786, 7690, 10021, 8925, 5595,
63892, 23466, 11149, 139411, 755, 55347, 22820, 55111, 84444, 6258,
57623, 1387, 3762, 5861, 3339, 114822, 129787, 196528, 54437, 10395,
4023, 5095, 894, 3156, 1877, 283871, 2673, 23157, 10512, 2258,
79750, 84665, 26091, 5978, 8751, 79695, 2768, 155382, 84163, 7709,
4092, 1837, 2064, 4629, 55122, 8882, 150962, 23013, 8742, 489,
201134, 55114, 84264, 64428, 4089, 861, 7422
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM AF Genes) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "AF-Associated Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)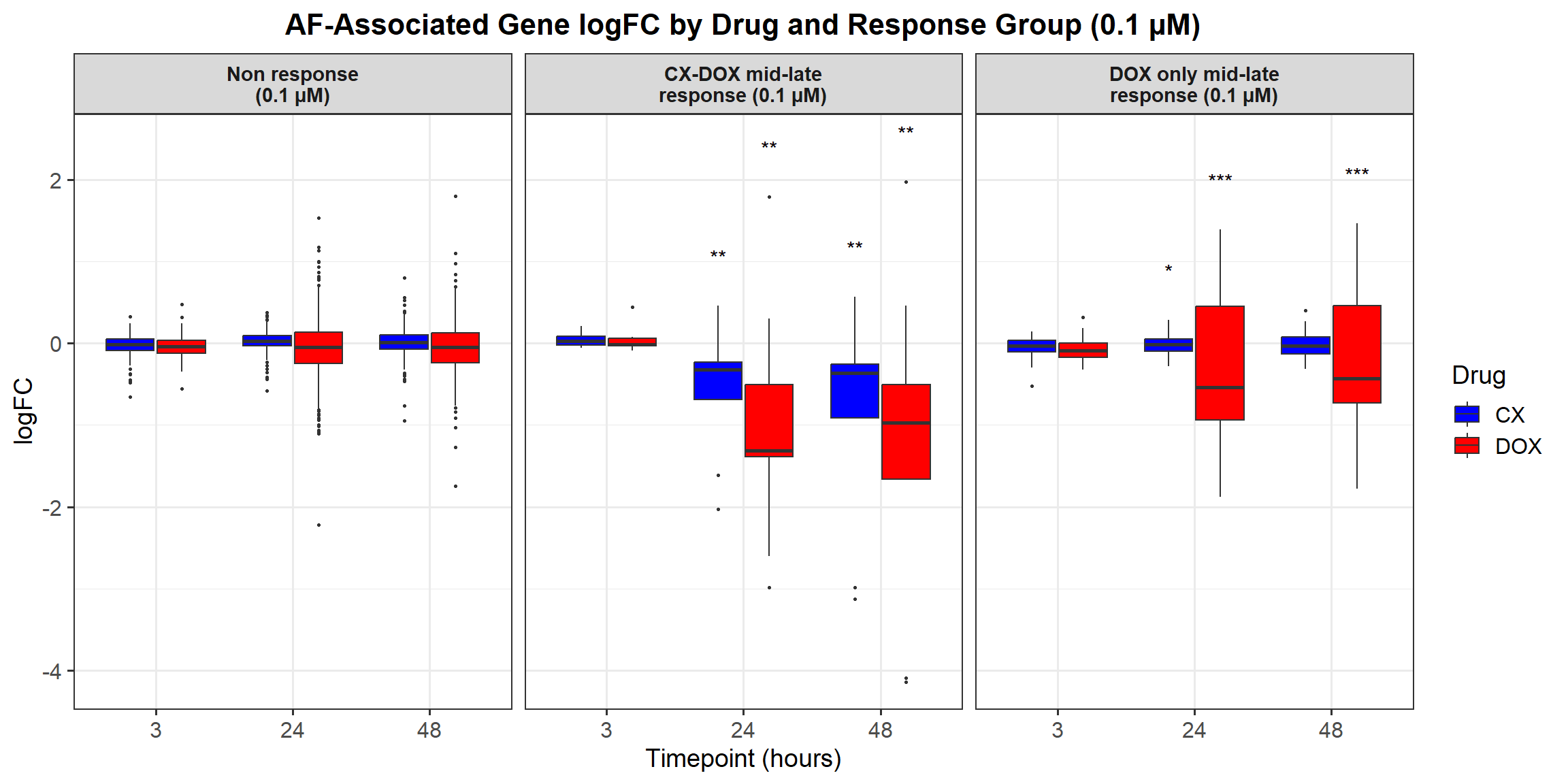
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
############ AF GENES — 0.5 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- AF Entrez IDs -----------------
entrez_ids <- c(
3425, 53834, 9464, 79658, 55876, 3781, 9472, 11017, 64395, 23353,
57794, 79591, 2702, 51306, 857, 10418, 9644, 115509, 89797, 10728,
282996, 8497, 5695, 9026, 57666, 143384, 5883, 90102, 84909, 221037,
29119, 79933, 391, 81575, 8738, 5396, 26010, 744, 56981, 80724,
5781, 6910, 4598, 79068, 2250, 56978, 3752, 5208, 9736, 26778,
80315, 64374, 79159, 11078, 5308, 3782, 10654, 79776, 6310, 8082,
2995, 23224, 79741, 5708, 26136, 9967, 84033, 9148, 29982, 81488,
1788, 9208, 2908, 1021, 5339, 5727, 23118, 10090, 57585, 221154,
1073, 29998, 817, 858, 3486, 5747, 2104, 55105, 4194, 3570,
1607, 6586, 5570, 2070, 27145, 4646, 3159, 9748, 79991, 221035,
5033, 80212, 196385, 79600, 11046, 54014, 151636, 64778, 92597, 3983,
7090, 9267, 7273, 26018, 9948, 2131, 55870, 5523, 5318, 6239,
3480, 55777, 2066, 11165, 2028, 57619, 2690, 23414, 55818, 84700,
28965, 80204, 463, 5108, 222553, 387119, 28981, 11113, 10301, 995,
23030, 2697, 996, 339500, 54805, 9960, 91404, 145781, 100820829, 84542,
2176, 51684, 9513, 7473, 4666, 23150, 5915, 5062, 4016, 23039,
159686, 1839, 5201, 93166, 64753, 29959, 5496, 23245, 5069, 56916,
92344, 23092, 3992, 9415, 10554, 7456, 9570, 57178, 23143, 161176,
5424, 2034, 10277, 11278, 79803, 6653, 4756, 132660, 5430, 9031,
57158, 285761, 8110, 387700, 1829, 4126, 7323, 51308, 7332, 6598,
3757, 6187, 6660, 10529, 6920, 115286, 8451, 8943, 4137, 7514,
4801, 9709, 23177, 8671, 29915, 26207, 3680, 490, 493856, 58489,
54897, 4625, 22955, 84952, 10221, 2263, 84641, 4892, 1026, 84650,
8382, 221656, 2969, 144453, 117177, 2626, 8476, 161882, 51807, 4624,
9612, 55795, 51043, 144348, 51232, 8729, 3899, 11155, 23316, 79006,
146330, 6403, 6331, 4300, 427, 845, 3313, 113622, 5789, 376132,
29841, 8462, 203859, 401397, 5506, 55521, 5819, 4059, 6934, 57727,
23066, 79568, 83478, 10087, 9586, 222194, 10466, 10499, 58499, 79720,
4772, 10794, 125919, 602, 27332, 59345, 340359, 3705, 64710, 57801,
10818, 143684, 149281, 55013, 23095, 93649, 84034, 23347, 440926, 11124,
23293, 51426, 832, 7068, 57646, 152002, 7531, 1398, 100101267, 221937,
26873, 3709, 10576, 27040, 201176, 284403, 307, 6525, 5387, 1808,
114907, 1952, 4091, 5096, 23451, 51207, 142891, 4084, 3797, 1185,
5334, 217, 2042, 7781, 253461, 152404, 2992, 153478, 6695, 26249,
662, 23036, 22852, 23411, 23387, 6786, 7690, 10021, 8925, 5595,
63892, 23466, 11149, 139411, 755, 55347, 22820, 55111, 84444, 6258,
57623, 1387, 3762, 5861, 3339, 114822, 129787, 196528, 54437, 10395,
4023, 5095, 894, 3156, 1877, 283871, 2673, 23157, 10512, 2258,
79750, 84665, 26091, 5978, 8751, 79695, 2768, 155382, 84163, 7709,
4092, 1837, 2064, 4629, 55122, 8882, 150962, 23013, 8742, 489,
201134, 55114, 84264, 64428, 4089, 861, 7422
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM AF Genes) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "AF-Associated Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)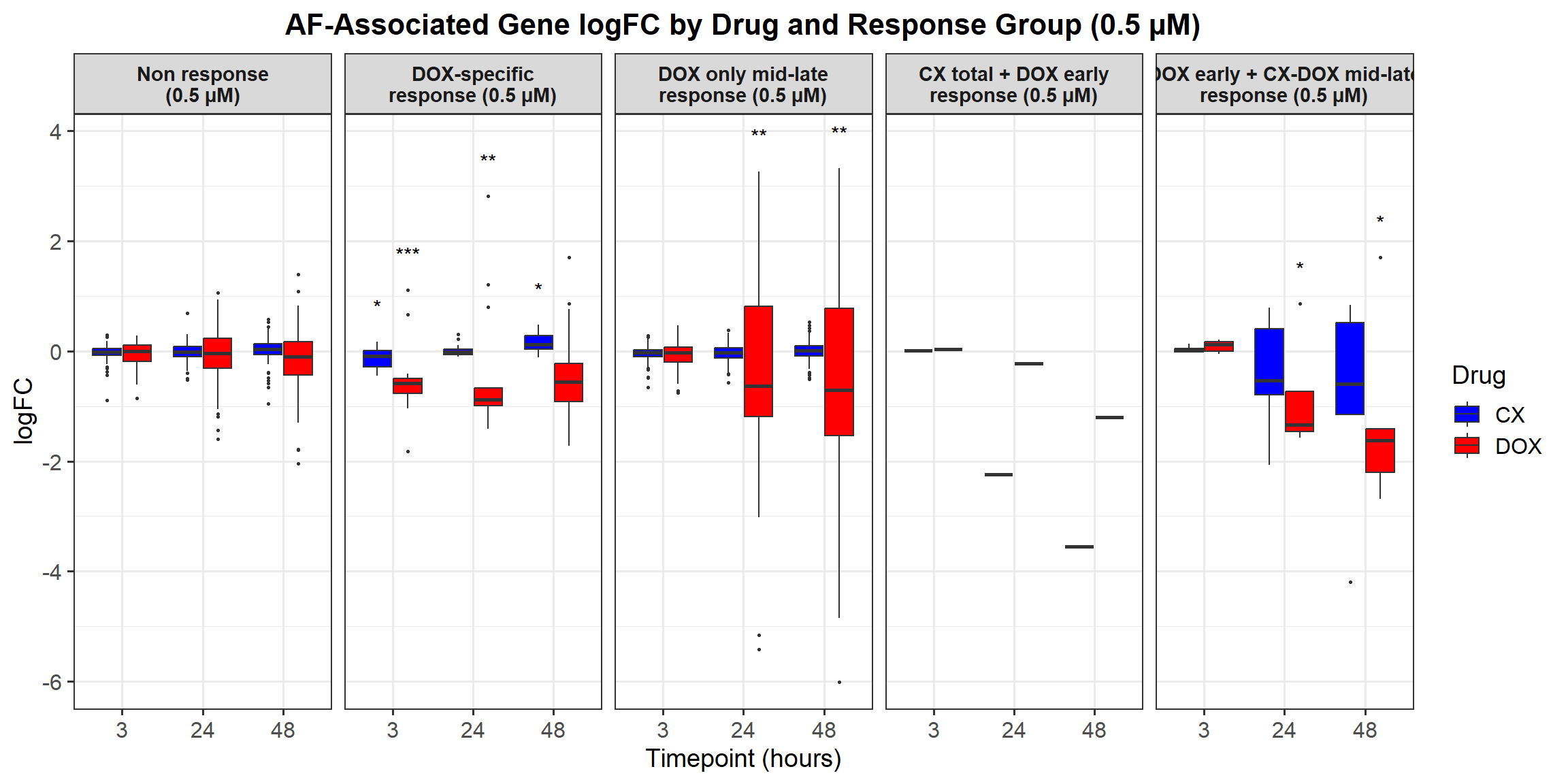
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Proportion of Heart Failure GWAS genes across corrmotifs (per concentration)
# ----------------- Load Required Libraries -----------------
library(dplyr)
library(ggplot2)
# ----------------- Heart Failure Entrez IDs -----------------
hf_entrez_ids <- c(
9709, 8882, 4023, 29959, 5496, 3992, 9415, 5308, 1026, 54437, 79068, 10221,
9031, 1187, 1952, 3705, 84722, 7273, 23293, 155382, 9531, 602, 27258, 84163,
81846, 79933, 56911, 64753, 93210, 1021, 283450, 5998, 57602, 114991, 7073,
3156, 100101267, 22996, 285025, 11080, 11124, 54810, 7531, 27241, 4774, 57794,
463, 91319, 6598, 9640, 2186, 26010, 80816, 571, 88, 51652, 64788, 90523, 2969,
7781, 80777, 10725, 23387, 817, 134728, 8842, 949, 6934, 129787, 10327, 202052,
2318, 5578, 6801, 6311, 10019, 80724, 217, 84909, 388591, 55101, 9839, 27161,
5310, 387119, 4641, 5587, 55188, 222553, 9960, 22852, 10087, 9570, 54497,
200942, 26249, 4137, 375056, 5409, 64116, 8291, 22876, 339855, 4864, 5142,
221692, 55023, 51426, 6146, 84251, 8189, 27332, 57099, 1869, 1112, 23327,
11264, 6001
) %>% as.character()
# ----------------- Load CorrMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorrMotif Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Category = ifelse(Entrez_ID %in% hf_entrez_ids, "HF Genes", "Non-HF Genes"),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Category = ifelse(Entrez_ID %in% hf_entrez_ids, "HF Genes", "Non-HF Genes"),
Concentration = "0.5 µM"
)
# ----------------- Combine Data -----------------
df_combined <- bind_rows(df_0.1, df_0.5)
df_combined$Category <- factor(df_combined$Category, levels = c("HF Genes", "Non-HF Genes"))
# ----------------- Calculate Proportions -----------------
proportion_data <- df_combined %>%
group_by(Concentration, Response_Group, Category) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Concentration, Response_Group) %>%
mutate(Percentage = Count / sum(Count) * 100)
# ----------------- Chi-square or Fisher's Test -----------------
get_chi_or_fisher <- function(df, ref_group) {
ref_counts <- df %>%
ungroup() %>%
filter(Response_Group == ref_group) %>%
{ ref_tbl <- .[ , c("Category", "Count")]; setNames(ref_tbl$Count, ref_tbl$Category) }
df %>%
filter(Response_Group != ref_group) %>%
group_by(Response_Group) %>%
summarise(
p_value = {
group_counts <- Count[Category %in% c("HF Genes", "Non-HF Genes")]
if (length(group_counts) < 2) group_counts <- c(group_counts, 0)
contingency_table <- matrix(c(
group_counts[1], group_counts[2],
ref_counts["HF Genes"], ref_counts["Non-HF Genes"]
), nrow = 2)
if (any(contingency_table < 5)) {
fisher.test(contingency_table)$p.value
} else {
chisq.test(contingency_table)$p.value
}
},
.groups = "drop"
) %>%
mutate(Significance = ifelse(!is.na(p_value) & p_value < 0.05, "*", ""))
}
# ----------------- Run test -----------------
chi_0.1 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.1 µM"), "Non response")Warning: There was 1 warning in `summarise()`.
ℹ In argument: `p_value = { ... }`.
ℹ In group 1: `Response_Group = "CX-DOX mid-late response"`.
Caused by warning in `chisq.test()`:
! Chi-squared approximation may be incorrectchi_0.5 <- get_chi_or_fisher(proportion_data %>% filter(Concentration == "0.5 µM"), "Non response")
chi_all <- bind_rows(
chi_0.1 %>% mutate(Concentration = "0.1 µM"),
chi_0.5 %>% mutate(Concentration = "0.5 µM")
)
proportion_data <- left_join(proportion_data, chi_all, by = c("Concentration", "Response_Group"))
# ----------------- Factor Order and Star Label -----------------
proportion_data$Response_Group <- factor(proportion_data$Response_Group, levels = c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
))
proportion_data$Concentration <- factor(proportion_data$Concentration, levels = c("0.1 µM", "0.5 µM"))
label_data <- proportion_data %>%
group_by(Concentration, Response_Group) %>%
summarise(Significance = dplyr::first(Significance), .groups = "drop") %>%
filter(!is.na(Significance) & Significance != "") %>%
mutate(y_pos = 105)
# ----------------- Final Plot -----------------
ggplot(proportion_data, aes(x = Response_Group, y = Percentage, fill = Category)) +
geom_bar(stat = "identity", position = "stack") +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = Significance),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~ Concentration, scales = "free_x") +
scale_fill_manual(values = c("HF Genes" = "#E41A1C", "Non-HF Genes" = "#377EB8")) +
scale_y_continuous(limits = c(0, 110), expand = c(0, 0)) +
labs(
title = "Heart Failure Gene Proportions Across\nCormotif Clusters (0.1 and 0.5 µM)",
x = "Response Groups", y = "Percentage of Genes", fill = "Gene Category"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, hjust = 0.5, face = "bold"),
axis.title.x = element_text(size = 14, face = "bold"),
axis.title.y = element_text(size = 14, face = "bold"),
axis.text.x = element_text(size = 11, angle = 45, hjust = 1),
axis.text.y = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
strip.text = element_text(size = 14, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2),
panel.spacing = unit(1.2, "lines")
)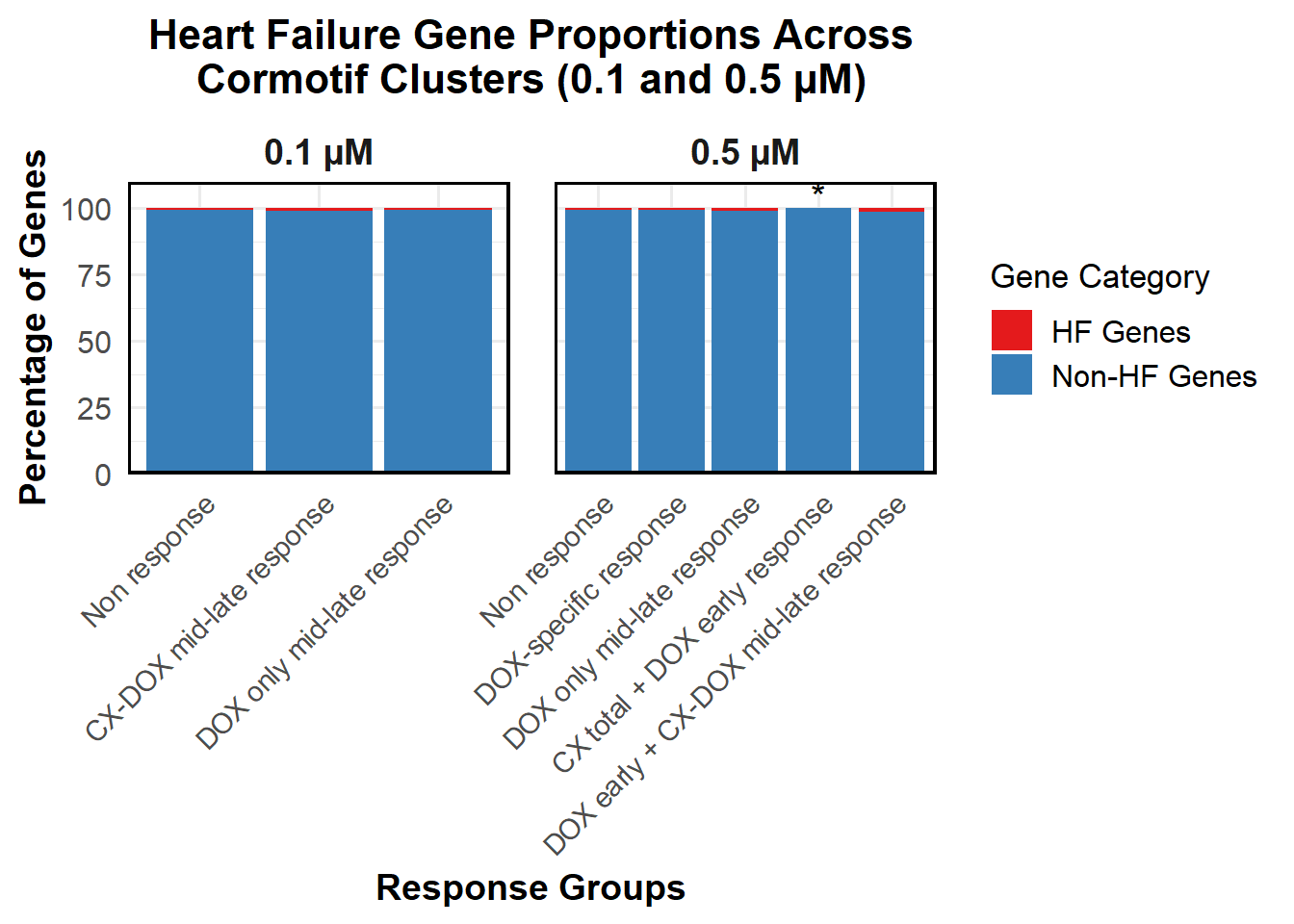
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Heart Failure GWAS genes across corrmotifs (per concentration)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Heart Failure Entrez IDs -----------------
entrez_ids <- c(
9709, 8882, 4023, 29959, 5496, 3992, 9415, 5308, 1026, 54437, 79068, 10221,
9031, 1187, 1952, 3705, 84722, 7273, 23293, 155382, 9531, 602, 27258, 84163,
81846, 79933, 56911, 64753, 93210, 1021, 283450, 5998, 57602, 114991, 7073,
3156, 100101267, 22996, 285025, 11080, 11124, 54810, 7531, 27241, 4774, 57794,
463, 91319, 6598, 9640, 2186, 26010, 80816, 571, 88, 51652, 64788, 90523, 2969,
7781, 80777, 10725, 23387, 817, 134728, 8842, 949, 6934, 129787, 10327, 202052,
2318, 5578, 6801, 6311, 10019, 80724, 217, 84909, 388591, 55101, 9839, 27161,
5310, 387119, 4641, 5587, 55188, 222553, 9960, 22852, 10087, 9570, 54497,
200942, 26249, 4137, 375056, 5409, 64116, 8291, 22876, 339855, 4864, 5142,
221692, 55023, 51426, 6146, 84251, 8189, 27332, 57099, 1869, 1112, 23327,
11264, 6001
) %>% as.character()
# ----------------- Load CorMotif Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate Response Groups -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load and Aggregate DEG Data -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
)
)
deg_mean <- deg_all %>%
group_by(Entrez_ID, Concentration) %>%
summarise(logFC = mean(logFC, na.rm = TRUE), .groups = "drop")
# ----------------- Merge and Annotate -----------------
hf_logfc <- inner_join(df_combined, deg_mean, by = c("Entrez_ID", "Concentration")) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Group = paste(Response_Group, Concentration)
)
# ----------------- Define Group Order -----------------
group_levels <- c(
"Non response",
"CX-DOX mid-late response",
"DOX-specific response",
"DOX only mid-late response",
"CX total + DOX early response",
"DOX early + CX-DOX mid-late response"
)
hf_logfc$Response_Group <- factor(hf_logfc$Response_Group, levels = group_levels)
# ----------------- Wilcoxon Test -----------------
comparison_map <- list(
"CX-DOX mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX only mid-late response 0.1 µM" = "Non response 0.1 µM",
"DOX-specific response 0.5 µM" = "Non response 0.5 µM",
"DOX only mid-late response 0.5 µM" = "Non response 0.5 µM",
"CX total + DOX early response 0.5 µM" = "Non response 0.5 µM",
"DOX early + CX-DOX mid-late response 0.5 µM" = "Non response 0.5 µM"
)
wilcoxon_results <- lapply(names(comparison_map), function(resp_group) {
control_group <- comparison_map[[resp_group]]
resp_vals <- hf_logfc$logFC[hf_logfc$Group == resp_group]
control_vals <- hf_logfc$logFC[hf_logfc$Group == control_group]
if (length(resp_vals) >= 2 && length(control_vals) >= 2) {
test_result <- wilcox.test(resp_vals, control_vals)
pval <- test_result$p.value
label <- case_when(
pval < 0.001 ~ "***",
pval < 0.01 ~ "**",
pval < 0.05 ~ "*",
TRUE ~ ""
)
y_pos <- max(resp_vals, na.rm = TRUE) + 0.5
return(data.frame(Group = resp_group, y_pos = y_pos, label = label, P_Value = signif(pval, 4)))
}
return(NULL)
}) %>% bind_rows()
label_data <- wilcoxon_results %>%
separate(Group, into = c("Response_Group", "Concentration"), sep = " (?=0\\.)") %>%
mutate(Response_Group = factor(Response_Group, levels = group_levels))
# ----------------- Plot -----------------
ggplot(hf_logfc, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 5, color = "black") +
facet_wrap(~Concentration, scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Mean logFC of Heart Failure Genes\nAcross CorMotif Response Groups",
x = "Response Group",
y = "Mean Log Fold Change",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)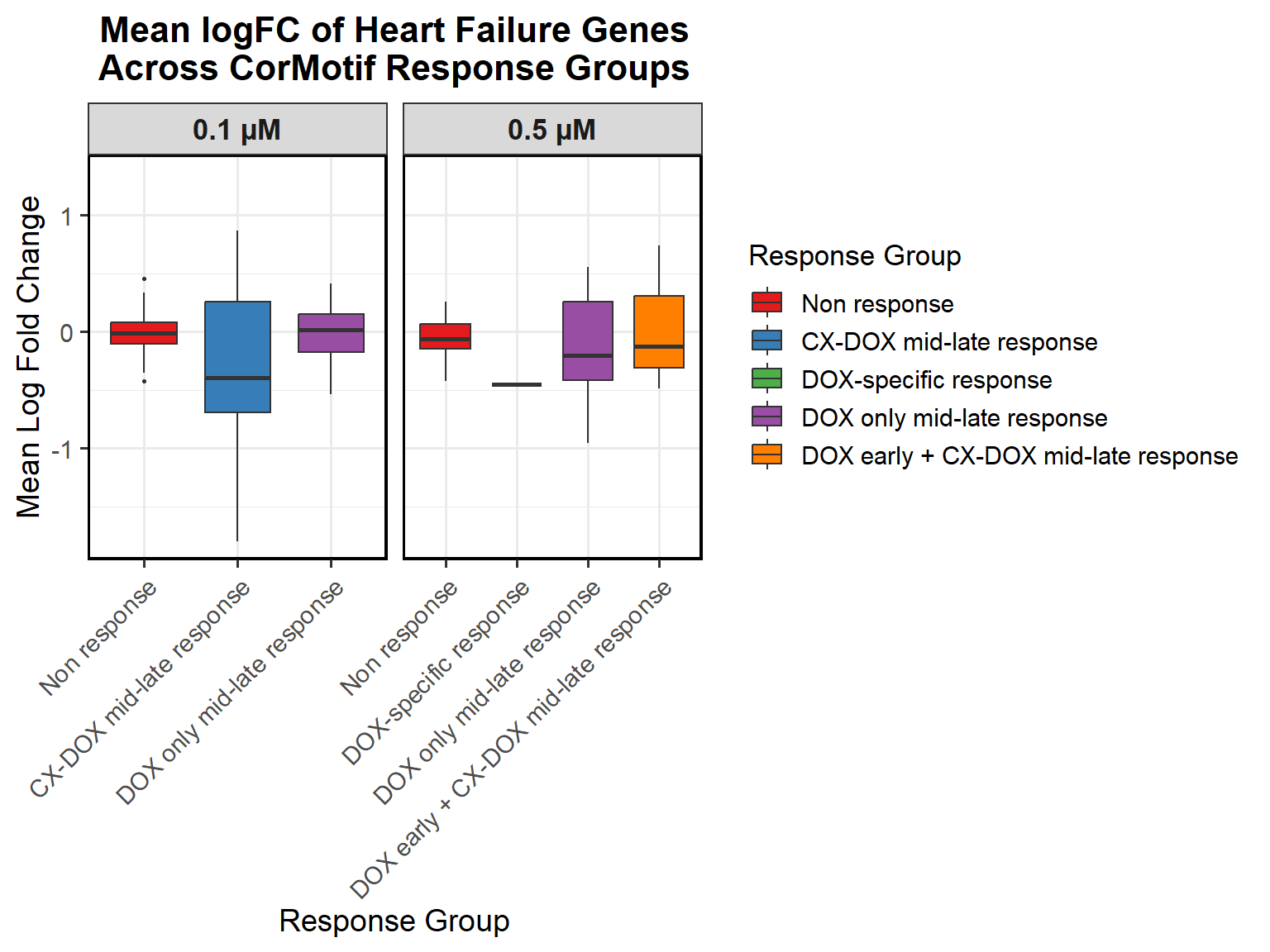
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Heart Failure GWAS genes across corrmotifs (Faceted by concentration × timepoint)
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Heart Failure Entrez IDs -----------------
entrez_ids <- c(
9709, 8882, 4023, 29959, 5496, 3992, 9415, 5308, 1026, 54437, 79068, 10221,
9031, 1187, 1952, 3705, 84722, 7273, 23293, 155382, 9531, 602, 27258, 84163,
81846, 79933, 56911, 64753, 93210, 1021, 283450, 5998, 57602, 114991, 7073,
3156, 100101267, 22996, 285025, 11080, 11124, 54810, 7531, 27241, 4774, 57794,
463, 91319, 6598, 9640, 2186, 26010, 80816, 571, 88, 51652, 64788, 90523, 2969,
7781, 80777, 10725, 23387, 817, 134728, 8842, 949, 6934, 129787, 10327, 202052,
2318, 5578, 6801, 6311, 10019, 80724, 217, 84909, 388591, 55101, 9839, 27161,
5310, 387119, 4641, 5587, 55188, 222553, 9960, 22852, 10087, 9570, 54497,
200942, 26249, 4137, 375056, 5409, 64116, 8291, 22876, 339855, 4864, 5142,
221692, 55023, 51426, 6146, 84251, 8189, 27332, 57099, 1869, 1112, 23327,
11264, 6001
) %>% as.character()
# ----------------- Load CorMotif Response Group Data -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Annotate CorMotif Group Membership -----------------
df_0.1 <- data.frame(Entrez_ID = unique(c(prob_1_0.1, prob_2_0.1, prob_3_0.1))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response"
),
Concentration = "0.1 µM"
)
df_0.5 <- data.frame(Entrez_ID = unique(c(prob_1_0.5, prob_2_0.5, prob_3_0.5, prob_4_0.5, prob_5_0.5))) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific response",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late response",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early response",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late response"
),
Concentration = "0.5 µM"
)
df_combined <- bind_rows(df_0.1, df_0.5)
# ----------------- Load DEG Files -----------------
deg_files <- list(
"CX_0.1_3" = "data/DEGs/Toptable_CX_0.1_3.csv",
"CX_0.1_24" = "data/DEGs/Toptable_CX_0.1_24.csv",
"CX_0.1_48" = "data/DEGs/Toptable_CX_0.1_48.csv",
"CX_0.5_3" = "data/DEGs/Toptable_CX_0.5_3.csv",
"CX_0.5_24" = "data/DEGs/Toptable_CX_0.5_24.csv",
"CX_0.5_48" = "data/DEGs/Toptable_CX_0.5_48.csv",
"DOX_0.1_3" = "data/DEGs/Toptable_DOX_0.1_3.csv",
"DOX_0.1_24" = "data/DEGs/Toptable_DOX_0.1_24.csv",
"DOX_0.1_48" = "data/DEGs/Toptable_DOX_0.1_48.csv",
"DOX_0.5_3" = "data/DEGs/Toptable_DOX_0.5_3.csv",
"DOX_0.5_24" = "data/DEGs/Toptable_DOX_0.5_24.csv",
"DOX_0.5_48" = "data/DEGs/Toptable_DOX_0.5_48.csv"
)
deg_all <- map2_dfr(deg_files, names(deg_files), ~{
read_csv(.x, show_col_types = FALSE) %>%
mutate(Condition = .y)
}) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Concentration = case_when(
str_detect(Condition, "0.1") ~ "0.1 µM",
str_detect(Condition, "0.5") ~ "0.5 µM"
),
Timepoint = factor(case_when(
str_detect(Condition, "_3$") ~ "3 hr",
str_detect(Condition, "_24$") ~ "24 hr",
str_detect(Condition, "_48$") ~ "48 hr"
), levels = c("3 hr", "24 hr", "48 hr"))
)
# ----------------- Merge and Annotate -----------------
hf_all <- inner_join(df_combined, deg_all, by = c("Entrez_ID", "Concentration")) %>%
filter(Entrez_ID %in% entrez_ids) %>%
mutate(
Gene = mapIds(org.Hs.eg.db, keys = Entrez_ID,
column = "SYMBOL", keytype = "ENTREZID", multiVals = "first"),
Response_Group = factor(Response_Group, levels = c(
"Non response", "CX-DOX mid-late response", "DOX-specific response",
"DOX only mid-late response", "CX total + DOX early response", "DOX early + CX-DOX mid-late response"
))
)
# ----------------- Wilcoxon Tests -----------------
comparison_groups <- levels(hf_all$Response_Group)[-1]
stat_results <- list()
for (conc in unique(hf_all$Concentration)) {
for (tp in levels(hf_all$Timepoint)) {
sub <- hf_all %>% filter(Concentration == conc, Timepoint == tp)
for (grp in comparison_groups) {
if (grp %in% unique(sub$Response_Group)) {
test <- tryCatch({
wilcox.test(
sub$logFC[sub$Response_Group == grp],
sub$logFC[sub$Response_Group == "Non response"]
)
}, error = function(e) NULL)
if (!is.null(test) && !is.nan(test$p.value)) {
stat_results[[length(stat_results) + 1]] <- data.frame(
Response_Group = grp,
Concentration = conc,
Timepoint = tp,
p_value = signif(test$p.value, 3),
label = case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
),
y_pos = max(sub$logFC[sub$Response_Group == grp], na.rm = TRUE) + 0.5
)
}
}
}
}
}
label_data <- bind_rows(stat_results) %>%
mutate(Response_Group = factor(Response_Group, levels = levels(hf_all$Response_Group)))
# ----------------- Plot -----------------
ggplot(hf_all, aes(x = Response_Group, y = logFC, fill = Response_Group)) +
geom_boxplot(outlier.size = 0.6, width = 0.7, na.rm = TRUE) +
geom_text(data = label_data, aes(x = Response_Group, y = y_pos, label = label),
inherit.aes = FALSE, size = 4, vjust = 0) +
facet_grid(rows = vars(factor(Timepoint, levels = c("3 hr", "24 hr", "48 hr"))),
cols = vars(Concentration), scales = "free_x") +
scale_fill_brewer(palette = "Set1") +
labs(
title = "Heart Failure Gene logFC by\nCorMotif Group, Timepoint, and Concentration",
x = "Response Group",
y = "logFC",
fill = "Response Group"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 14),
legend.title = element_text(size = 13),
strip.text = element_text(size = 13, face = "bold"),
panel.border = element_rect(color = "black", fill = NA, linewidth = 1.2)
)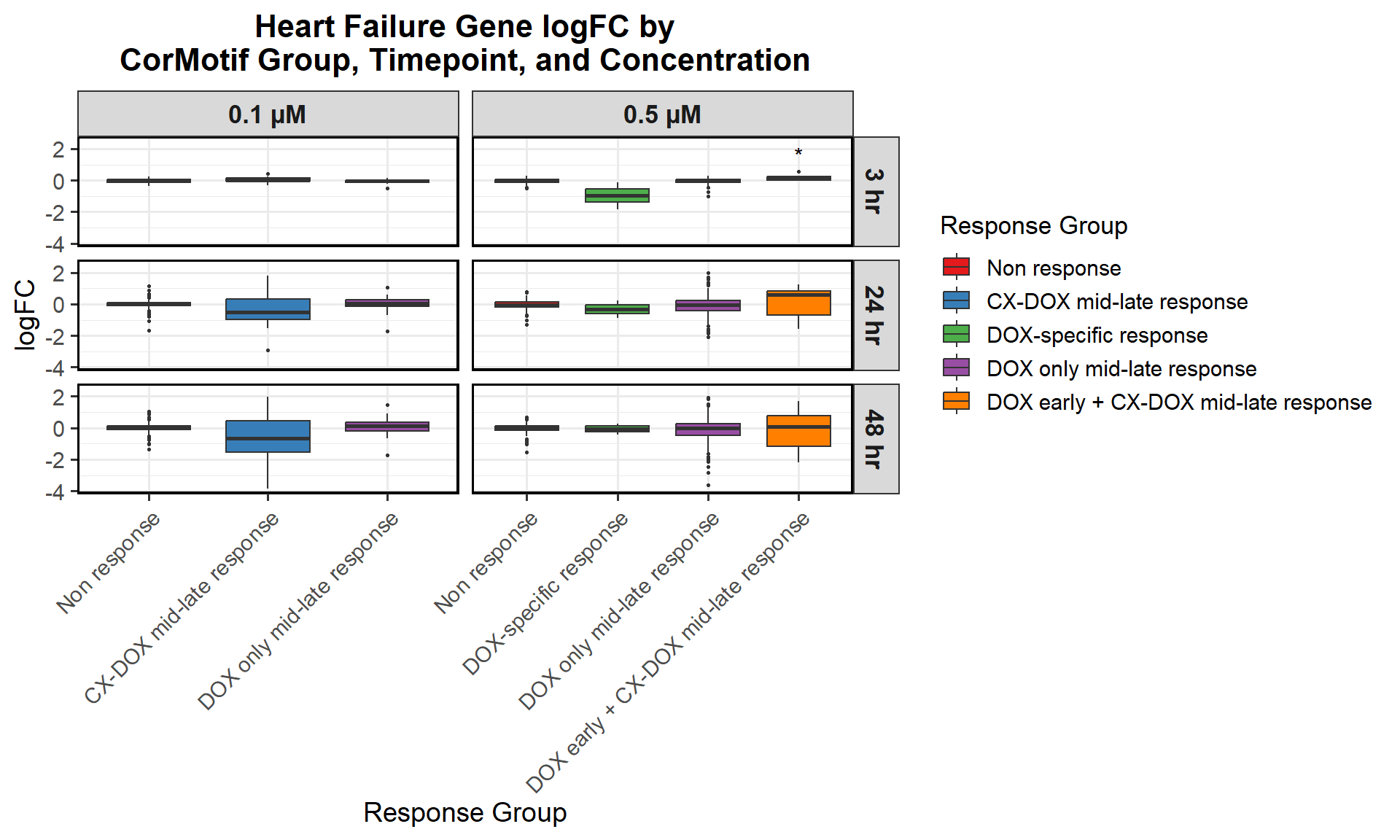
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Mean logFC of Heart Failure GWAS genes across corrmotifs (Faceted by concentration × timepoint × drug (CX vs DOX side-by-side))
############ HEART FAILURE GENES — 0.1 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Heart Failure Entrez IDs -----------------
entrez_ids <- c(
9709, 8882, 4023, 29959, 5496, 3992, 9415, 5308, 1026, 54437, 79068, 10221,
9031, 1187, 1952, 3705, 84722, 7273, 23293, 155382, 9531, 602, 27258, 84163,
81846, 79933, 56911, 64753, 93210, 1021, 283450, 5998, 57602, 114991, 7073,
3156, 100101267, 22996, 285025, 11080, 11124, 54810, 7531, 27241, 4774, 57794,
463, 91319, 6598, 9640, 2186, 26010, 80816, 571, 88, 51652, 64788, 90523, 2969,
7781, 80777, 10725, 23387, 817, 134728, 8842, 949, 6934, 129787, 10327, 202052,
2318, 5578, 6801, 6311, 10019, 80724, 217, 84909, 388591, 55101, 9839, 27161,
5310, 387119, 4641, 5587, 55188, 222553, 9960, 22852, 10087, 9570, 54497,
200942, 26249, 4137, 375056, 5409, 64116, 8291, 22876, 339855, 4864, 5142,
221692, 55023, 51426, 6146, 84251, 8189, 27332, 57099, 1869, 1112, 23327,
11264, 6001
) %>% as.character()
# ----------------- Load CorMotif Groups (0.1 µM) -----------------
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.1 µM DEG Files -----------------
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.1 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late\nresponse (0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late\nresponse (0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late\nresponse (0.1 µM)",
"DOX only mid-late\nresponse (0.1 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.1 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.1 µM HF Genes) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "Heart Failure Gene logFC by Drug and Response Group (0.1 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)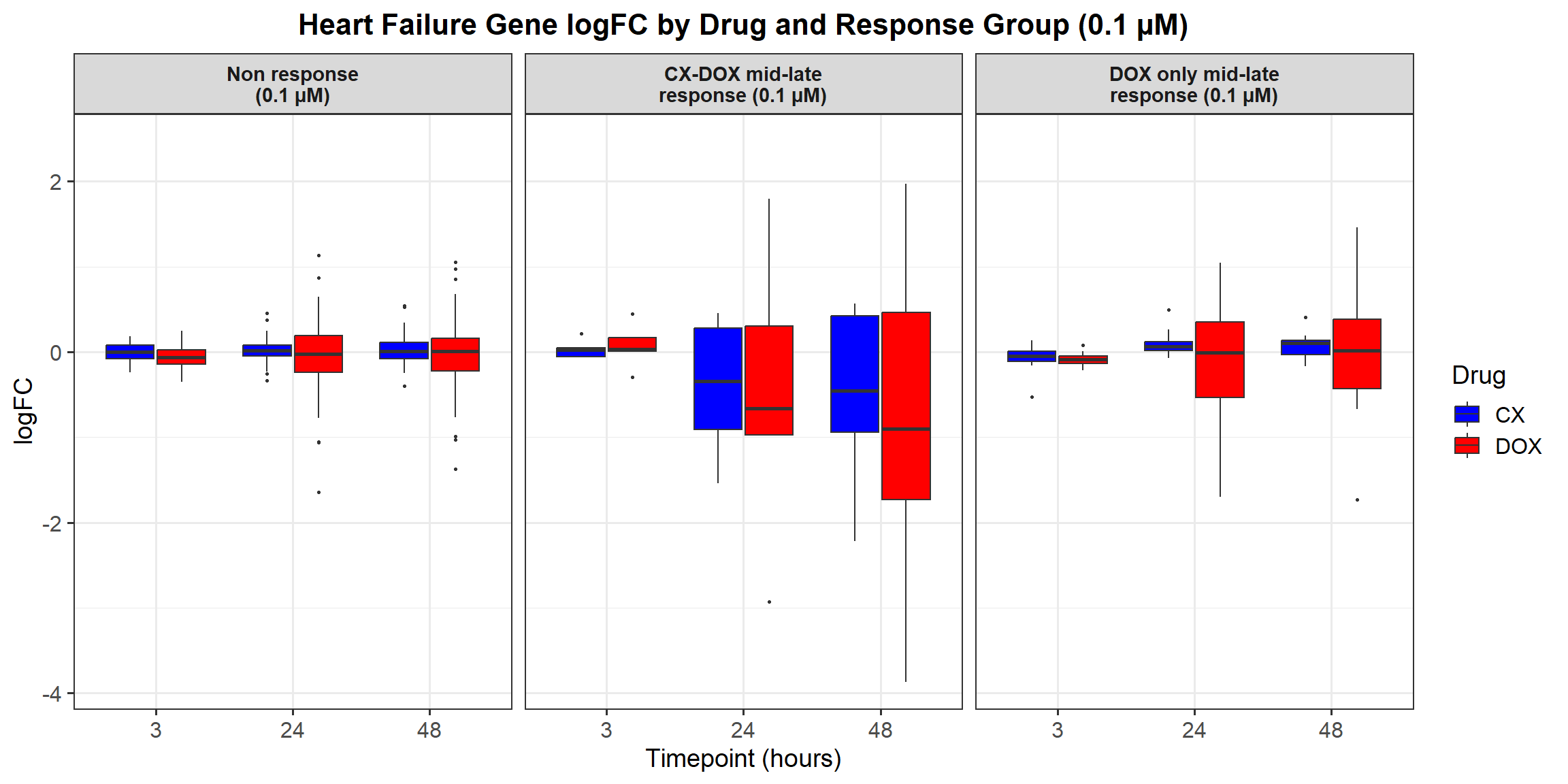
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
############ HEART FAILURE GENES — 0.5 µM #######################
# ----------------- Load Libraries -----------------
library(tidyverse)
library(org.Hs.eg.db)
library(AnnotationDbi)
# ----------------- Heart Failure Entrez IDs -----------------
entrez_ids <- c(
9709, 8882, 4023, 29959, 5496, 3992, 9415, 5308, 1026, 54437, 79068, 10221,
9031, 1187, 1952, 3705, 84722, 7273, 23293, 155382, 9531, 602, 27258, 84163,
81846, 79933, 56911, 64753, 93210, 1021, 283450, 5998, 57602, 114991, 7073,
3156, 100101267, 22996, 285025, 11080, 11124, 54810, 7531, 27241, 4774, 57794,
463, 91319, 6598, 9640, 2186, 26010, 80816, 571, 88, 51652, 64788, 90523, 2969,
7781, 80777, 10725, 23387, 817, 134728, 8842, 949, 6934, 129787, 10327, 202052,
2318, 5578, 6801, 6311, 10019, 80724, 217, 84909, 388591, 55101, 9839, 27161,
5310, 387119, 4641, 5587, 55188, 222553, 9960, 22852, 10087, 9570, 54497,
200942, 26249, 4137, 375056, 5409, 64116, 8291, 22876, 339855, 4864, 5142,
221692, 55023, 51426, 6146, 84251, 8189, 27332, 57099, 1869, 1112, 23327,
11264, 6001
) %>% as.character()
# ----------------- Load CorMotif Groups (0.5 µM) -----------------
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Helper: Load and Label DEG -----------------
load_deg <- function(file, drug, time_hr) {
read.csv(file) %>%
mutate(
Drug = drug,
Timepoint = factor(time_hr, levels = c(3, 24, 48)),
Entrez_ID = as.character(Entrez_ID)
)
}
# ----------------- Load All 0.5 µM DEG Files -----------------
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Concentration = "0.5 µM",
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX total + DOX early\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX early + CX-DOX mid-late\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group)) %>%
filter(Entrez_ID %in% entrez_ids)
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX total + DOX early\nresponse (0.5 µM)",
"DOX early + CX-DOX mid-late\nresponse (0.5 µM)"
))
)
# ----------------- Wilcoxon Test (CX and DOX separate) -----------------
wilcox_data <- deg_0.5 %>%
group_by(Drug, Timepoint) %>%
group_modify(~{
df <- .x
ref <- df %>% filter(str_detect(Response_Group, "Non response"))
other <- df %>% filter(!str_detect(Response_Group, "Non response"))
if (nrow(ref) == 0 || nrow(other) == 0) return(tibble())
map_dfr(unique(other$Response_Group), function(grp) {
g_data <- other %>% filter(Response_Group == grp)
if (nrow(g_data) > 0) {
test <- tryCatch(
wilcox.test(g_data$logFC, ref$logFC),
error = function(e) NULL
)
tibble(
Response_Group = grp,
p_value = if (!is.null(test)) signif(test$p.value, 3) else NA,
label = if (!is.null(test)) case_when(
test$p.value < 0.001 ~ "***",
test$p.value < 0.01 ~ "**",
test$p.value < 0.05 ~ "*",
TRUE ~ ""
) else "",
y_pos = max(g_data$logFC, na.rm = TRUE) + 0.5
)
} else {
tibble()
}
})
}) %>%
ungroup()
# ----------------- Final Boxplot (0.5 µM HF Genes) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(0.75), outlier.size = 0.6, width = 0.7) +
geom_text(data = wilcox_data,
aes(x = Timepoint, y = y_pos, label = label, group = Drug),
position = position_dodge(0.75),
inherit.aes = FALSE,
size = 4, vjust = 0) +
facet_grid(. ~ Response_Group, scales = "free_y") +
scale_fill_manual(values = c("CX" = "blue", "DOX" = "red")) +
labs(
title = "Heart Failure Gene logFC by Drug and Response Group (0.5 µM)",
x = "Timepoint (hours)",
y = "logFC",
fill = "Drug"
) +
theme_bw(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)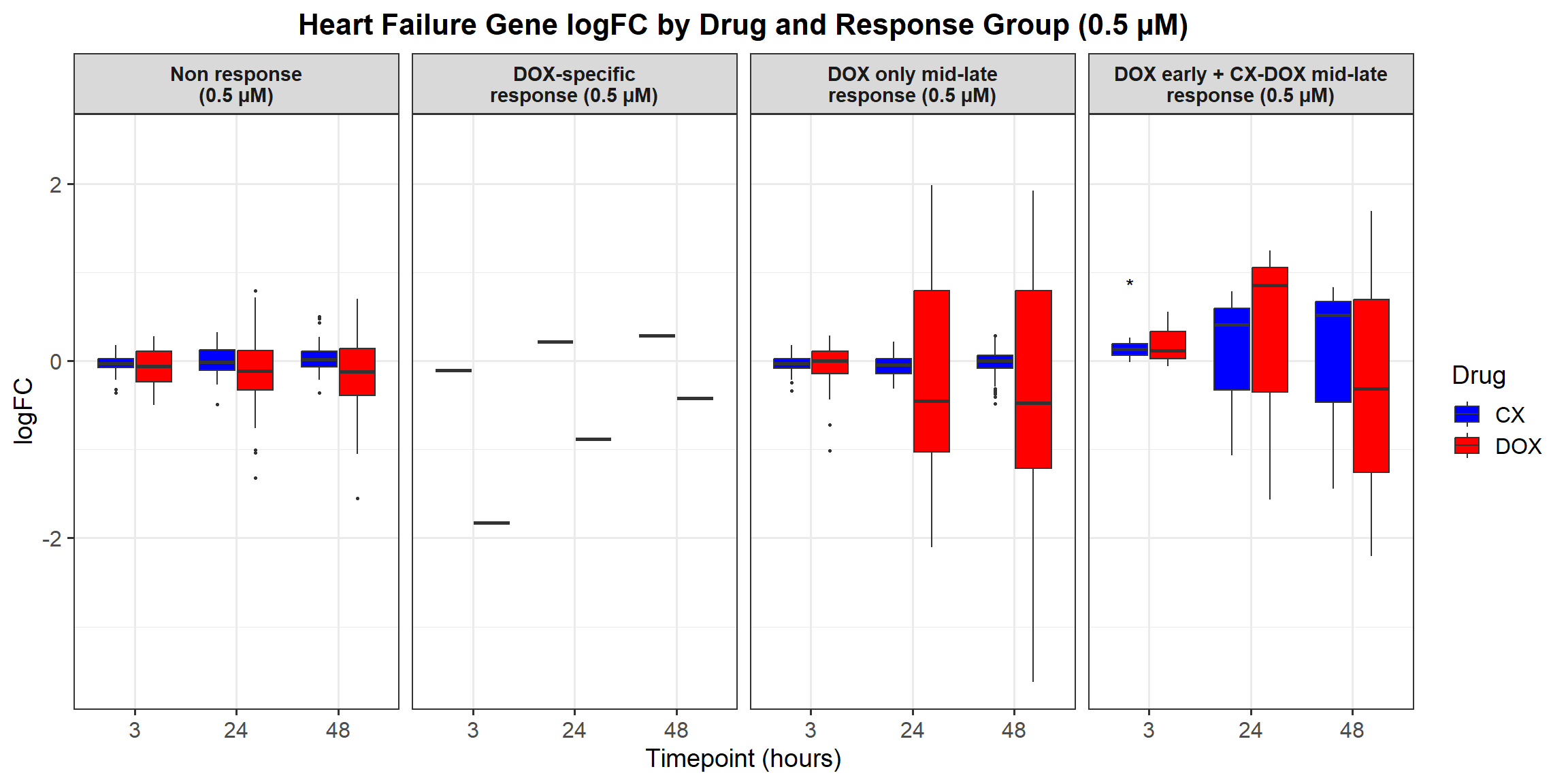
| Version | Author | Date |
|---|---|---|
| 01a423f | sayanpaul01 | 2025-05-15 |
📌 Corr-motif Boxplots
📌 Non response (0.1 micromolar)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group files
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the non-response group
target_entrez <- 92342 # Ensure this is from prob_1_0.1
# Stop if the gene is not in the non-response group
if (!(target_entrez %in% prob_1_0.1)) {
stop("Selected gene is not in the non-response group for 0.1 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTIREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.1 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.1")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.1")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) + # Only facets by Time now
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("Non response (0.1 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 CX-DOX Mid-Late Response (0.1 micromolar)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group files
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the CX-DOX mid-late response group
target_entrez <- 4521 # Replace with your desired Entrez ID from prob_2_0.1
# Stop if the gene is not in the CX-DOX mid-late response group
if (!(target_entrez %in% prob_2_0.1)) {
stop("Selected gene is not in the CX-DOX mid-late response group for 0.1 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.1 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.1")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.1")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) + # Only facets by Time
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("CX-DOX mid-late\nresponse (0.1 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)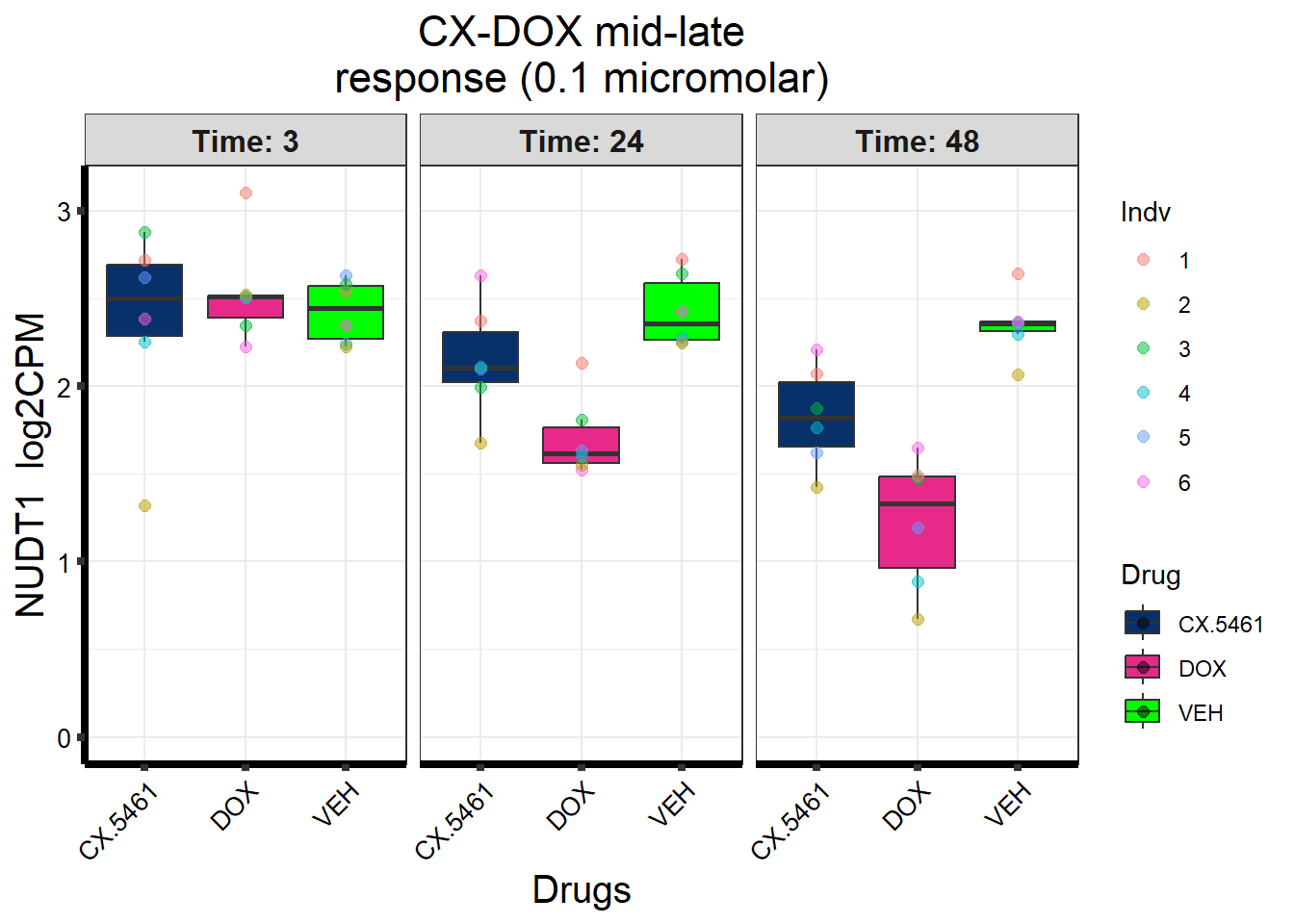
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 DOX-only mid-late response (0.1 micromolar)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group files
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the DOX-only mid-late response group
target_entrez <- 1674 # Replace with your desired Entrez ID from prob_3_0.1
# Stop if the gene is not in the DOX-only mid-late response group
if (!(target_entrez %in% prob_3_0.1)) {
stop("Selected gene is not in the DOX-only mid-late response group for 0.1 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- reshape2::melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.1 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.1")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.1")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("DOX-only mid-late\nresponse (0.1 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)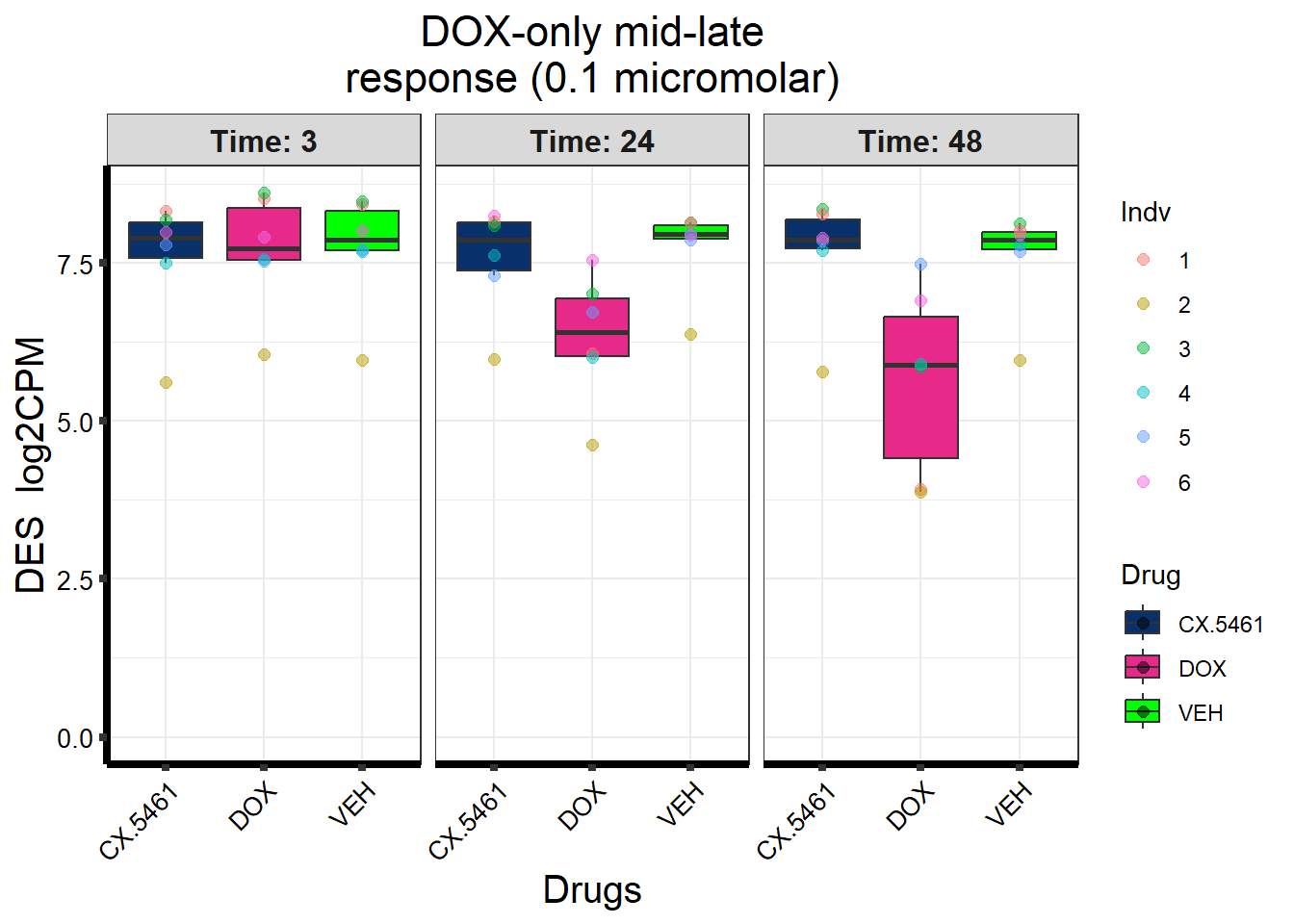
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 Non response (0.5 micromolar)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group: Non response (0.5 µM)
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the non-response group (0.5 µM)
target_entrez <- 9446 # Replace with your desired Entrez ID from prob_1_0.5
# Check if it's in the group
if (!(target_entrez %in% prob_1_0.5)) {
stop("Selected gene is not in the Non response group for 0.5 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.5 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.5")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.5")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("Non response (0.5 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)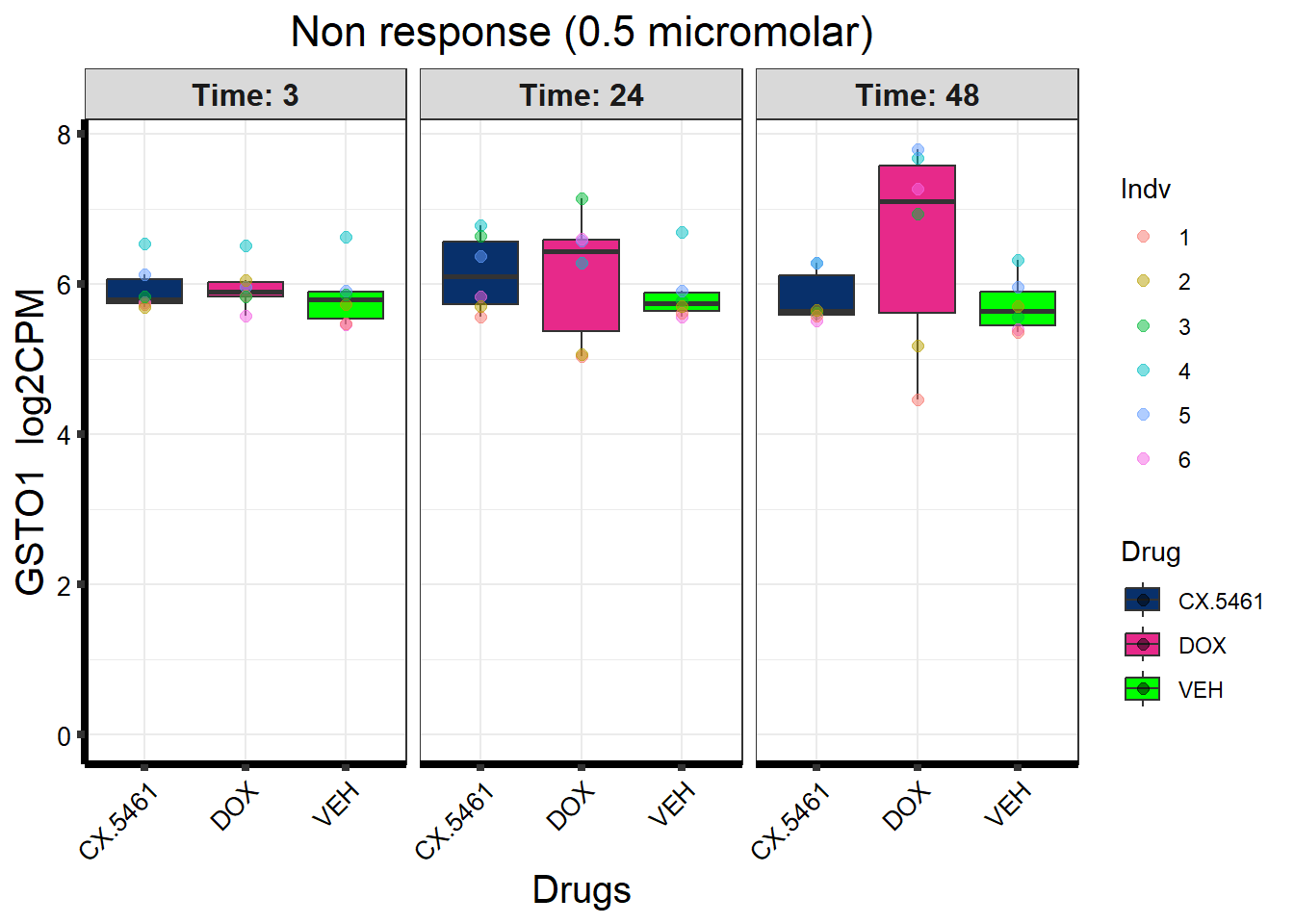
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 DOX-specific response (0.5 µM)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group: DOX-specific response (0.5 µM)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the DOX-specific response group (0.5 µM)
target_entrez <- 114821 # Replace with your desired Entrez ID from prob_2_0.5
# Check membership
if (!(target_entrez %in% prob_2_0.5)) {
stop("Selected gene is not in the DOX-specific response group for 0.5 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.5 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.5")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.5")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("DOX-specific\nresponse (0.5 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)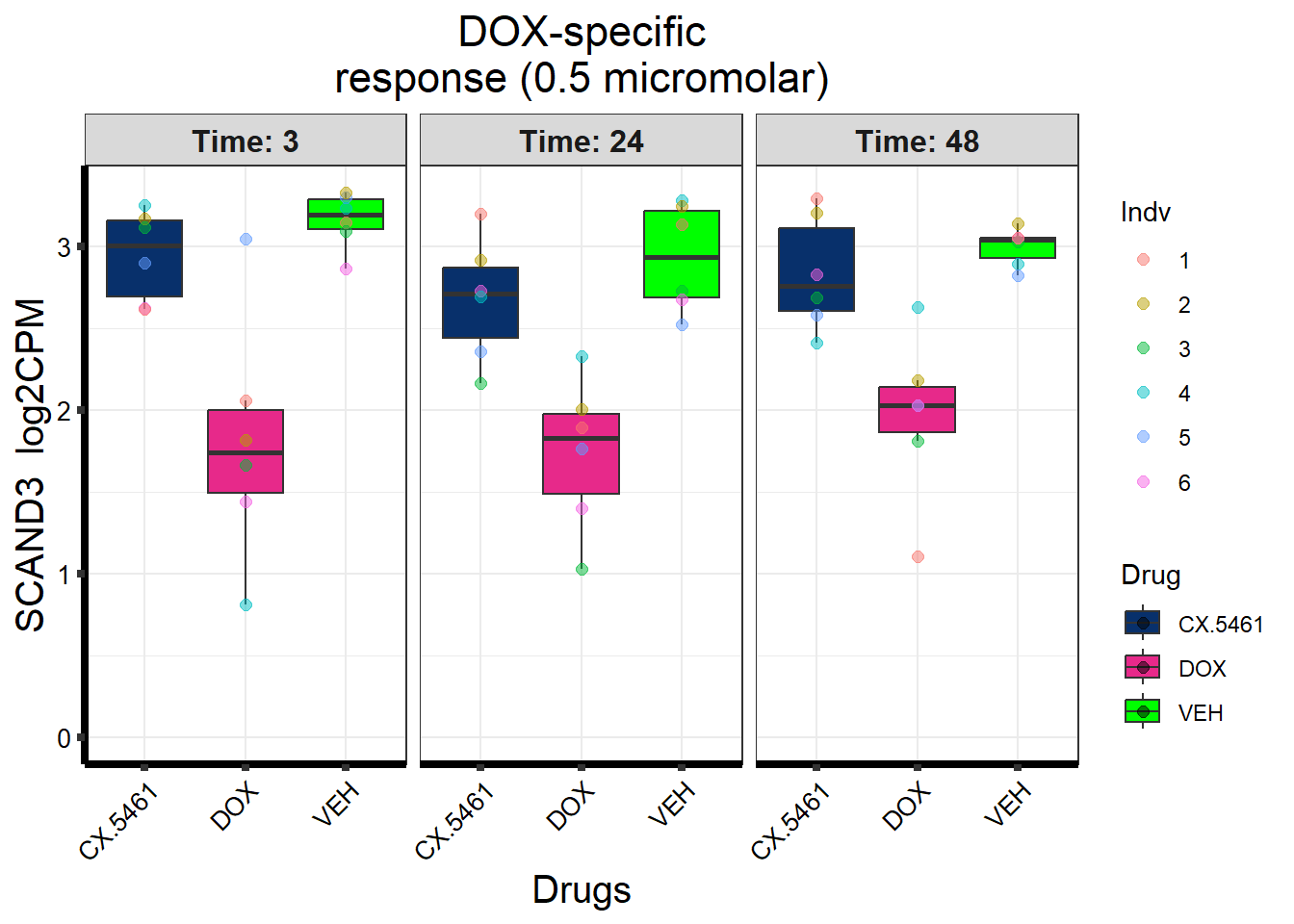
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 DOX only mid-late response (0.5 µM)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group: DOX only mid-late response (0.5 µM)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the DOX only mid-late response group (0.5 µM)
target_entrez <- 4892 # Replace with your desired Entrez ID from prob_3_0.5
# Check membership
if (!(target_entrez %in% prob_3_0.5)) {
stop("Selected gene is not in the DOX only mid-late response group for 0.5 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.5 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.5")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.5")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("DOX only mid-late\nresponse (0.5 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)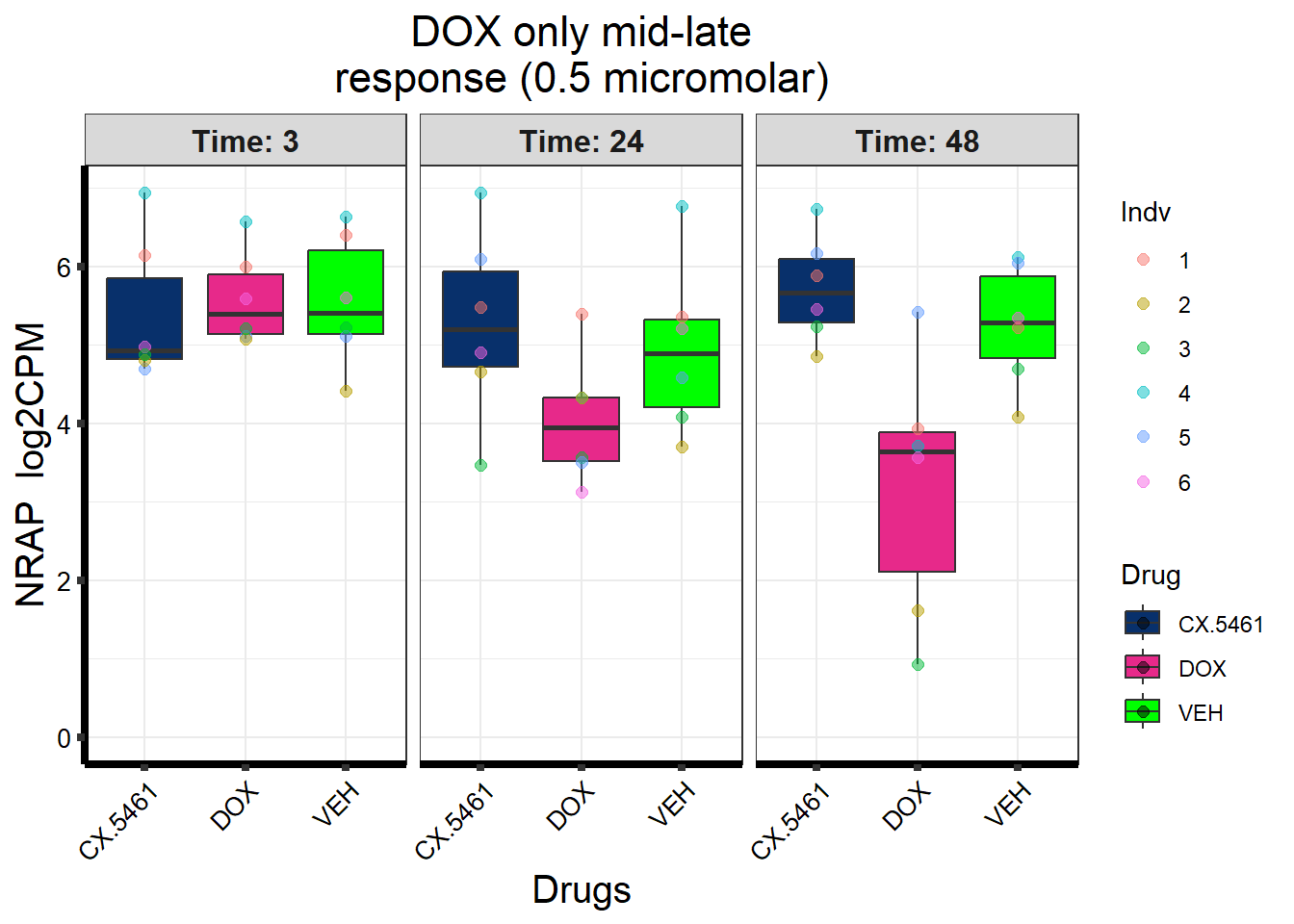
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 CX total + DOX early response (0.5 micromolar)
# ----------------- Load Libraries -----------------
library(dplyr)
library(ggplot2)
library(reshape2)
# ----------------- Load Response Group -----------------
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
# ----------------- Load Expression Dataset -----------------
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# ----------------- Choose a Target Gene -----------------
target_entrez <- 100996485 # Replace this with any valid Entrez ID from prob_4_0.5
# Check if gene is valid
if (!(target_entrez %in% prob_4_0.5)) {
stop("Selected gene is not in the CX total + DOX early response group for 0.5 micromolar.")
}
# ----------------- Filter Data for Selected Gene -----------------
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if (nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# ----------------- Reshape to Long Format -----------------
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# ----------------- Extract Metadata -----------------
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# ----------------- Filter for 0.5 µM Only -----------------
gene_data_long <- gene_data_long %>% filter(Concentration == "0.5")
# ----------------- Convert to Factors -----------------
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.5")
# ----------------- Map Individual IDs -----------------
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# ----------------- Define Drug Color Palette -----------------
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# ----------------- Extract Gene Symbol -----------------
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# ----------------- Plot -----------------
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("CX total+ DOX early\nresponse (0.5 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)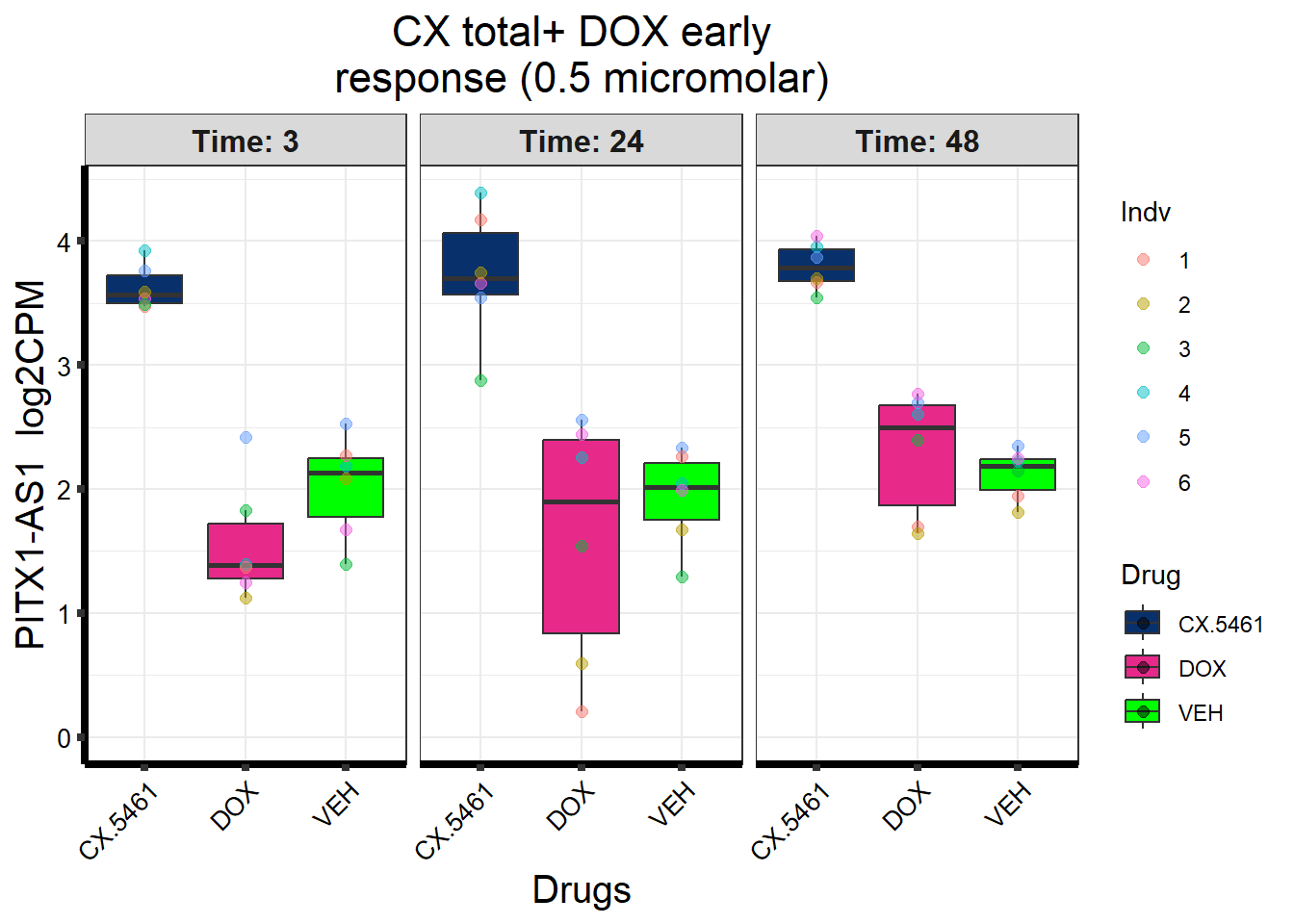
📌 DOX early + CX-DOX mid-late response (0.5 µM)
# Load libraries
library(dplyr)
library(ggplot2)
library(reshape2)
# Load response group: DOX early + CX-DOX mid-late response (0.5 µM)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# Load expression dataset
boxplot1 <- read.csv("data/boxplot1.csv", check.names = FALSE)
boxplot1 <- as.data.frame(boxplot1)
# Choose a gene from the DOX early + CX-DOX mid-late response group (0.5 µM)
target_entrez <- 672 # Replace with your desired Entrez ID from prob_5_0.5
# Check membership
if (!(target_entrez %in% prob_5_0.5)) {
stop("Selected gene is not in the DOX early + CX-DOX mid-late response group for 0.5 micromolar.")
}
# Filter for selected gene
gene_data <- boxplot1[boxplot1$ENTREZID == target_entrez, ]
if(nrow(gene_data) == 0) stop("No data found for selected ENTREZID.")
# Reshape to long format
gene_data_long <- melt(gene_data,
id.vars = c("ENTREZID", "SYMBOL", "GENENAME"),
variable.name = "Sample",
value.name = "log2CPM")
# Extract metadata from sample names
gene_data_long <- gene_data_long %>%
mutate(
Time = sub(".*_(\\d+)$", "\\1", Sample),
Concentration = sub(".*_(0\\.\\d)_\\d+$", "\\1", Sample),
Drug = sub(".*_(CX\\.5461|DOX|VEH)_.*", "\\1", Sample),
Indv = sub("^([0-9]+\\.[0-9]+)_.*", "\\1", Sample)
)
# Filter for 0.5 micromolar only
gene_data_long <- gene_data_long %>% filter(Concentration == "0.5")
# Convert to factors
gene_data_long$Time <- factor(gene_data_long$Time, levels = c("3", "24", "48"))
gene_data_long$Concentration <- factor(gene_data_long$Concentration, levels = "0.5")
# Map individual IDs
indv_mapping <- c("75.1" = "1", "78.1" = "2", "87.1" = "3",
"17.3" = "4", "84.1" = "5", "90.1" = "6")
gene_data_long <- gene_data_long %>%
mutate(Indv = ifelse(Indv %in% names(indv_mapping), indv_mapping[Indv], "Unknown"))
# Define color palette for drugs
drug_palette <- c("CX.5461" = "#08306B", "DOX" = "#E7298A", "VEH" = "green")
# Extract gene symbol for labeling
gene_symbol <- unique(gene_data_long$SYMBOL)[1]
# Create the boxplot
ggplot(gene_data_long, aes(x = Drug, y = log2CPM, fill = Drug)) +
geom_boxplot(outlier.shape = NA) +
scale_fill_manual(values = drug_palette) +
facet_grid(. ~ Time, labeller = label_both) +
geom_point(aes(color = Indv), size = 2, alpha = 0.5,
position = position_jitter(width = -0.3, height = 0)) +
ggtitle("DOX early+ CX-DOX mid-late\nresponse (0.5 micromolar)") +
labs(
x = "Drugs",
y = paste(gene_symbol, " log2CPM")
) +
ylim(0, NA) +
theme_bw() +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text.y = element_text(size = 10, color = "black"),
axis.text.x = element_text(size = 10, color = "black", angle = 45, hjust = 1),
strip.text = element_text(size = 12, face = "bold")
)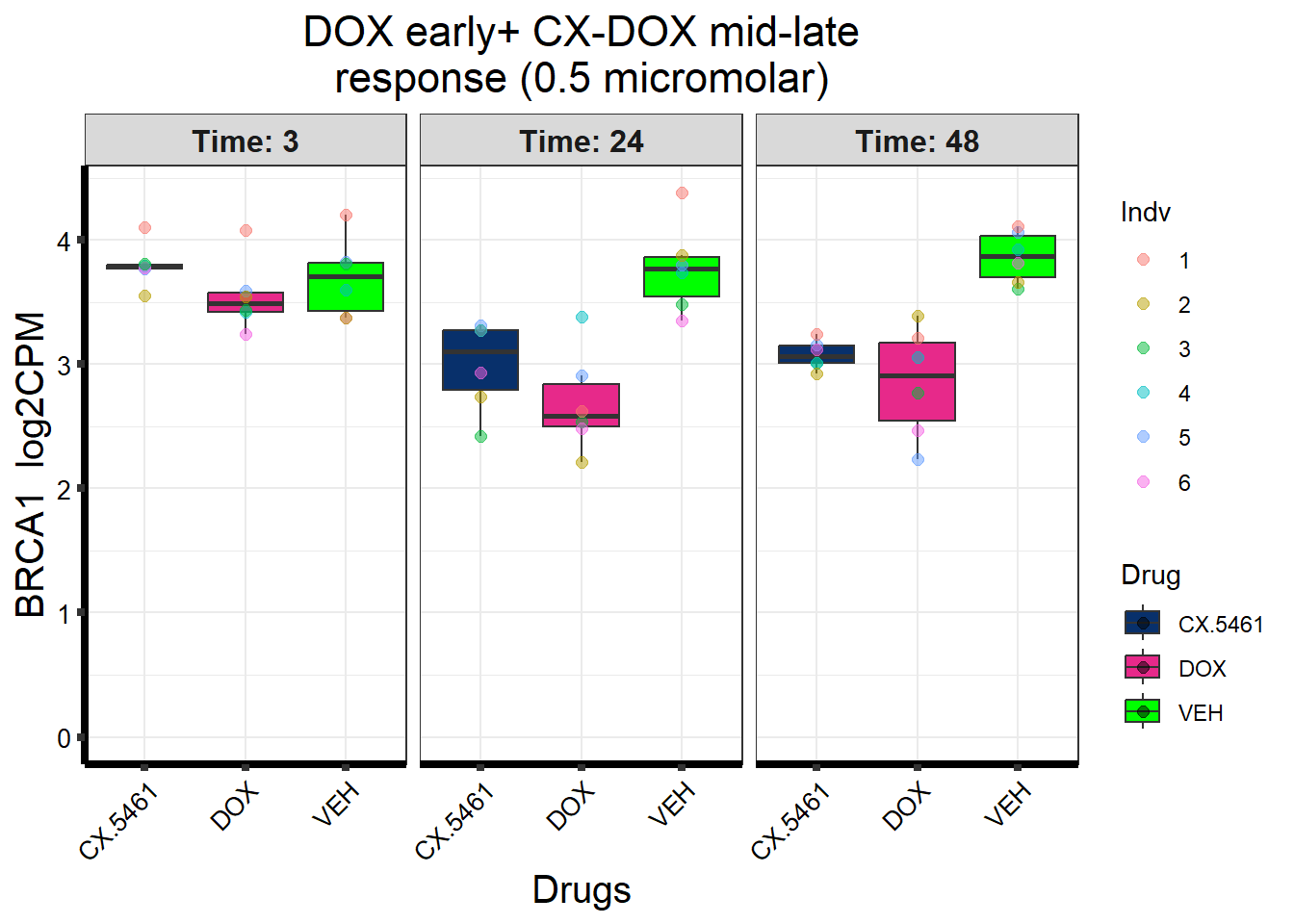
| Version | Author | Date |
|---|---|---|
| aab6b9f | sayanpaul01 | 2025-04-07 |
📌 Corrmotif conc boxplot for manuscript 0.1
# Load Required Libraries
library(dplyr)
library(ggplot2)
# ----------------- Load Response Groups -----------------
# 0.1 µM
prob_1_0.1 <- as.character(read.csv("data/prob_1_0.1.csv")$Entrez_ID)
prob_2_0.1 <- as.character(read.csv("data/prob_2_0.1.csv")$Entrez_ID)
prob_3_0.1 <- as.character(read.csv("data/prob_3_0.1.csv")$Entrez_ID)
# ----------------- Load DEG Data -----------------
# Helper function to load and label
load_deg <- function(path, drug, time) {
read.csv(path) %>%
mutate(Drug = drug, Timepoint = time)
}
# 0.1 µM DEG data
deg_0.1 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.1_3.csv", "CX.5461", 3),
load_deg("data/DEGs/Toptable_CX_0.1_24.csv", "CX.5461", 24),
load_deg("data/DEGs/Toptable_CX_0.1_48.csv", "CX.5461", 48),
load_deg("data/DEGs/Toptable_DOX_0.1_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.1_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.1_48.csv", "DOX", 48)
) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Response_Group = case_when(
Entrez_ID %in% prob_1_0.1 ~ "Non response\n(0.1 µM)",
Entrez_ID %in% prob_2_0.1 ~ "CX-DOX mid-late response\n(0.1 µM)",
Entrez_ID %in% prob_3_0.1 ~ "DOX only mid-late response\n(0.1 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# ----------------- Set Factor Levels -----------------
deg_0.1 <- deg_0.1 %>%
mutate(
Timepoint = factor(Timepoint, levels = c(3, 24, 48)),
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.1 µM)",
"CX-DOX mid-late response\n(0.1 µM)",
"DOX only mid-late response\n(0.1 µM)"
))
)
# ----------------- Plot Boxplot (Grouped by Timepoint, Faceted by Response Group) -----------------
ggplot(deg_0.1, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75)) +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) +
facet_grid(. ~ Response_Group, scales = "free_x") +
theme_bw() +
labs(
x = "Timepoint (hours)",
y = "Log Fold Change",
title = "Log Fold Change Distribution by Drug and Response Group (0.1 µM)",
fill = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)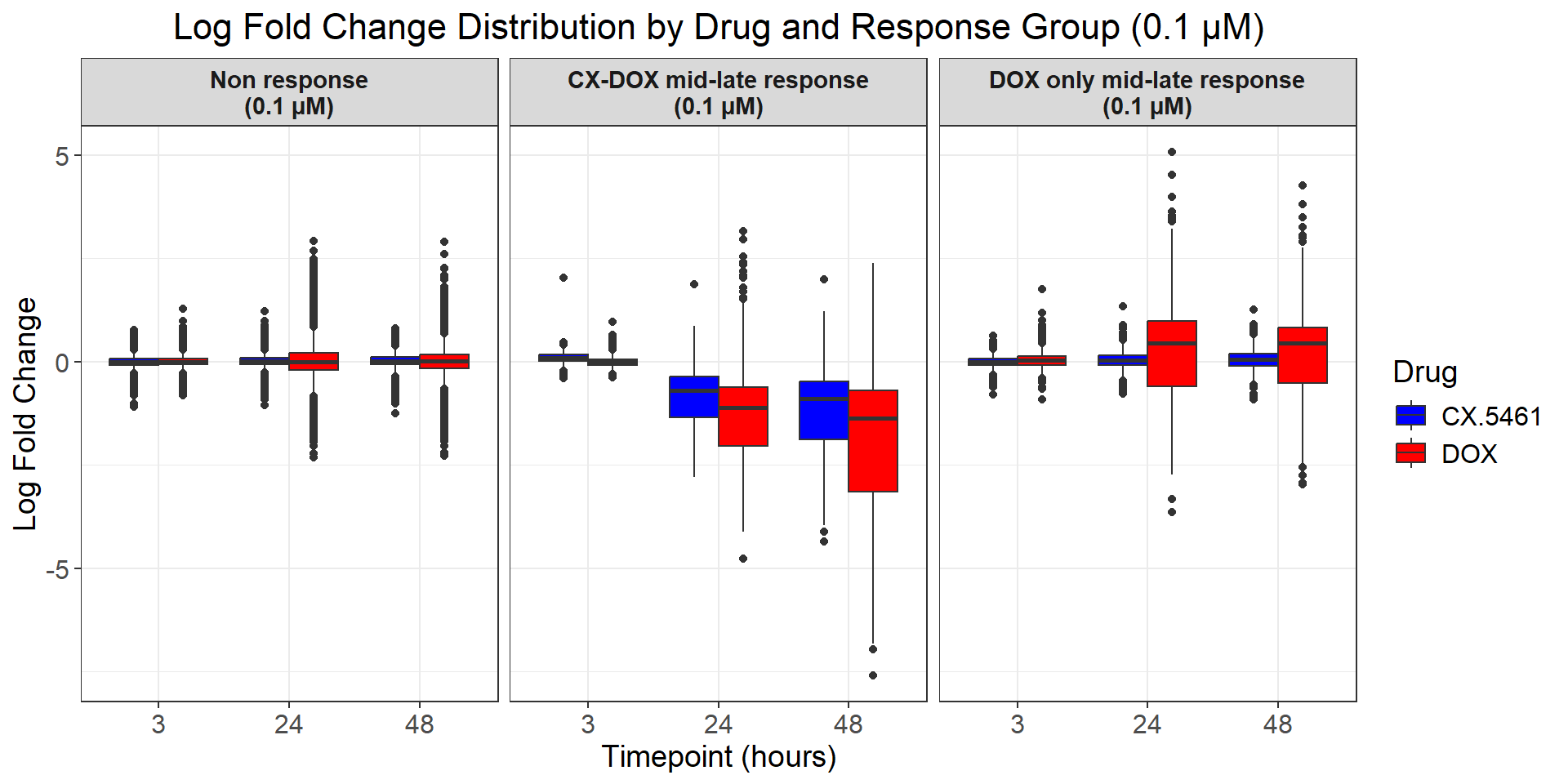
| Version | Author | Date |
|---|---|---|
| a568872 | sayanpaul01 | 2025-04-10 |
📌 Corrmotif conc boxplot for manuscript 0.5
# Load Required Libraries
library(dplyr)
library(ggplot2)
# ----------------- Load Response Groups -----------------
# 0.5 µM
prob_1_0.5 <- as.character(read.csv("data/prob_1_0.5.csv")$Entrez_ID)
prob_2_0.5 <- as.character(read.csv("data/prob_2_0.5.csv")$Entrez_ID)
prob_3_0.5 <- as.character(read.csv("data/prob_3_0.5.csv")$Entrez_ID)
prob_4_0.5 <- as.character(read.csv("data/prob_4_0.5.csv")$Entrez_ID)
prob_5_0.5 <- as.character(read.csv("data/prob_5_0.5.csv")$Entrez_ID)
# ----------------- Load DEG Data -----------------
# Helper function to load and label
load_deg <- function(path, drug, time) {
read.csv(path) %>%
mutate(Drug = drug, Timepoint = time)
}
# 0.5 µM DEG data
deg_0.5 <- bind_rows(
load_deg("data/DEGs/Toptable_CX_0.5_3.csv", "CX.5461", 3),
load_deg("data/DEGs/Toptable_CX_0.5_24.csv", "CX.5461", 24),
load_deg("data/DEGs/Toptable_CX_0.5_48.csv", "CX.5461", 48),
load_deg("data/DEGs/Toptable_DOX_0.5_3.csv", "DOX", 3),
load_deg("data/DEGs/Toptable_DOX_0.5_24.csv", "DOX", 24),
load_deg("data/DEGs/Toptable_DOX_0.5_48.csv", "DOX", 48)
) %>%
mutate(
Entrez_ID = as.character(Entrez_ID),
Response_Group = case_when(
Entrez_ID %in% prob_1_0.5 ~ "Non response\n(0.5 µM)",
Entrez_ID %in% prob_2_0.5 ~ "DOX-specific\nresponse (0.5 µM)",
Entrez_ID %in% prob_3_0.5 ~ "DOX only mid-late\nresponse (0.5 µM)",
Entrez_ID %in% prob_4_0.5 ~ "CX + DOX (early)\nresponse (0.5 µM)",
Entrez_ID %in% prob_5_0.5 ~ "DOX + CX (mid-late)\nresponse (0.5 µM)",
TRUE ~ NA_character_
)
) %>%
filter(!is.na(Response_Group))
# ----------------- Set Factor Levels -----------------
deg_0.5 <- deg_0.5 %>%
mutate(
Timepoint = factor(Timepoint, levels = c(3, 24, 48)),
Response_Group = factor(Response_Group, levels = c(
"Non response\n(0.5 µM)",
"DOX-specific\nresponse (0.5 µM)",
"DOX only mid-late\nresponse (0.5 µM)",
"CX + DOX (early)\nresponse (0.5 µM)",
"DOX + CX (mid-late)\nresponse (0.5 µM)"
))
)
# ----------------- Plot Boxplot (Grouped by Timepoint, Faceted by Response Group) -----------------
ggplot(deg_0.5, aes(x = Timepoint, y = logFC, fill = Drug)) +
geom_boxplot(position = position_dodge(width = 0.75)) +
scale_fill_manual(values = c("CX.5461" = "blue", "DOX" = "red")) +
facet_grid(. ~ Response_Group, scales = "free_x") +
theme_bw() +
labs(
x = "Timepoint (hours)",
y = "Log Fold Change",
title = "Log Fold Change Distribution by Drug and Response Group (0.5 µM)",
fill = "Drug"
) +
theme(
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
strip.text = element_text(size = 11, face = "bold"),
legend.title = element_text(size = 14),
legend.text = element_text(size = 12)
)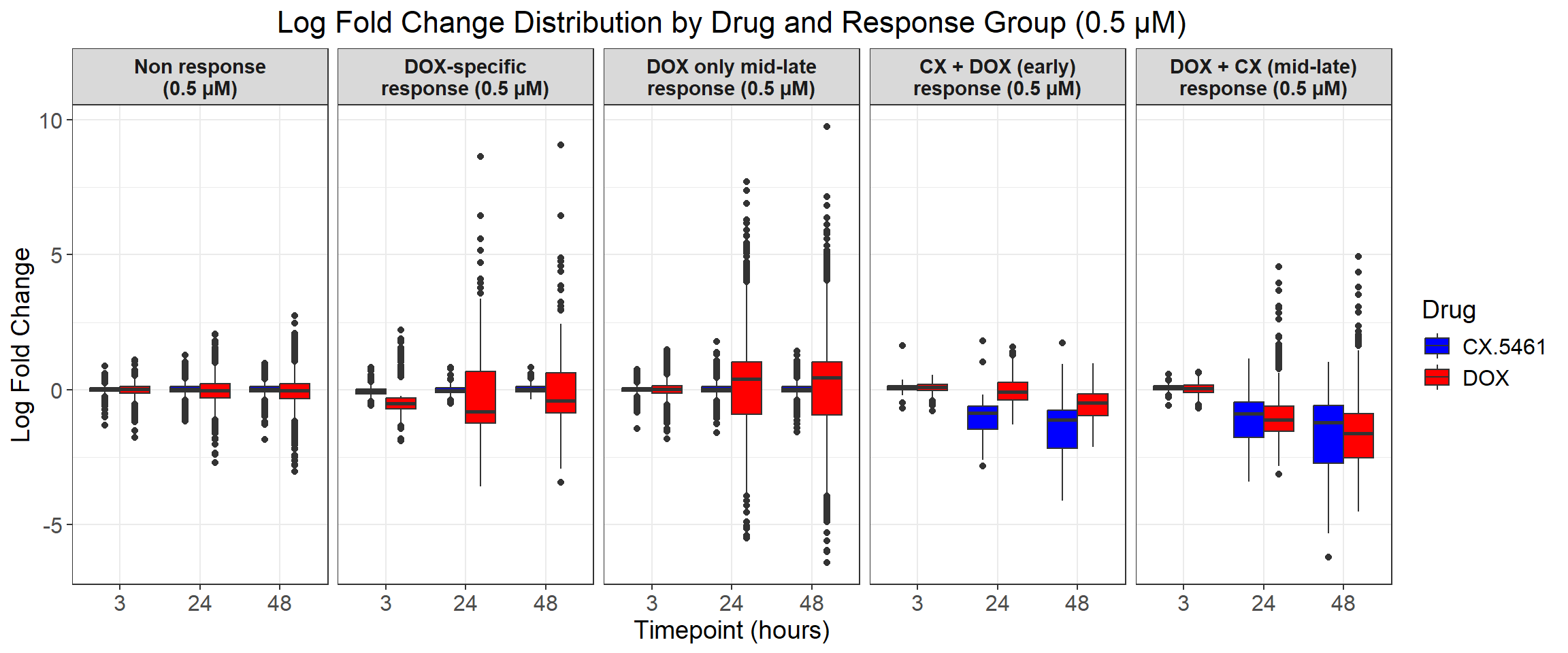
| Version | Author | Date |
|---|---|---|
| a568872 | sayanpaul01 | 2025-04-10 |
sessionInfo()R version 4.3.0 (2023-04-21 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] reshape2_1.4.4 lubridate_1.9.4 forcats_1.0.0
[4] stringr_1.5.1 purrr_1.0.4 readr_2.1.5
[7] tibble_3.2.1 tidyverse_2.0.0 org.Hs.eg.db_3.18.0
[10] AnnotationDbi_1.64.1 IRanges_2.36.0 S4Vectors_0.40.2
[13] tidyr_1.3.1 ggplot2_3.5.2 gprofiler2_0.2.3
[16] BiocParallel_1.36.0 dplyr_1.1.4 Rfast_2.1.5.1
[19] RcppParallel_5.1.10 zigg_0.0.2 Rcpp_1.0.12
[22] Cormotif_1.48.0 limma_3.58.1 affy_1.80.0
[25] Biobase_2.62.0 BiocGenerics_0.48.1 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] DBI_1.2.3 bitops_1.0-9 rlang_1.1.3
[4] magrittr_2.0.3 git2r_0.36.2 compiler_4.3.0
[7] RSQLite_2.3.9 getPass_0.2-4 png_0.1-8
[10] callr_3.7.6 vctrs_0.6.5 pkgconfig_2.0.3
[13] crayon_1.5.3 fastmap_1.2.0 XVector_0.42.0
[16] labeling_0.4.3 promises_1.3.2 rmarkdown_2.29
[19] tzdb_0.5.0 ps_1.8.1 preprocessCore_1.64.0
[22] bit_4.6.0 xfun_0.52 zlibbioc_1.48.2
[25] cachem_1.1.0 GenomeInfoDb_1.38.8 jsonlite_2.0.0
[28] blob_1.2.4 later_1.3.2 parallel_4.3.0
[31] R6_2.6.1 RColorBrewer_1.1-3 bslib_0.9.0
[34] stringi_1.8.3 jquerylib_0.1.4 knitr_1.50
[37] timechange_0.3.0 httpuv_1.6.15 tidyselect_1.2.1
[40] rstudioapi_0.17.1 yaml_2.3.10 codetools_0.2-20
[43] processx_3.8.6 plyr_1.8.9 withr_3.0.2
[46] KEGGREST_1.42.0 evaluate_1.0.3 Biostrings_2.70.3
[49] pillar_1.10.2 affyio_1.72.0 BiocManager_1.30.25
[52] whisker_0.4.1 plotly_4.10.4 generics_0.1.3
[55] vroom_1.6.5 rprojroot_2.0.4 RCurl_1.98-1.17
[58] hms_1.1.3 munsell_0.5.1 scales_1.3.0
[61] glue_1.7.0 lazyeval_0.2.2 tools_4.3.0
[64] data.table_1.17.0 fs_1.6.3 grid_4.3.0
[67] colorspace_2.1-0 GenomeInfoDbData_1.2.11 cli_3.6.1
[70] viridisLite_0.4.2 gtable_0.3.6 sass_0.4.10
[73] digest_0.6.34 htmlwidgets_1.6.4 farver_2.1.2
[76] memoise_2.0.1 htmltools_0.5.8.1 lifecycle_1.0.4
[79] httr_1.4.7 statmod_1.5.0 bit64_4.6.0-1